
Introduction
- 본 글은 Managed Airflow Server 환경을 사업 모델로 삼은 Astronomer 유튜브 강좌에 기반.
- Apache Airflow 란 데이터 파이프라인 관리를 위한 오픈소스 툴이다. ‘14년 Airbnb 에서 사내 프로젝트로 시작한 후, 오픈소싱을 통해 ‘19년 Apache Software Foundation 에서 탑레벨 프로젝트로 선정.
- 전세계적으로 백만명 이상의 데이터 엔지니어가 데이터 파이프라인 관리를 위해 활용하고 있음.
- 2020년 Airflow 2.0 가 공개됨.
Use Cases
- ETL/ELT Pipelines : Snowflake 등 DW 에 데이터 적재 - Orchestrating Snowflake Queries with Airflow
- MLOps : Tensorflow 와 MLFlow 를 활용해 MLOps 서비스 구축 - Using Airflow with Tensorflow and MLFlow
- Operationalized Analytics : 데이터 추출, 가공을 통해 대시보드 전달 - Using Airflow as a Data Analyst
Core Concepts
Airflow 의 작업 단위는 DAG, Task 로 구분 가능하다.
- DAG : Directed Acyclic Graph. 그래프 형태로 표현된 워크플로우이며, 노드 간 디펜던시는 방향성을 가지게 된다 - Introduction to Airflow DAGs.
- DAG run : 시간 특정이 가능한 DAG 실행 건. 스케줄링이나 매뉴얼 트리거가 가능하다.
- Task : DAG 내 개별 작업 단위.
- Task instance : 시간 특정이 가능한 Task 실행 건.
DAG 작성 시 특정 작업을 수행하는 Operator 를 활용하게 되며, Operator 는 파라미터를 받아 실행되는 함수의 형태를 취한다. DAG 내 각 Operator 는 Task 와 같은 단위 - Operators 101.
- Action Operators : 함수 실행. PythonOperator, BashOperator 등.
- Transfer Operators : 소스로 부터 타겟까지 데이터를 이동. S3ToRedshiftOperator 등.
- Sensors : 특정 이벤트가 발생할때까지 대기. ExternalTaskSensor, HttpSensorAsync 등.
Operator 간 데이터 전송이 필요한 경우 XComs 를 활용.
Components
Airflow 의 효율적인 활용을 위해선 인프라 구성에 대한 이해가 필요하다. 이슈 대응 및 DAG 개발 시 구조에 대한 이해가 필요한 상황이 발생할 수 있음.
- Webserver : Airflow UI 서빙을 위해 Flask 서버가 Gunicorn 을 통해 구동.
- Scheduler : 잡스케줄링을 위한 Daemon.
- Database : Task Metadata 저장소. 보통 PostgreSQL 활용.
- Executor : Task 수행을 위한 연산 자원 배분. Scheduler 내에서 구동된다.
High-Level Best Practices
멱등성 (Idempotency)
- 멱등성 (Idempotency) : 특정 Operation 을 여러번 실행하더라도 최종 결과는 변형되지 않는다.
- 예시로 횡단보도를 건너기 위해 누르는 버튼을 들 수 있다 (미국식). 버튼을 여러번 누르더라도, 일정 기간 동안 파란불이 켜지는 결과는 변동하지 않음.
- Idempotent DAG 는 에러 발생 시 빠른 처리를 가능하게 하고, 데이터 유실을 예방하는 효과를 가진다.
Airflow as an Orchestrator
- Airflow 는 본래의 취지에 충실하게 실행 관점이 아닌, 자동화/관리 (orchestration) 관점에서 접근하는 것이 권장된다.
- 실무적인 관점에서, 다음과 같은 시사점을 가짐 :
- Airflow 를 활용해 여러 툴을 활용한 job 을 관리할 것
- 연산 자원이 많이 필요한 경우 Spark 와 같은 execution framework 로 작업 인계
- 가능한 경우 ELT 프레임워크 활용 (Snowflake 와 같이 DW 상의 연산 자원 활용)
- 데이터 처리 과정에서 중간 데이터 저장소를 최대한 활용할 것. XCom 등의 기능을 활용해 용량이 큰 데이터프레임을 가공하는 등의 방법은 비권장.
