Introduction
- Apache Spark 는 제한된 공간의 로컬 환경에서 처리하기 어려운 대규모 데이터를, 여러대의 서버를 활용해 분산처리할 수 있도록 돕는 오픈소스 툴이다.
- Hadoop 생태계의 MapReduce 와 상응하는 개념이나, Map, Reduce 단계를 순차적으로 정의해야 하는 것이 아니라 사전 정의된 operation 을 통해 전처리가 가능하다 (예. join operation).
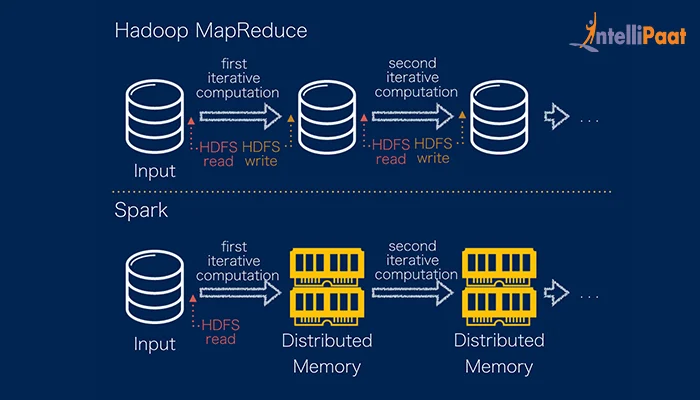 |
| Fig 1. MapReduce vs. Spark |
- Spark 는 기본적으로 연산 결과를 메모리상에서 처리하기 때문에 디스크 처리 위주인 MapReduce 방식에 비해 처리 속도가 월등히 빠르다.
- Spark 는 Scala 로 작성된 프로그램이며, Python 으로 다루기 위해서는 PySpark 라는 파이썬 API 활용이 필요하다.
Concepts
- Distributed Computing : 하나의 작업을 여러대의 서버로 분산하여 소요 시간을 단축하는 연산 방식
- Cluster : 유저의 요청에 따라 상호 작용하고, 결과값을 구하는 과정에서 활용되는 서버 군집
- Resilient Distributed Dataset (RDD) : 하둡 HDFS 와 유사한 분산 저장 환경이며, 정형 데이터 구조를 가지지 않음. 최근엔 널리 사용되지 않는다.
Spark Architecture & Theory
Architecture
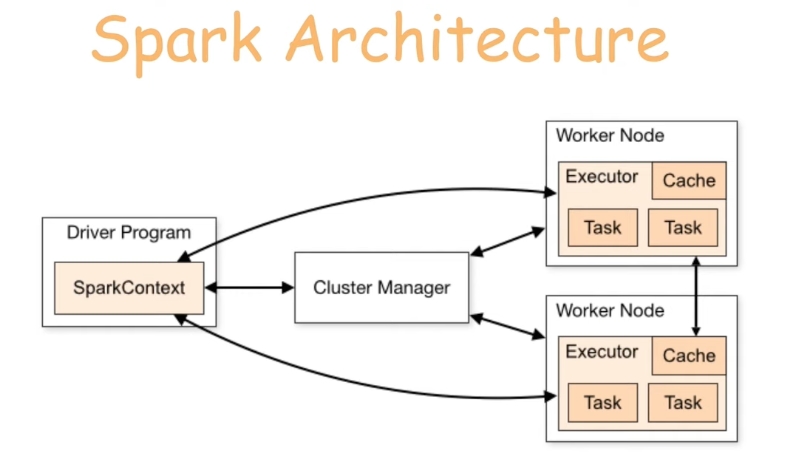 |
| Fig 2. Spark Architecture |
Spark 클러스터로 명령을 전달하고, 결과값을 전달 받기 위해선 우선 Spark 세션을 정의해주어야 한다.
1
2
|
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName('test').getOrCreate()
|
이렇게 정의된 세션은 Spark 클러스터의 마스터 노드인 SparkContext 와 소통한다. 반면 실제 분산 작업을 수행하는 노드는 Worker Node 라 지칭하며, SparkContext 는 Cluster Manager 를 통해 Worker Node 의 연산 자원을 부여받고, 업무를 분배한다.
