Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
Course Vision
- FSDL 과정이 처음 시작한 2018년에는 규모가 큰 기업들만 ML 제품을 내놓고 있는 상태였으며, 이들 이외의 기업들은 ML로 부터 부가가치를 창출하기 어렵다는 생각이 업계 전반에 있었다.
- 2022년 현재에는 트랜스포머의 등장으로 인해 NLP 분야가 더 많은 적용 사례들을 찾아내고 있고, 이외에도 많은 ML 제품들의 등장으로 MLOps 라는 단어가 사용되기 시작했다.
- 물론 업계 전반이 더 성숙해졌고, 주요한 연구 실적 또한 있었지만, ML 제품 개발이 더욱 활성화된 주요한 이유는 선행학습이 완료된 모델이 점차 상품화되고 있다는 점이다.
- 이제 HuggingFace 와 같은 툴을 이용하면 최신 NLP, 비전 모델을 코드 한두줄로 사용할 수 있다.
- 회사들은 학습된 모델을 네트워크를 통해 제공하기 시작했다.
- Keras, PyTorch Lightning 을 중심으로 유관한 프레임워크들이 표준화되기 시작했다.
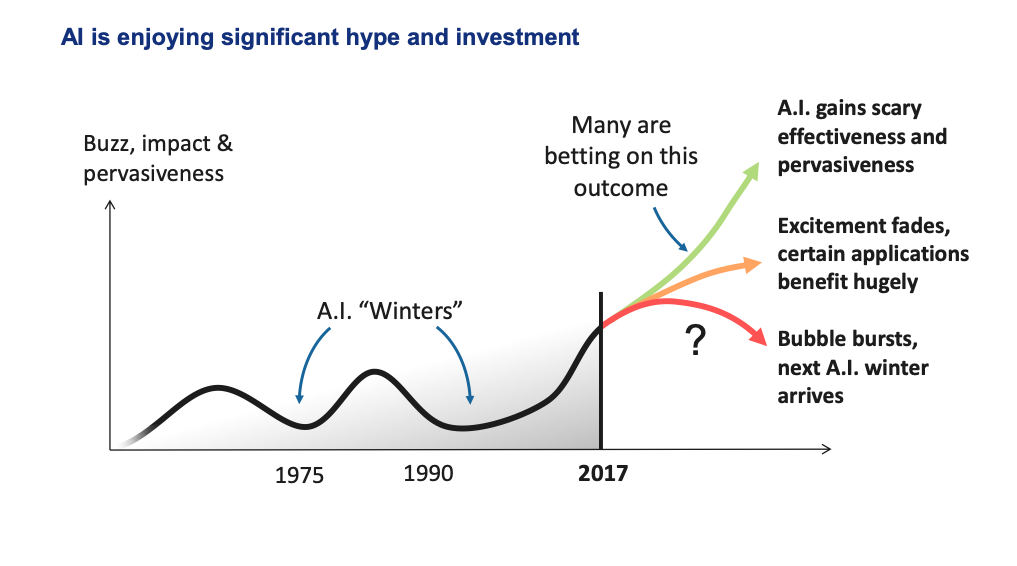
- AI 분야는 항상 대중의 관심 속에 있어왔지만, 기대에 부흥하지 못한 실용성으로 지난 수십년간 굴곡을 겪어왔다. 분야가 다시 성장하고 있는 지금, 또다른 혹한기를 피하기 위해 관련 연구를 real-world 제품으로 승화시켜야 한다.
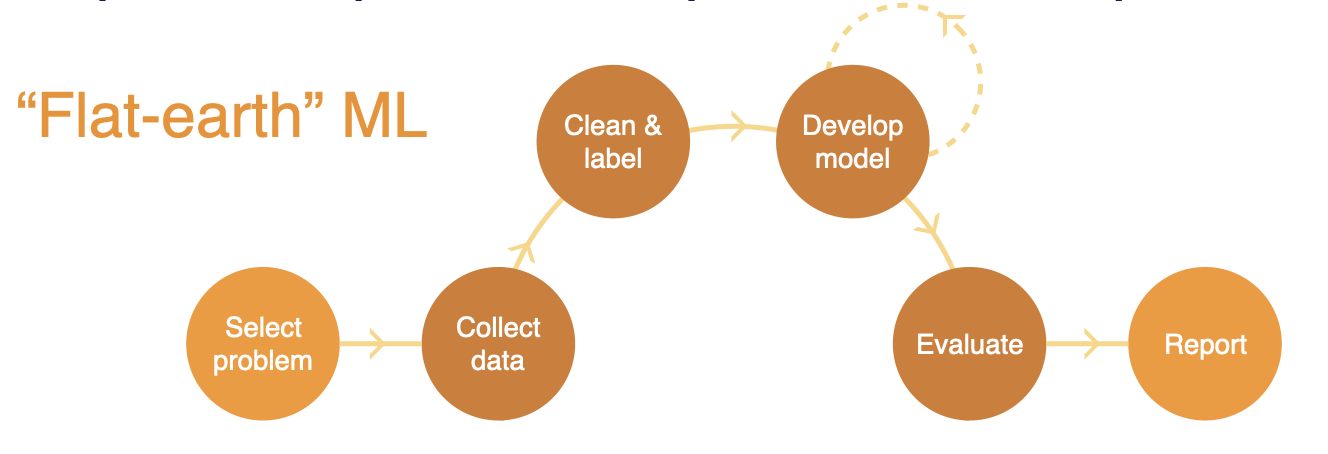
- 학계에서 다루는 ML 은 단차원적이다. 문제를 정의하고, 데이터를 수집하고, 정제한 다음 모델 개발 과정을 거쳐 잘 작동하는 ML 모델을 평가/보고함으로 과정이 끝난다.
