
Introduction
- “레이크하우스” 라는 키워드와 함께 국내 기업 환경에서도 자주 접할 수 있는 회사인 Databricks 는, 본질적으로는 Spark 와 분산형 저장소 (DBFS) 를 별다른 인프라 세팅 없이 바로 활용할 수 있는 관리형 서비스 (Managed Service) 이다.
- 실제 아파치 스파크를 개발한 UC 버클리 AMP 연구소의 개발자들이 창업하였고, 스파크뿐만 아니라 Delta Lake, MLFlow 와 같은 오픈소스 SW를 개발 및 인수했다.
- 현재 Databricks Cloud Service 는 주요 클라우드 3사에서 모두 사용이 가능하다 - [Azure][AWS][GCP].
- 본 글에서는 Databricks의 서비스와 주요개념을 간단하게 짚어보고자 한다.
EMR, Dataproc
- Databricks 와 같은 래퍼 서비스를 활용하지 않더라도, 주요 클라우드 업체의 자체 서비스를 활용한 분산 처리 환경 구성이 가능하다.
- Managed Spark & Hadoop 서비스의 대표적인 예시로는 AWS EMR, GCP Dataproc 을 들 수 있다.
AWS EMR
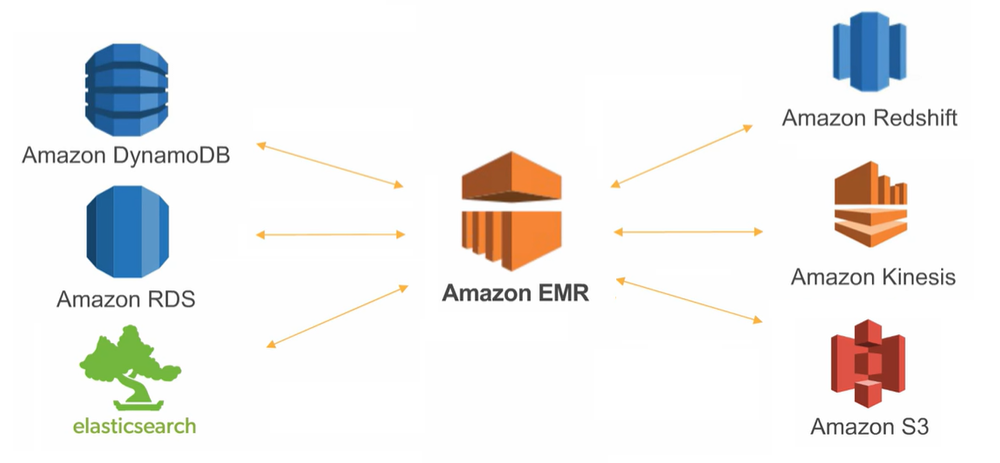 |
|---|
| Fig 1. Zuar - What is Amazon EMR? |
- Amazon EMR (Elastic Map Reduce) 는 대용량 데이터 분산 처리를 위한 AWS 서비스이며, 유사한 서비스이나 서버리스 환경을 제공하는 AWS Glue 와 달리 클러스터 수 등을 직접 조절해야 한다.
- EC2 인스턴스를 이용해 Spark, Hadoop 클러스터를 몇분내에 생성할 수 있다. 또한 스토리지로 활용될 S3와 연결을 위한 EMRFS (EMR File System) 을 지원.
- 참고를 위한 링크 :
GCP Dataproc
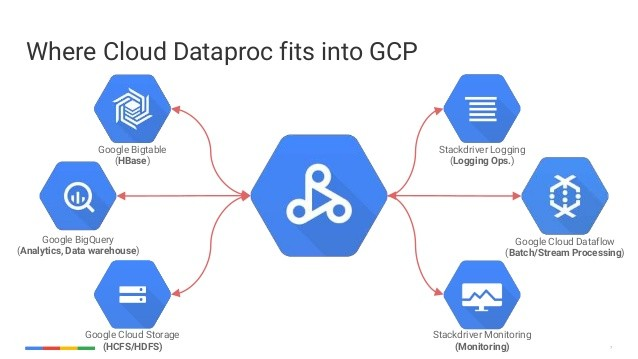 |
|---|
| Fig 2. Stack Overflow |
- Google Cloud Platform 의 관리형 Spark, Hadoop 서비스이다. 단순 관리형이기 때문에 EMR 과 유사하게 클러수터 수를 직접 조절해주어야 하며, 서버리스 버전으로는 Cloud Dataflow 가 있다.
