Introduction
- 본 글은 2017 년 Uber Blog 에 개제된 Meet Michelangelo: Uber’s Machine Learning Platform 의 내용을 번역한 것이다. 문단 형태의 글을 bullet-point 로 축약하였고, 약간의 의역이 있다.
-
Michelangelo (미켈란젤로) 는 Uber 사내 활용을 위한 ML-as-a-Service 플랫폼이며, ML 모델 구축 및 배포 과정을 전직원이 보다 쉽게 접근할 수 있도록 돕는것을 그 목적으로 한다.
-
데이터 관리, 학습, 평가, 배포, 예측, 모니터링 까지 모든 end-to-end 기능을 제공하며, 전통적인 ML 모델은 물론 시계열 예측과 딥러닝 기능까지 제공하고 있다.
-
글이 써진 2017년을 기준으로 시스템은 약 1년간 활용되었고, Uber 의 여러 데이터 센터에 설치되고, 실제 모델 배포에 활용되는 등 이미 머신러닝을 수행하기 위한 기본 시스템으로 자리매김했다.
-
본 글은 이러한 미켈란젤로 시스템을 소개하고, 유즈케이스 및 기본적인 작업 과정을 순차적으로 설명한다.
Motivation behind Michelangelo
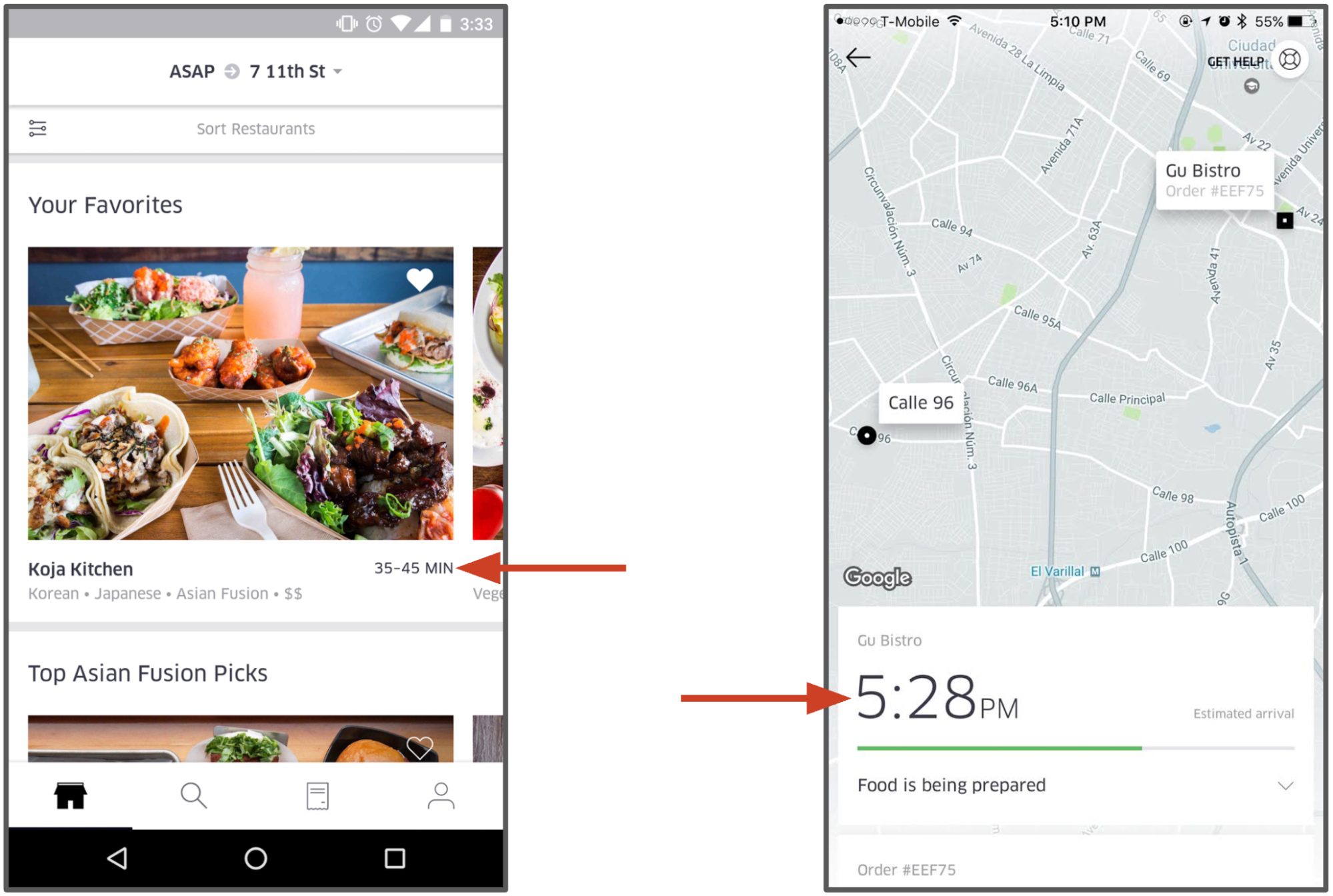
Use Case : UberEATS
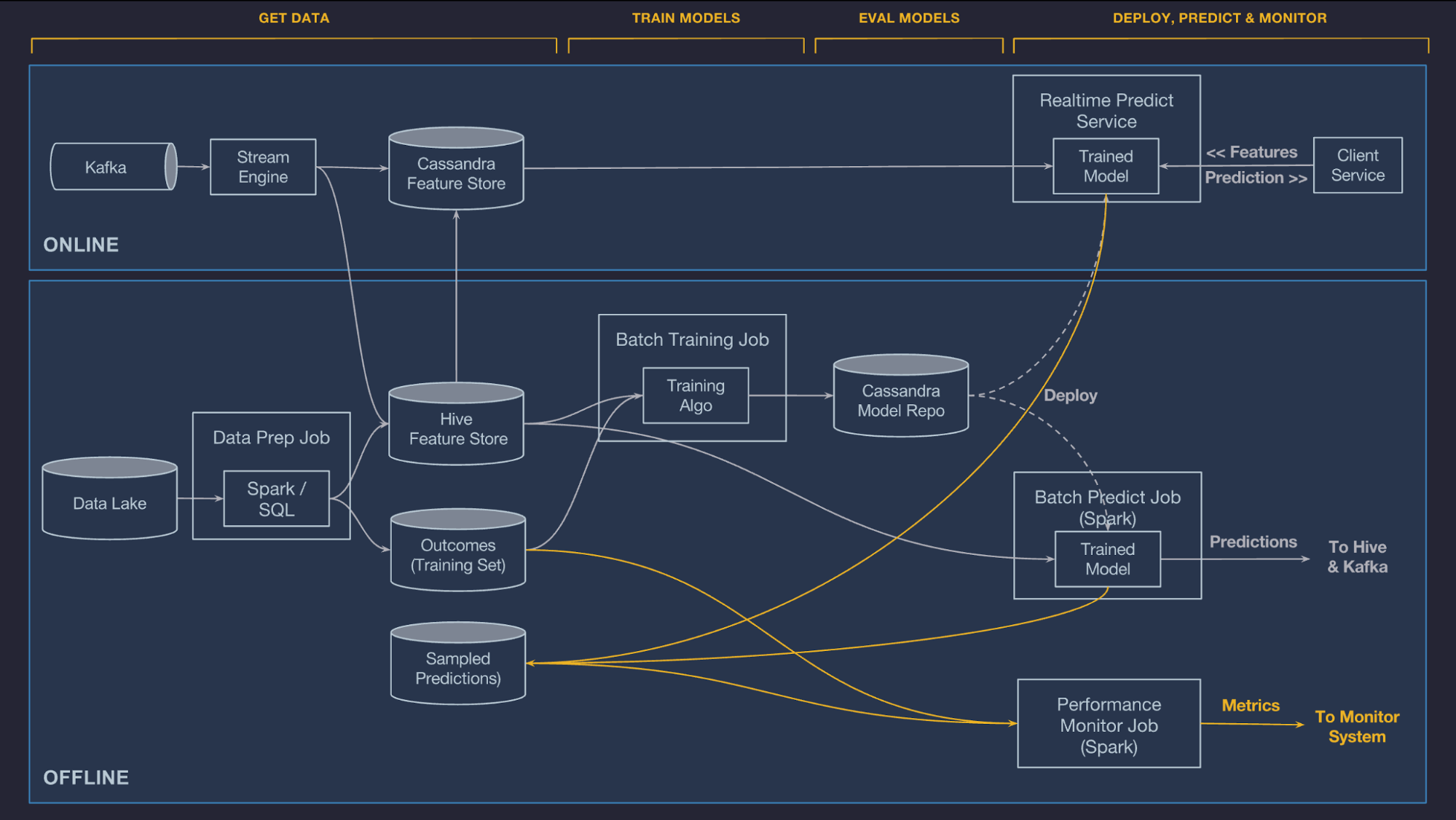