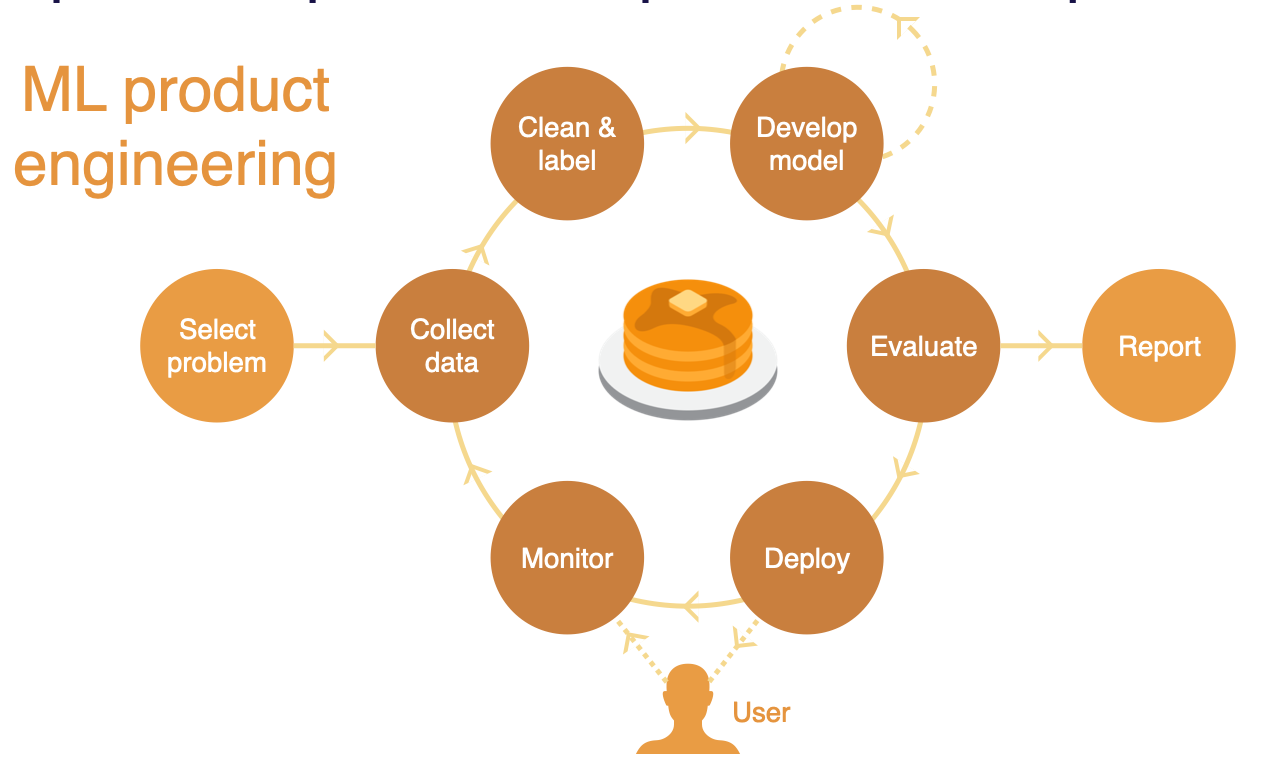
- 이에 반해 ML 제품은 배포 후 관리를 필요로한다. 실제 사용자들이 제품을 어떻게 경험하는지 관찰/측정한 후, 사용자들의 데이터에 기반한 data flywheel 을 만들어 모델을 고도화하게 된다.
- 본 과정은 모델 학습을 넘어 좋은 ML 제품을 만들기 위해 필요한 지식과 노하우를 전달한다. 이러한 제품에 어떤 부분들이 있어야 하는지, 제품 개발에서 발생하는 문제 해결을 위한 접근법은 어떠한 것들이 있는지 등을 가르친다.