- 참고를 위한 링크 :
Databricks
- 상기된 것과 같이, Dataproc 이나 EMR 과 같은 관리형 분산 처리 플랫폼은 Hadoop, Spark 클러스터 생성과 관리를 도울뿐 해당 툴들을 활용하는 방법에선 기존 시스템과 큰 차이점을 가지지 않는다.
- 반면 Databricks 는 분산 처리 시스템(Spark) 을 비개발자도 쉽게 활용할 수 있는 UI와 기타 단순화된 환경을 제공한다. Spark의 실제 개발진들이 만든 솔루션이기에 연동성이 완벽하다고 볼 수 있다.
- 이러한 단순화를 통해 Databricks 는 단일 플랫폼 내에서 데이터 분석가, 엔지니어, 사이언티스트 등이 각각의 목적에 맞게 데이터 환경을 구축하고 원하는 작업을 수행할 수 있도록 돕는다.
 |
|---|
| Fig 3. Databricks Interface 예시 |
주요 개념은 다음과 같이 정리할 수 있다 [Databricks Concepts 참고][Sungbin Cho 님의 Summary].
Workspace
- 워크스페이스는 인프라 상에 존재하는 데이터브릭스 자산을 접근할 수 있는 환경이다. 노트북, 대시보드와 같은 객체들을 폴더 형태로 구조화하고, 데이터 객체와 컴퓨팅 리소스에 대한 접근 또한 제공한다. 주요 객체는 다음과 같다 :
- 노트북 : 실행 커맨드, 시각화, 텍스트 등을 포함한 문서에 대한 웹 기반 인터페이스
- 대시보드 : 시각화 제공 인터페이스
- 라이브러리 : 클러스터 내 실행되는 노트북, job 등에서 활용 가능한 코드패키지로 커스텀하게 변경 가능
- Repo : Git repository 에 동기화되어 버전 관리되는 컨텐츠
- 실험 : ML 모델 훈련을 위한 MLFlow 실행 파일
Databricks Interfaces
- 여러 자산에 접근하기 위해 Databricks 가 제공하는 인터페이스로 UI, API, CLI 를 포함한다.
Data Management
Databricks File System (DBFS)
- Blob 스토어를 래핑한 파일시스템 추상화 레이어로 파일과 디렉토리로 구성되어있다.
Table
- 정형 데이터셋을 의미하며 Apache Spark SQL, API 를 활용해 생성할 수 있다.
- Databricks 내 생성되는 모든 테이블은 기본적으로 Delta table 의 형태를 가진다 - 참고 링크.
Metastore
- 데이터 웨어하우스 내 다양한 테이블과 파티션에 대한 구조 정보를 저장한다. 컬럼, 컬럼 타입, 파일 등에 대한 정보를 포함하며, 모든 데이터브릭스 배포본은 테이블 메타데이터를 영속화하기 위해 모든 클러스터가 접근 가능한 중앙 하이브 메타스토어를 가지고 있다.
Computation Management
Cluster
- 노트북과 Job 들이 실행되는 컴퓨팅 자원이나 설정들의 모음이며, 두가지 타입이 존재한다 :
- All-purpose : 수동으로 클러스터를 종료하고 시작할 수 있으며, 여러 사용자가 협업을 위해 하나의 클러스터를 공유할 수 있다.
- Job : 데이터브릭스 Job 스케줄러는 실행 시 새로운 클러스터를 생성하고, Job 이 끝나면 해당 클러스터는 종료된다.
Pool
- Idle 상태로 활용 가능한 인스턴스들이며, 클러스터의 시작과 오토 스케일링 시간을 줄인다. 풀에 접근한 클러스터는 풀에서 드라이버와 워커를 할당하며, 더 많은 리소스가 필요할 경우 자동적으로 확장하게된다. 접근한 클러스터가 종료되면 인스턴스들은 풀에 반환되고 다른 클러스터에 의해 재사용될 수 있다.