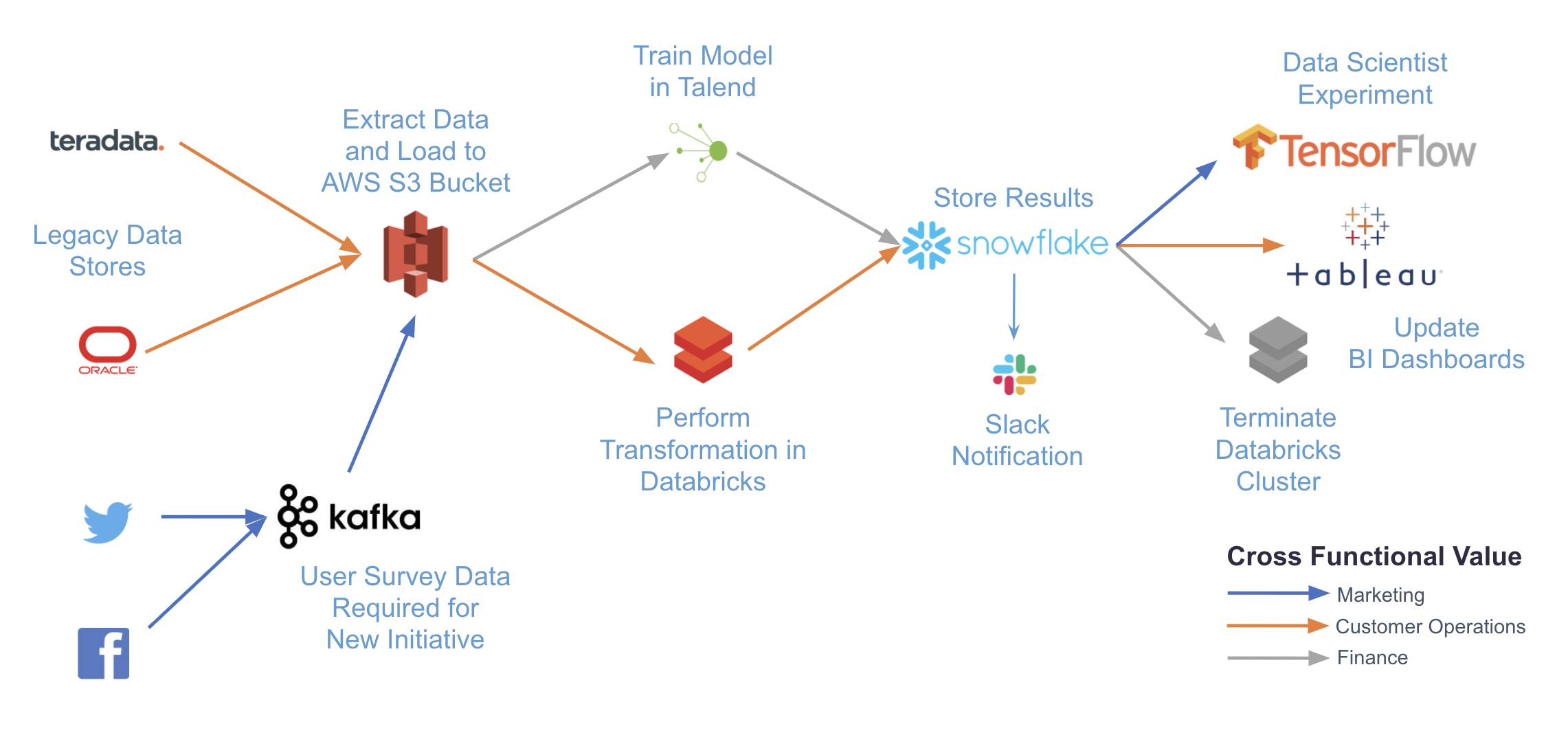 |
|---|
| Fig 1. Airflow 를 활용한 Data Orchestration 예시 |
Keep Tasks Atomic
- 하나의 Task 는 하나의 작업만을 수행해야 하며, 다른 Task 와 무관하게 재실행이 가능해야 한다.