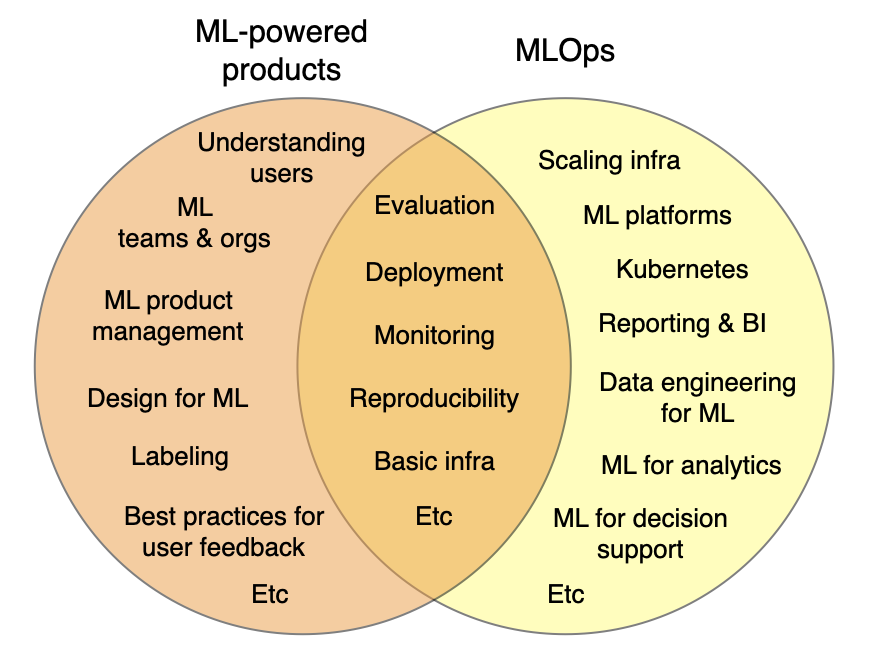
- MLOps
- MLOps 란 지난 몇년간 새로 등장한 분야이며, ML 시스템에 대한 배포, 유지, 운영에 관한 개념을 다룬다. 통제/반복 가능한 환경에서 모델을 구축하는 법, high scale 세팅에서 시스템을 운영하는 법, 시스템 유지를 위해 팀이 협업하는 법 등을 다룬다.
- ML 기반 제품
- ML 기반 제품이란 이와 유사성을 가진 개념이나, 완전히 같다고 볼 수 없다. 좋은 제품 개발은 운영 이외의 분야에 대한 깊은 생각을 필요로하고, 최종 제품에서 ML 이 어떠한 역할을 하는지에 집중하게 된다. 유저가 제품을 사용하면서 어떠한 경험을 가지는지, 조직과 효율적으로 협업하는 방법은 무엇인지, ML 분야의 프로덕트 매니징은 어떻게 이루어지는지 등의 개념을 다룬다.
- 본 과정은 좋은 ML 기반 제품을 만들기 위한 end-to-end 과정을 가르치며, 이에 필요한 기본적인 MLOps 개념만을 전달한다.
When To Use Machine Learning
-
ML 프로젝트는 일반적인 소프트웨어 개발보다 높은 실패율을 보인다. 많은 적용 분야에서 ML 이란 아직 연구 단계에 있기 때문이며, 때문에 100% 성공을 목표로 할 수는 없다.
-
이외에도 ML 프로젝트가 실패하는 이유 중 대표적인 예시는 다음과 같다.
- 기술적으로 불가능하거나 스코프 설정이 잘못되었기 때문
- 제품화로의 도약을 이루지 못하기 때문
- 조직적으로 ML 프로젝트 성공의 기준을 정하지 못했기 때문
- 문제 해결을 이루어냈으나, 복잡성에 비례한 정당성을 가지지 못했기 때문
-
따라서 ML 프로젝트를 시작하기 전, 다음과 같은 질문을 할 필요가 있다.
- ML을 활용할 준비가 되었는가? 구체적으로는 적용할 제품이 있는가? 이미 데이터를 활용 가능한 방식으로 수집하고 있는가? 적절한 인력을 보유하고 있는가?
- 문제를 해결하기 위해 정말 ML이 필요한가? 문제는 애초에 해결되어야 하는 것인가? 룰베이스 혹은 간단한 통계학을 통한 문제 해결이 가능하진 않은가?
- ML의 활용이 윤리적으로 올바른가?