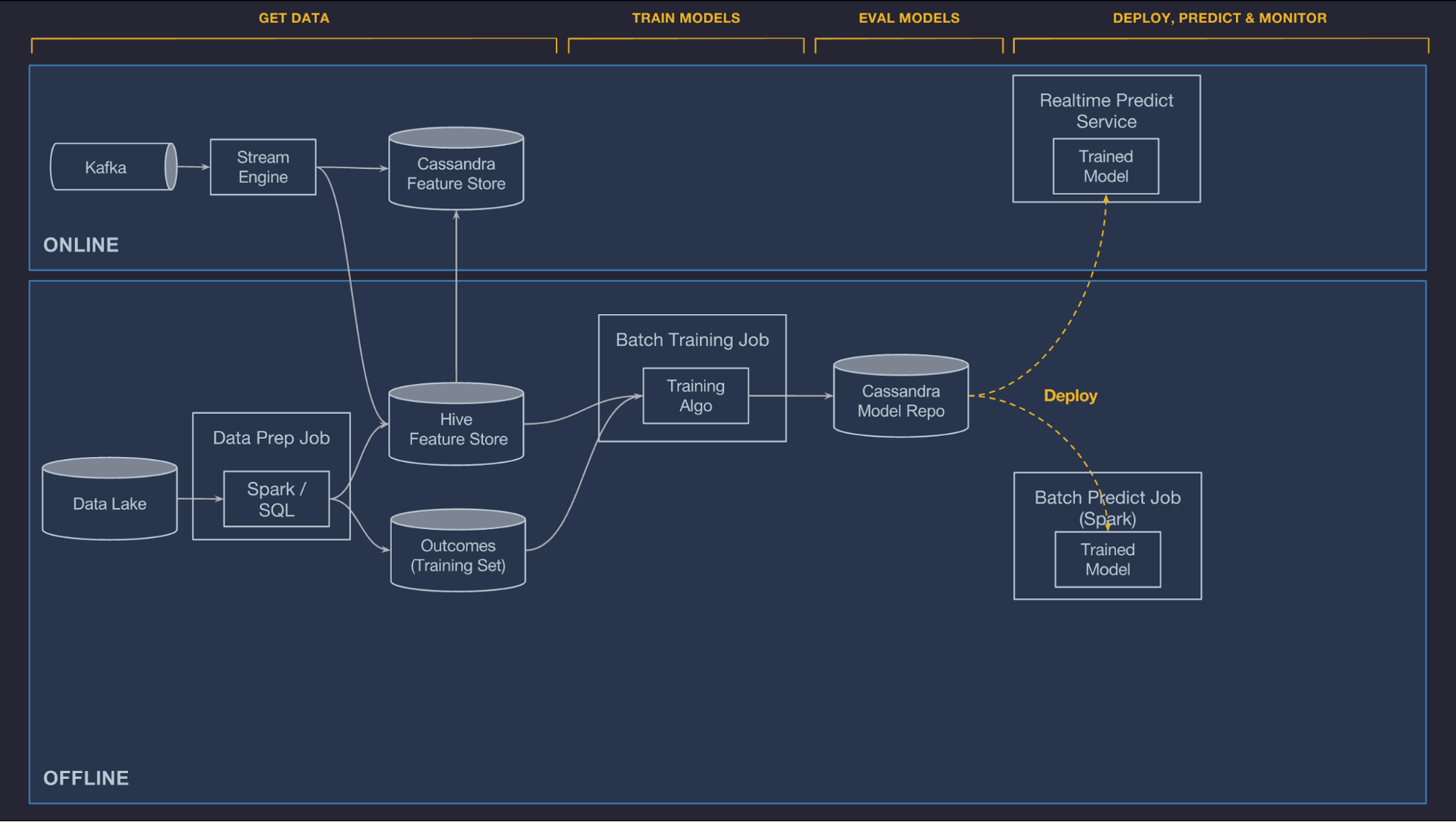
System Architecture
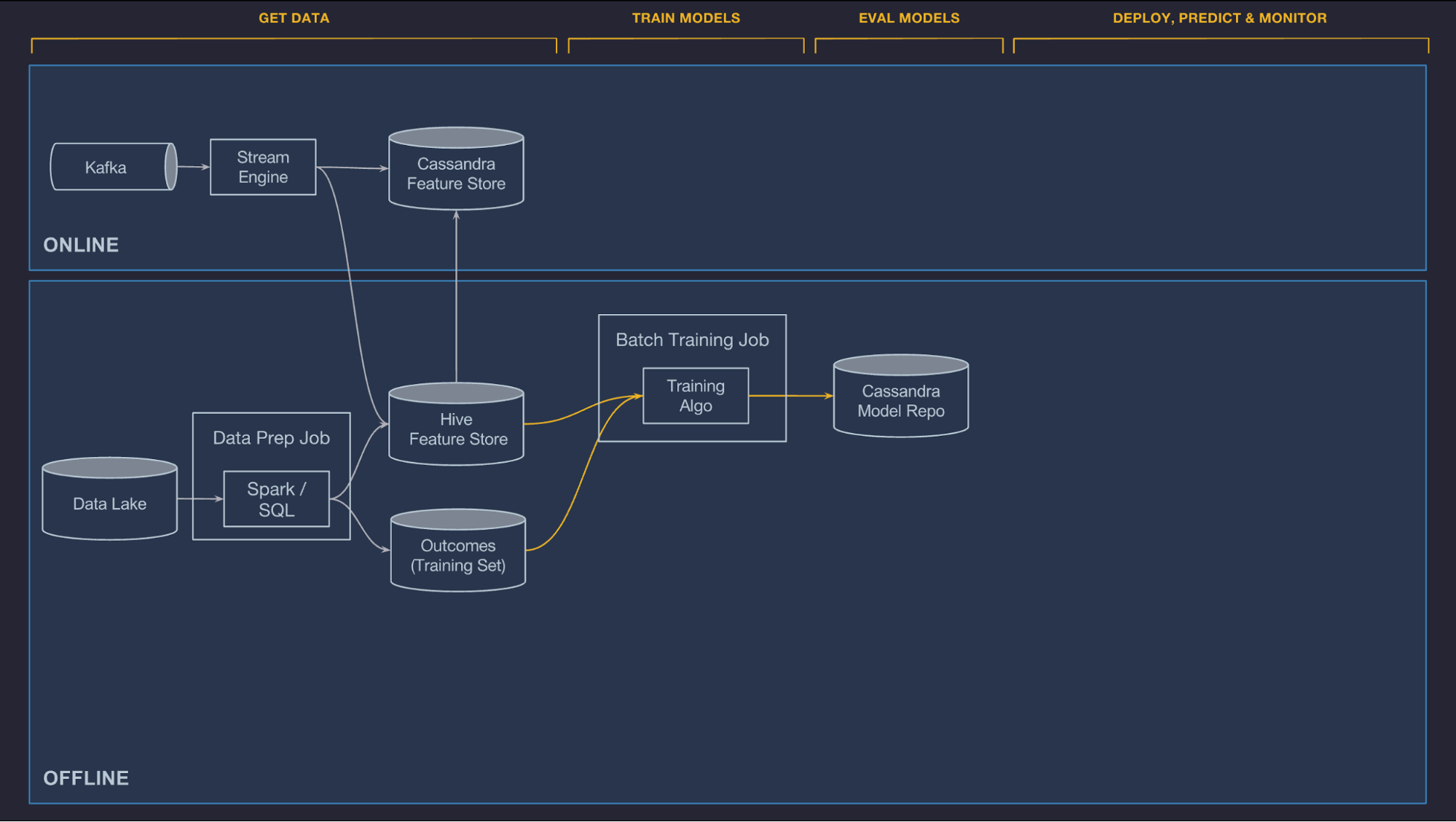
Machine Learning Workflow
Manage Data