- Atomized Task 의 부분 성공은 즉 전체 Task 의 성공을 의미해야함.
- 예를 들어 ETL Pipeline 구축 시 각각 Extract, Transform, Load 에 해당하는 Task 3개를 정의. 각 Task 의 재실행이 가능하기 때문에, idempotence 가 보장된다.
Incremental Record Filtering
- 가능한 경우 ETL, ELT 파이프라인 작성 시 항상 전체 데이터를 처리하는 것 보다는, 순차적으로 처리하는 편이 좋다.
- 예) 시간 마다 배치가 실행되는 경우 전체 데이터셋을 처리하기 보다 마지막 시간에 발생한 데이터만 처리.
- 데이터 유실을 방지하거나, 처리 속도를 향상하는데 많은 도움을 줄 수 있음.
- 원천 데이터가 항상 변동하는 경우 과거 결과값을 유지할 수 있으며, 이는 Idempotency 와 연계되는 부분.
Last Modified Date vs. Sequence IDs
- Incremental loading 을 위해 가장 권장되는 방법은 마지막 수정일자 (Last Modified Date) 필드 활용이다.
- 수정일자 필드 활용이 불가능한 경우, 순차적으로 증가하는 ID 필드를 활용하는 것 또한 가능하다. 이 경우 스케줄러가 기존 데이터셋을 업데이트 하지 않고, 새로운 데이터를 붙여넣는 경우가 가장 이상적.
 |
|---|
| Fig 2. Incremental Record Filtering |
Airflow Variables & Macros
- Airflow 는 기본적으로 jinja templating 을 활용한 자체 변수와 매크로를 제공하며, 작업 효율성을 위해 이를 최대한 이용하는 것이 좋다 - Readability, idempotency, maintainability 등에서 많은 장점 제공.
Airflow Variables 예시
| Variable | Type | Description |
|---|---|---|
| {{ data_interval_start }} | pendulum.DateTime | Start of the data interval. Added in version 2.2. |
| {{ data_interval_end }} | pendulum.DateTime | End of the data interval. Added in version 2.2. |
| {{ ds }} | str | The DAG run’s logical date as YYYY-MM-DD. Same as {{ dag_run.logical_date | ds }}. |
| {{ ds_nodash }} | str | Same as {{ dag_run.logical_date | ds_nodash }}. |
| {{ ts }} | str | Same as {{ dag_run.logical_date | ts }}. Example: 2018-01-01T00:00:00+00:00. |
Airflow Macros 예시
| Variable | Description |
|---|---|
| macros.datetime | The standard lib’s datetime.datetime |
| macros.timedelta | The standard lib’s datetime.timedelta |
| macros.dateutil | A reference to the dateutil package |
| macros.time | The standard lib’s time |
| macros.uuid | The standard lib’s uuid |
| macros.random | The standard lib’s random.random |
예시로 다음과 같이 datetime 패키지를 활용하는 경우, Airflow 변수로 기능을 대체할 수 있다.
|
|
Avoid Top Level Code in DAG
- Top Level Code 란 DAG 혹은 Operator 정의 이외 용도의 코드를 의미하며, 이러한 코드를 DAG 에 포함시키지 않도록 주의해야 한다 (특히 외부 시스템에 대한 request).
- 이러한 부분에 부주의할 시 연산 부담, 코드 가독성 등에서 많이 제약 사항이 발생할 수 있음.
- 다음 예시는 다른 DB 에서 수집한 정보를 기반으로 PostgresOperator 를 생성하는 DAG 작성의 Bad Practice 와 Good Practice 를 나열한다.