각 Worker Node 안에는 작업을 수행하는 Executer 프로그램이 있으며, 여러 Task 를 동시에 저장하고 중간 결과를 캐시에 저장하는 기능을 제공한다.
Directed Acyclic Graph (DAG)
- Airflow 와 같은 단방향성 태스크 그래프를 의미한다.
- Spark 는 데이터 가공과 관련된 커맨드를 받은 후 이에 상응하는 DAG 연산 그래프를 생성한다.
- DAG 내 모든 작업을 작업 수행 이전에 파악하는 것이 가능하기 때문에, 이에 따른 최적화가 수반.
- 가공된 데이터는 새로운 데이터프레임 오브젝트 내 저장된다.
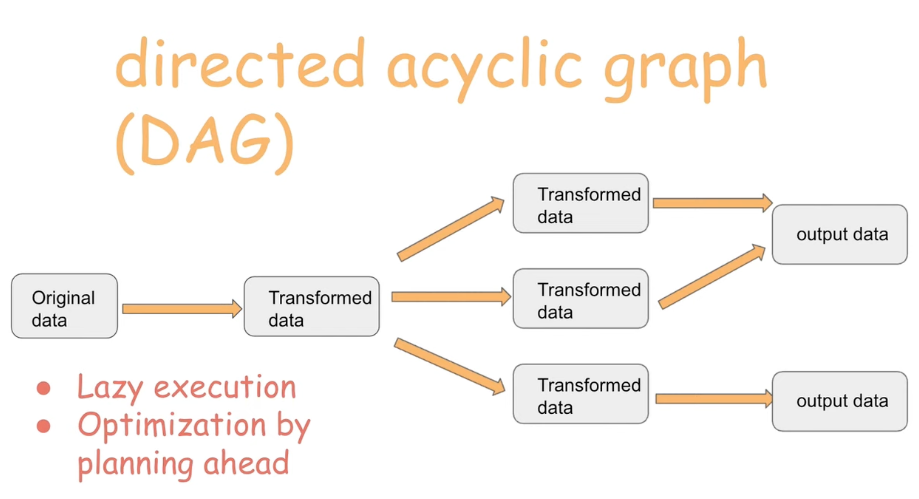 |
| Fig 3. Dag Overview |
- PySpark 에는 (1) Transformation, (2) Action 두 종류의 커맨드가 존재한다.
- 가장 대표적인 차이점은 Transformation 커맨드는 새로운 데이터프레임을 생성하지만, Action 커맨드는 실행 결과를 곧바로 출력한다는 점.
- 또한 Transformation 커맨드는 DAG 를 생성할 뿐 추후 실제 산출된 데이터가 필요할때까지 해당 DAG 를 수행하지 않는다. 반면 Action 커맨드는 코드 호출 시 곧바로 모든 가공 작업을 수행한다.
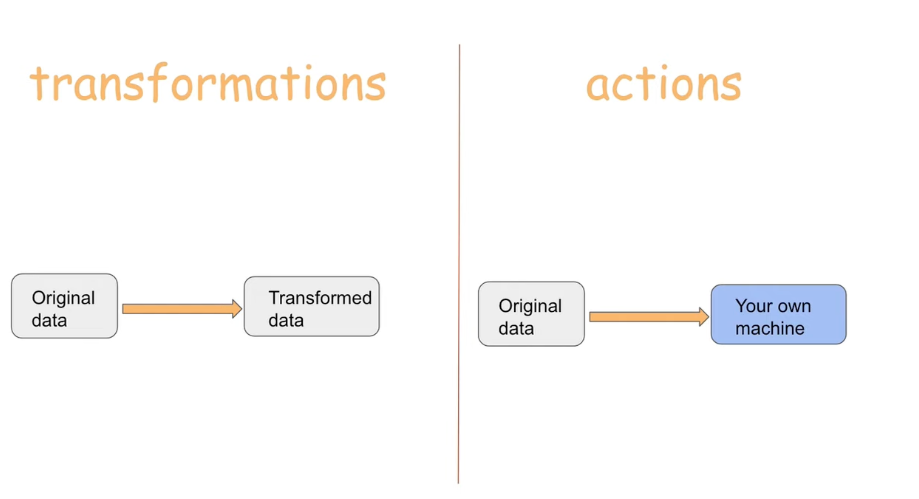 |
| Fig 4. Transformations & Actions |
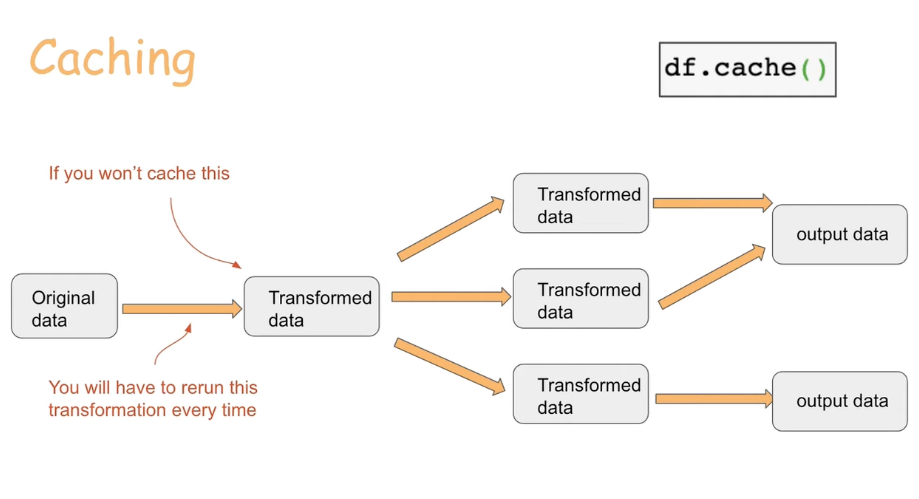
- 데이터 가공 중간 과정의 산출 결과를 캐싱하는 기능이 제공된다.
- 캐싱된 데이터는 Worker Node 의 메모리상에 존재하므로, 가용 공간에 비해 너무 큰 규모의 데이터가 캐싱되지 않도록 유의할 필요가 있다.
- 캐싱된 데이터를 취합해 Master Node 에 저장하기 위해선 콜렉션 기능을 활용한다.
- 캐싱 과정과 유사하게 Master Node 가용 공간을 감안하여 콜렉션을 수행할 필요가 있다.
 |
| Fig 5. Caching |
PySpark DataFrame
전처리 코드 예시
1
2
3
4
5
6
7
8
9
10
11
12
|
# 기본 csv 파일 로딩 (모든 데이터 타입은 String 으로 자동 지정)
df = spark.read.option('header', 'true').csv('/Users/shk/heart.csv')
# 데이터 타입 정의
schema = 'Age INTEGER, Sex STRING, ChestPainType STRING'
df = spark.read.csv('/Users/shk/heart.csv', schema=schema, header=True)