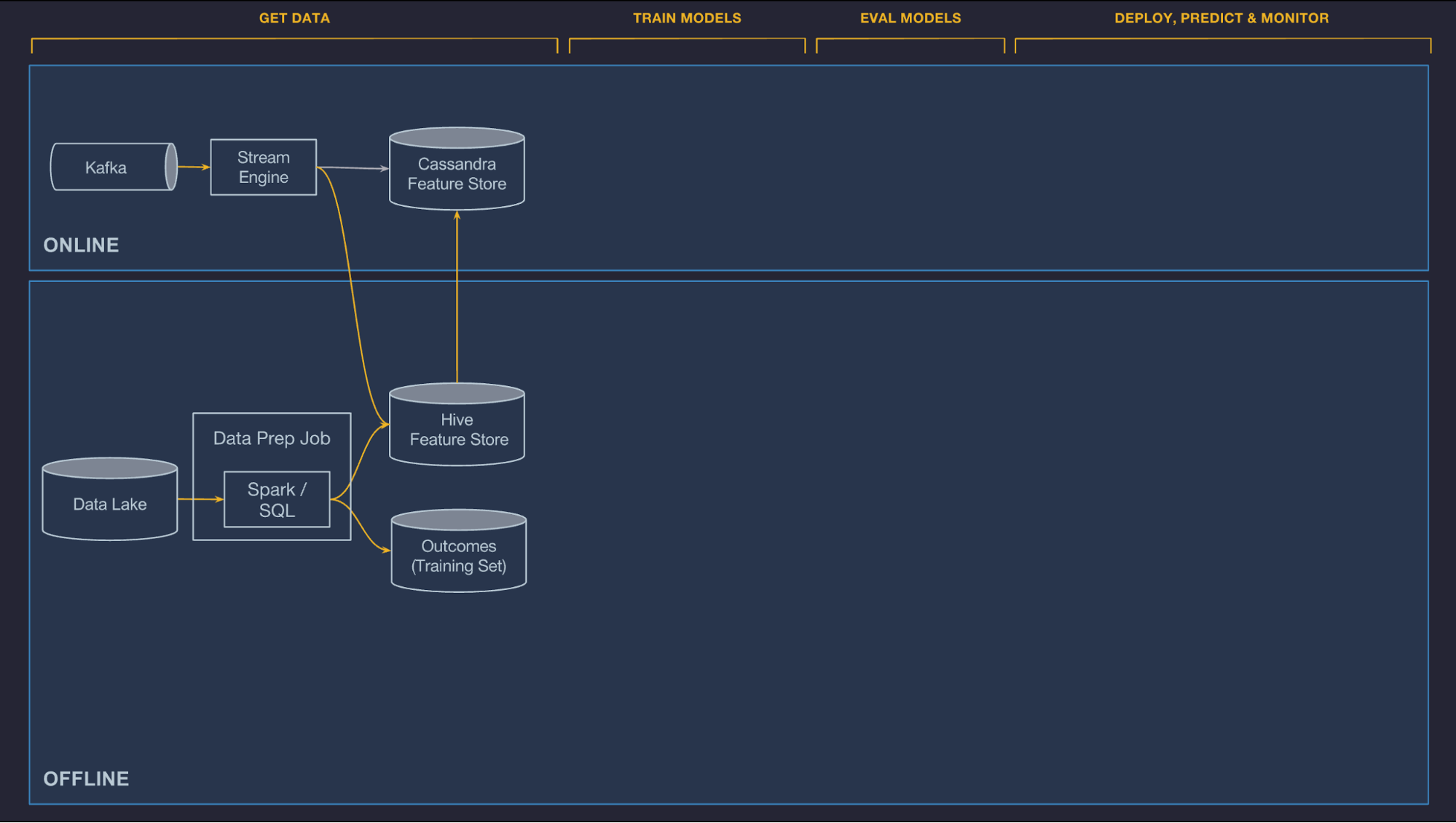
Offline
Online
Shared Feature Store
Train Models
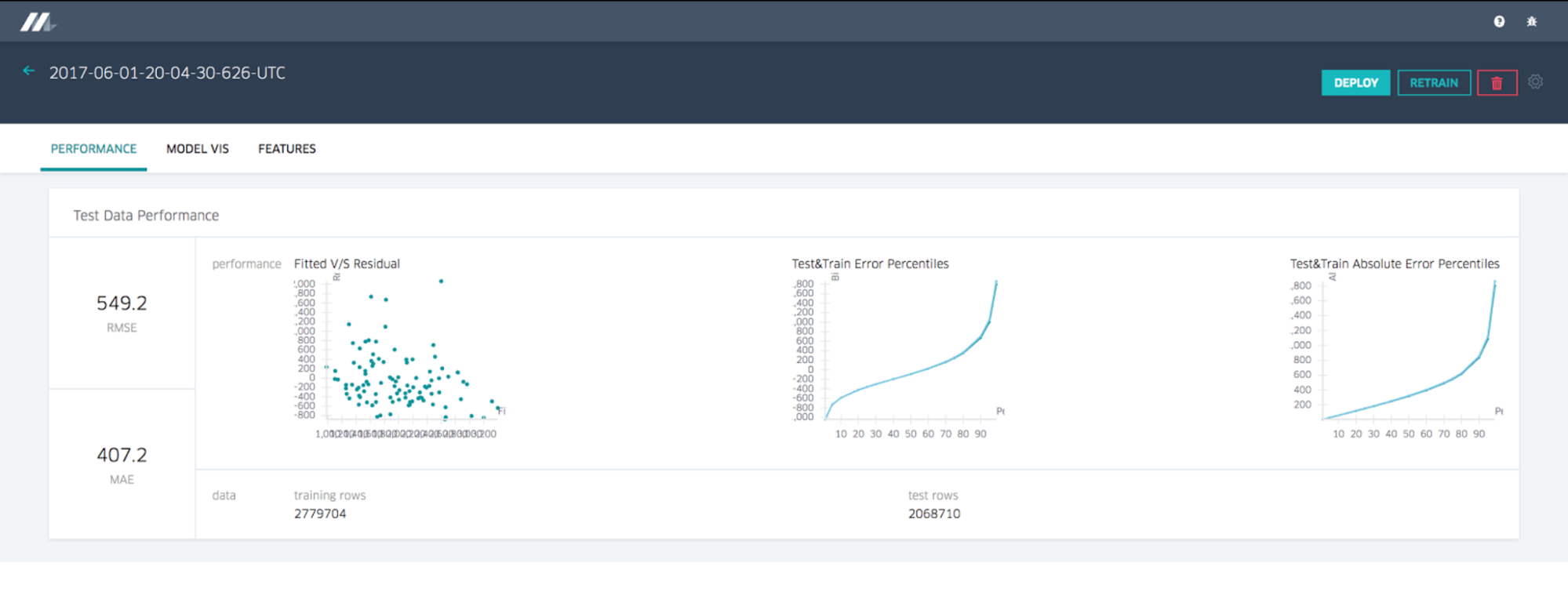
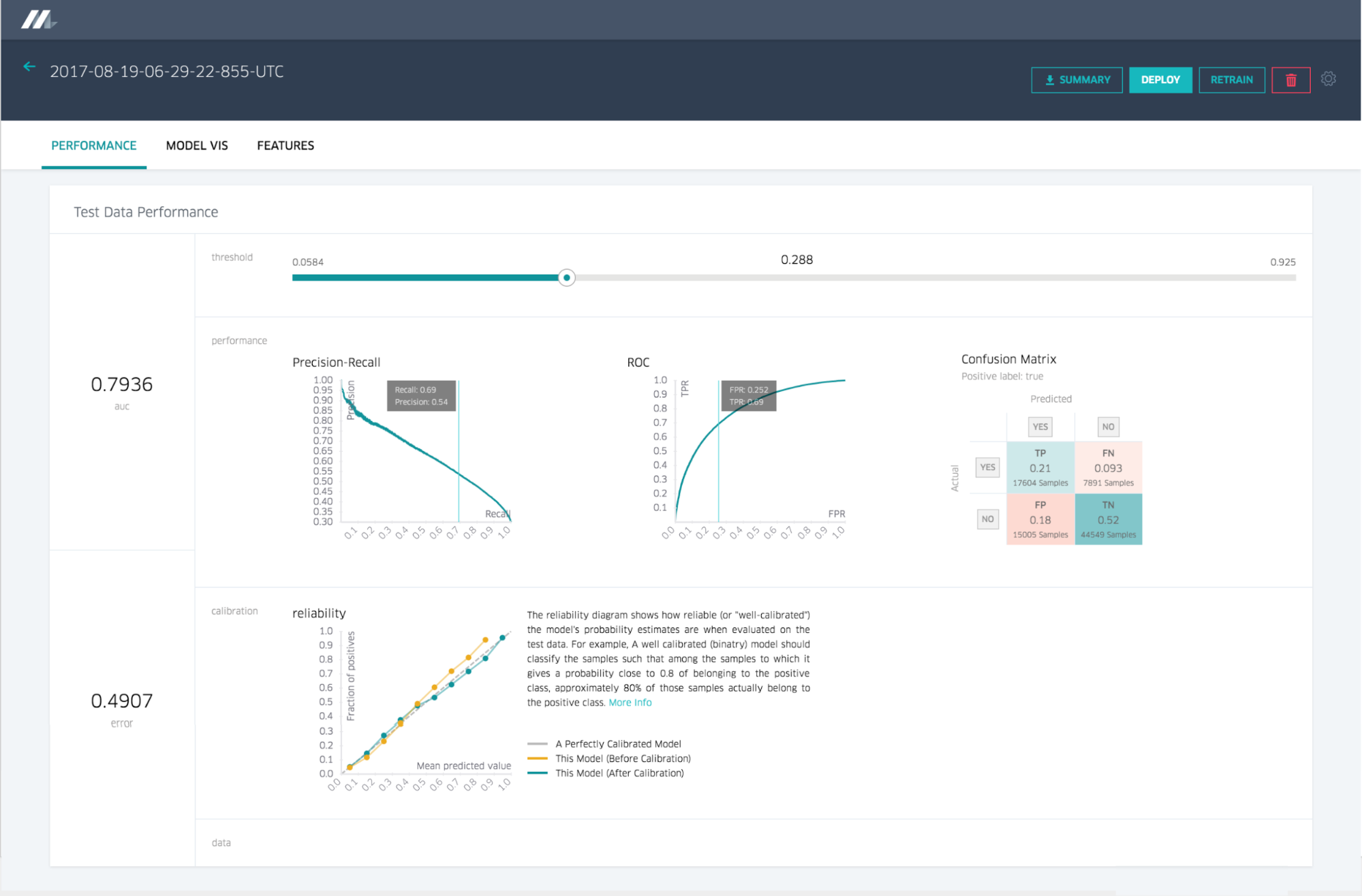