Bad Practice 의 경우 Operator 정의 바깥 부분에서 DB 커넥션을 만들었고, 이에 따라 실제 DAG 가 수행되지 않더라도 자원을 소모할 여지가 있다.
|
|
반면 Good Practice 예시에선 해당 DB 커넥션을 만드는 Task 를 별도 생성하였고, 이에 따라 실제 DAG 가 실행되지 않는 이상 자원을 소모하지 않게됨.
|
|
이외에도 파이썬 함수, SQL 쿼리문을 외부 파일에 저장하는 등, DAG 파일을 일종의 Config 파일과 같이 깔끔하게 유지해 주어야한다 (향후 유지보수가 훨씬 원활).
Consistent Method for Task Dependencies
- Airflow 상에서 Task Dependencies 를 정의하는 방법은 크게 set_upstream(), set_downstream() 함수 활용과 «, » 오퍼레이터 활용 방식으로 구분할 수 있다.
- 특정 방식이 권장되는 것은 아니나, 정의 방법을 전반적으로 통일해주어야 코드 가독성을 높일 수 있음.
Leverage Airflow Features
Provider Packages
- Airflow 가 사실상 표준 프레임워크로 자리잡았기 때문에, 이외 툴과 연계 활용을 위한 써드파티 Provider Packages 가 매우 다양하게 공개되어있다 (GCP, AWS, Databricks 등).
- 가능한 경우, 함수를 직접 정의하기 보다는 이러한 provider package 를 최대한 활용하는 편이 유지보수와 공수 최수화 관점에서 권장.
- 다양한 provider package 는 다음 링크에서 확인 가능 - Astronomer Provider Packages Registry
Where to Run Jobs
- Airflow 는 자체적으로 중소 규모의 data processing task 를 처리할 수 있지만, 연산 자원이 아주 많이 필요한 경우 Apache Spark 와 같은 대규모 데이터 처리 프레임워크에 작업을 인계하여야 함 - Apache Spark Operators.
- DAG 를 작성하는 과정에서 Airflow 가 자체적으로 데이터를 처리하는 경우, 이에 필요한 연산 자원이 구비되었는지 확인이 반드시 필요하다.
- Task 레벨에서 연산 자원을 유동적으로 활용하기 위해서 Kubernetes Executor 활용이 가능.
Intermediary Data Storage
- 소스 -> 타겟으로 직접 데이터를 이동하는 것은 코드 작성이 적기 때문에 괜찮은 방법으로 보일 수 있다. 하지만 ETL 프로세스의 중간 과정을 모니터링 하는 것이 불가능하기 때문에, S3 나 SQL Staging 테이블과 같은 중간 저장소를 활용하는 것이 권장.
- API Limit 이 발생하는 상황에서 유용하게 활용할 수 있음.
Other Best Practices
Consistent File Structure
- 일정한 파일 구조를 유지하는 것이 유지보수 측면에서 많은 도움이 됨.
|
|
DAG Name & Start Date
- DAG 의 시작 날짜(start_date)는 static 하게 유지되어야 한다.
- 시작 날짜를 변경할 경우 새로운 DAG 이름을 부여해주어야 함. 시작 날짜 변경 시 Airflow database 는 이를 새로운 DAG 로 인식하는데, DAG 이름이 동일하다면 Scheduler 에러 발생 위험이 발생.
Retries
- Airflow 가 분산처리 시스템과 연계된 경우, 예기치 못하게 task 가 멈추는 현상이 발생할 가능성이 높다 (유지되는 host 수가 많기 때문).
- 시스템 에러에 대비해 최소 2회 정도 retry 설정을 하는 것이 권장된다 (분산처리 과정에서 발생하는 대부분의 에러에 대응 가능한 숫자).
- 다음과 같은 레벨에서 retry 설정이 가능하다 :
- Tasks : Operator 의 retries 파라미터 조정
- DAGS : DAG 의 default_args 오브젝트에 retries 포함
- Deployments : AIRFLOW__CORE__DEFAULT_TASK_RETRIES 환경변수 지정