# 데이터 타입 추정
df = spark.read.csv('/Users/shk/heart.csv', inferSchema=True, header=True)
# Null Replace
df = spark.read.csv('/Users/shk/heart.csv', nullValue='NA')
|
1
2
3
4
5
|
# 기본 csv 파일 저장
df = spark.write.format('csv').save('/Users/shk/heart.csv')
# Overwrite
df = spark.write.format('csv').mode('overwrite').save('/Users/shk/heart.csv')
|
- Count, Show & Column Select
1
2
3
4
5
6
7
8
9
|
# Count Rows
df.count()
# 첫 5개 로우 보기
df.show(5)
# 컬럼 선택
df.select('Age').show(5)
df.select(['Age', 'Sex']).show(5)
|
1
2
3
4
5
6
7
|
# 데이터 타입 확인
df.printSchema()
df.dtypes
# 데이터 타입 변경
from pyspark.sql.types import FloatType
df = df.withColumn("Age", df.Age.cast(FloatType()))
|
1
2
3
4
5
|
# 컬럼 삭제
df.drop('AgeFixed')
# 컬럼 이름 변경
df.withColumnRenamed('Age', 'age')
|
1
|
df.select(['Age', 'RestingBP']).describe().show()
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
# Drop NA
df = df.na.drop()
# 전체 로우가 NA 인 경우만 삭제
df = df.na.drop(how='all')
# NA 삭제 기준 컬럼 수 정의
df = df.na.drop(thresh=2)
# NA 삭제 기준 컬럼 정의
df = df.na.drop(how='any', subset=['age', 'sex'])
# Replace 값 정의
df = df.na.fill(value='?', subset=['sex'])
# Imputer 활용 (평균치)
from pyspark.ml.feature import Imputer
imptr = Imputer(
inputCols=['age', 'RestingBP'],
outputCols=['age', 'RestingBP']
).setStrategy('mean')
df = imptr.fit(df).transform(df)