Evaluate Models
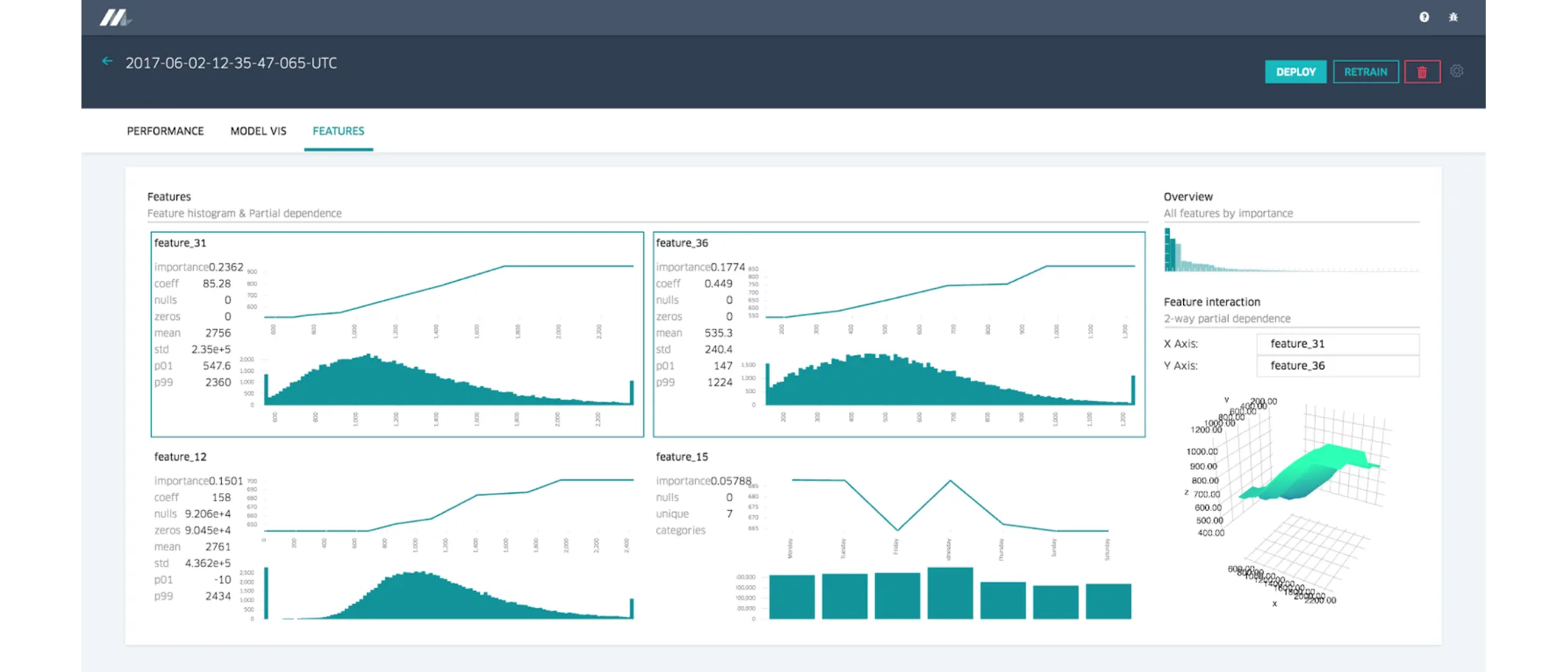
Model Accuracy Report
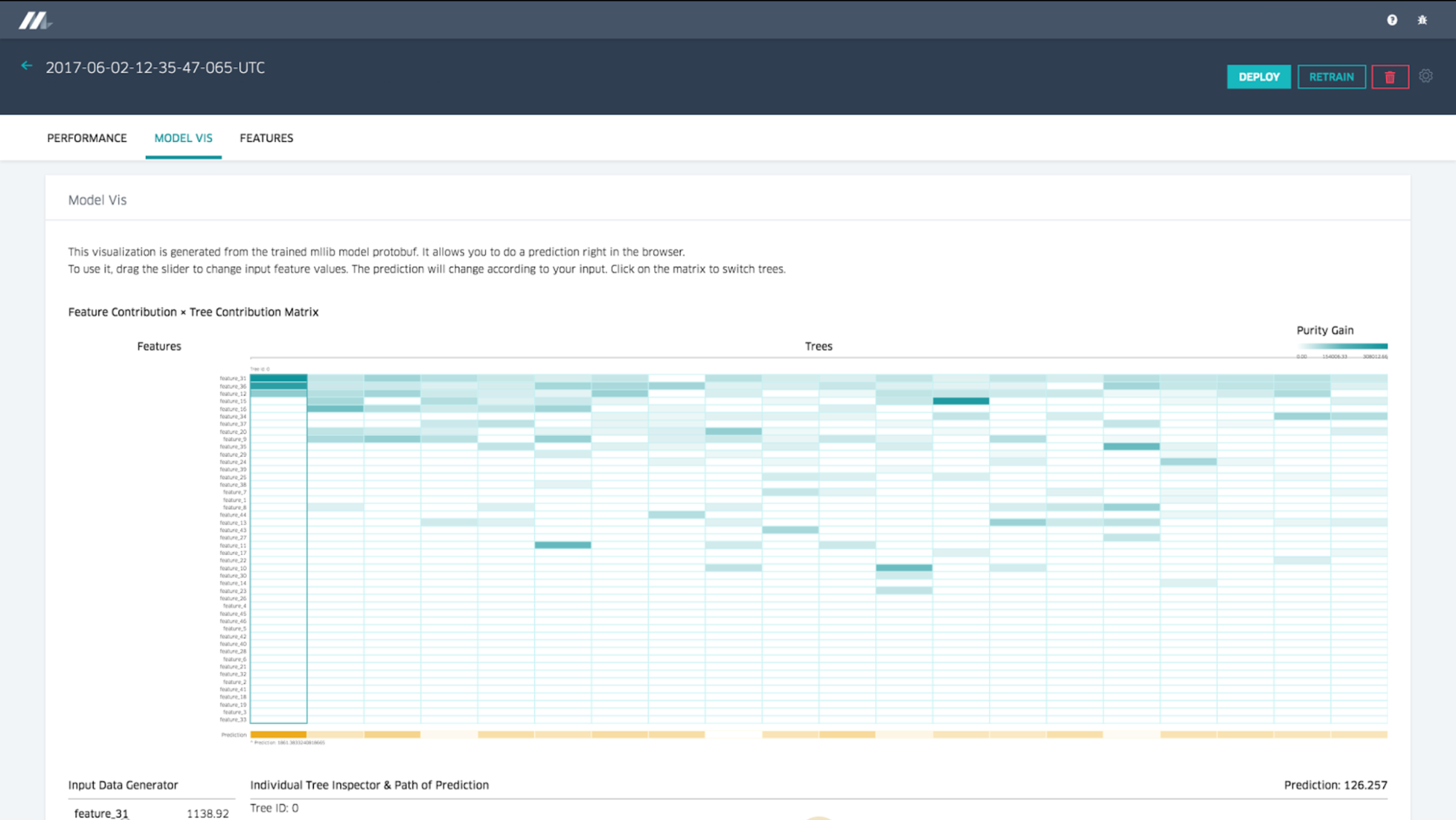
Decision Tree Visualization
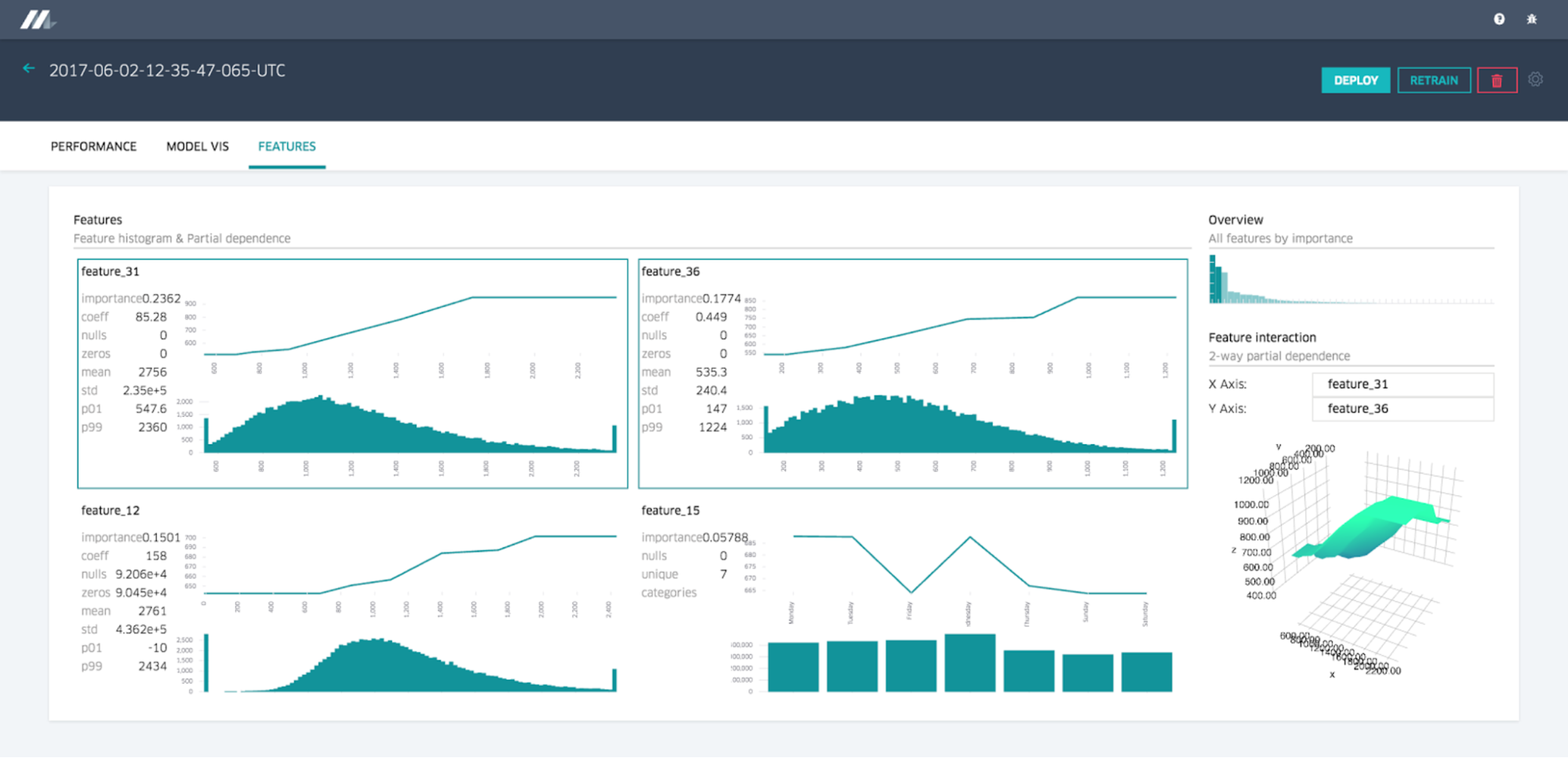
Feature Report
Deploy Models
Make Predictions
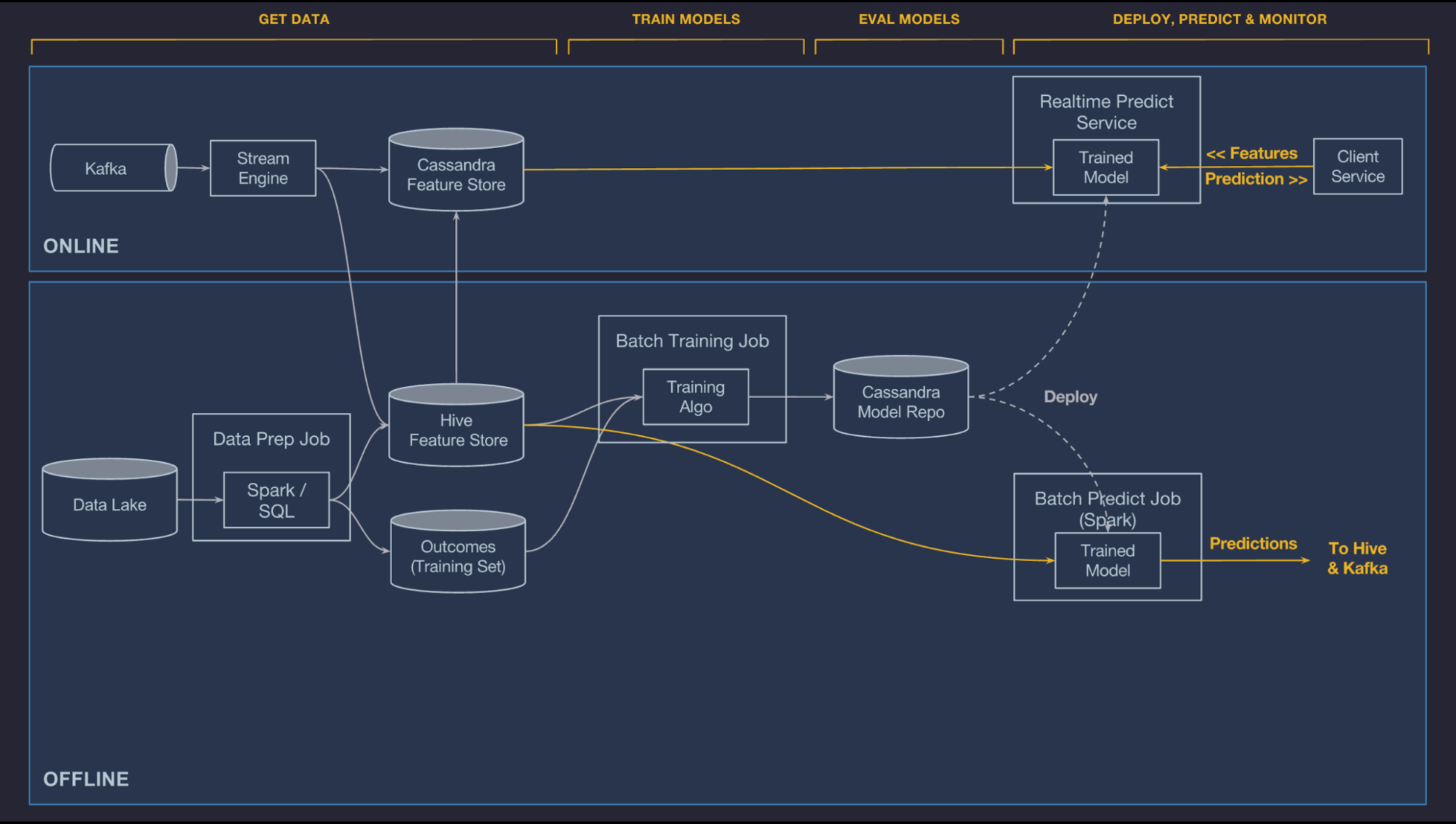
Referencing Models
Scale and Latency
Monitor Predictions