|
1
2
3
4
5
6
7
8
9
10
11
|
# 필터링
df.filter('age > 18')
df.where('age > 18')
df.where(df['age'] > 18)
# 필터링 (복수조건)
df.where((df['age'] > 18) & (df['ChestPainType'] == 'ATA'))
df.where((df['age'] > 18) | (df['ChestPainType'] == 'ATA'))
# 필터링 (반대조건)
df.filter(~(df['ChestPainType'] == 'ATA'))
|
1
2
3
|
from pyspark.sql.functions import expr
exp = 'age + 0.2 * AgeFixed'
df.withColumn('new_col', expr(exp))
|
1
2
3
4
5
6
7
8
9
10
11
|
# 평균치 산정
df.groupby('age').mean().select(['age', 'avg(HeartDisease)']).show(5)
# Sorting
from pyspark.sql.functions import desc
disease_by_age = df.groupby('age').mean().select(['age', 'avg(HeartDisease)'])
disease_by_age.orderBy(desc("age"))
# Functions
from pyspark.sql import functions as F
df.groupby('HeartDisease').agg(F.min(df['age']), F.max(df['age']))
|
Pandas 와의 비교
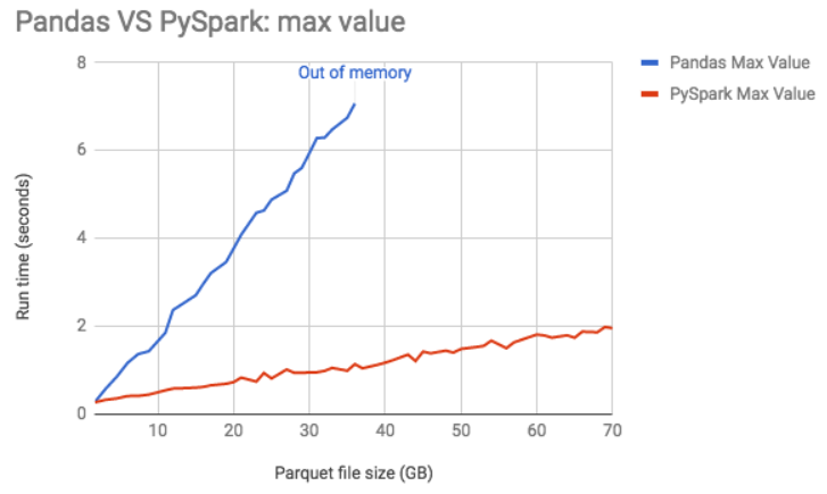 |
| Fig 6. Pandas vs Spark 데이터 처리 속도 비교 |
Row, Column, Schema 를 제공하는 유사한 데이터프레임 환경이나, 사용법이 동일하지 않고 싱글노드 기반의 Pandas 와 활용 목적에서 차이가 존재한다. 하지만, 파이썬 기반의 데이터프레임 환경인 만큼 상당히 유사한 부분들이 존재하고, Pandas 활용에 익숙한 사용자에게 PySpark 의 진입장벽은 낮은 편.
1
2
3
4
5
|
# Pandas 로 변환
pd_df = df.toPandas()
# Pandas 에서 변환
spark_df = spark.createDataFrame(pd_df)
|
Sources
- Moran Reznik - The Only PySpark Tutorial You Will Ever Need
- Computerphile - Apache Spark
- Simplilearn - Hadoop vs Spark