-
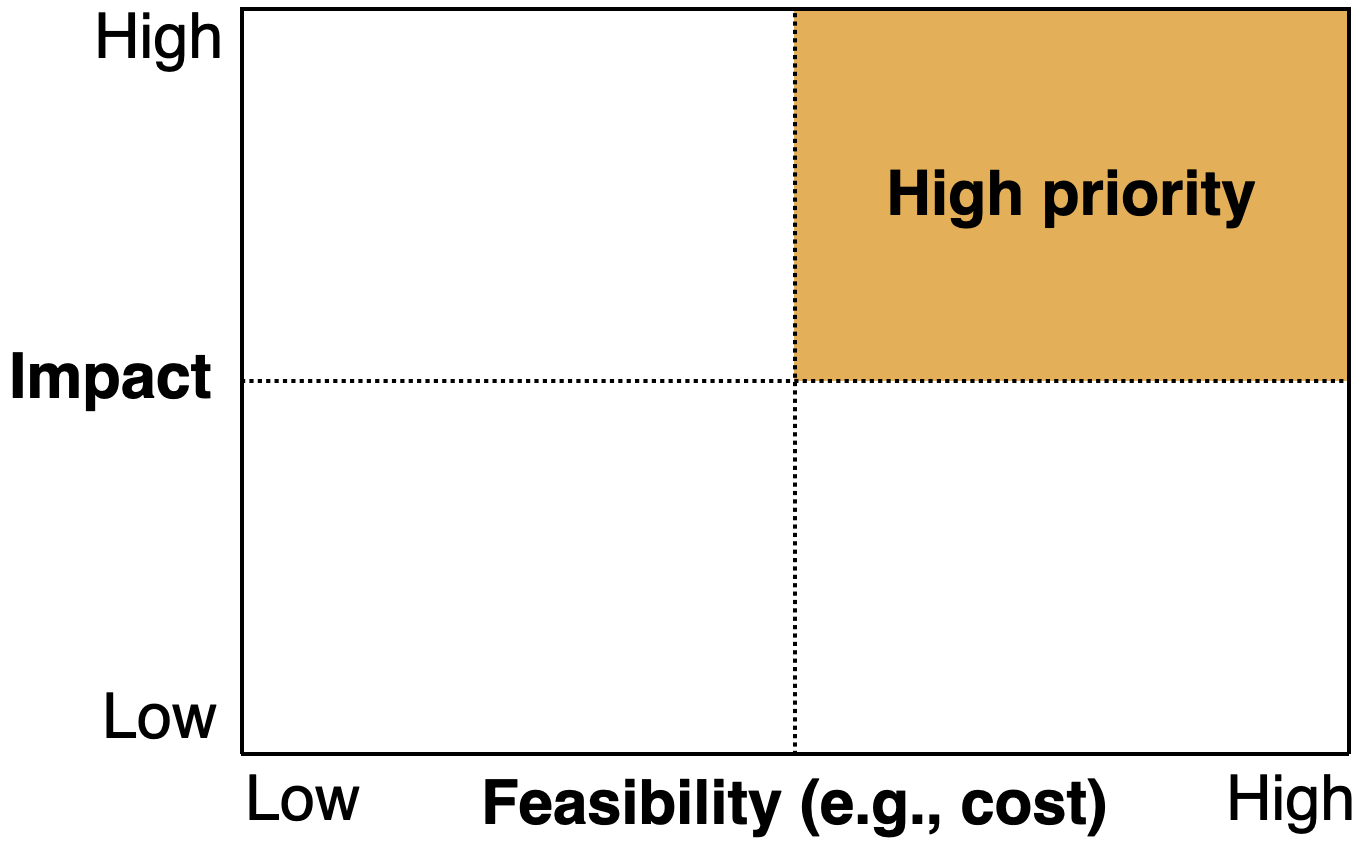
모든 분야의 프로젝트와 같이, 적절한 ML 프로젝트 선정을 위해선 큰 임팩트와 적은 비용을 가진 유즈케이스 선정이 필요하다.
- 큰 임팩트란 ML 이 서비스 파이프라인의 복잡한 구조를 해결하거나, 간단한 예측이 큰 의미를 가지는 경우를 뜻한다. 업계에서 ML 을 어떻게 활용하고 있는지 또한 좋은 지표가 될 수 있다.
- 적은 비용이란 데이터의 이미 존재하거나, 잘못된 예측이 어느정도 허용되는 경우를 말한다.
- 큰 임팩트를 가진 프로젝트
- ML 활용이 상대적 경제성을 가지는 경우.
- 제품이 필요로 하는 것이 무엇인지를 고민해야 한다. Spotify - Discover Weekly 를 구현하면서 세운 3가지 원칙 참조.
- ML 이 특히 잘하는 것이 무엇인가를 생각. 시스템에 복잡하고 수동적으로 정의된 부분이 있다면 ML 적용이 큰 도움이 될 수 있다.
- 업계에서 ML 이 어떤 문제를 해결하고 있는지를 참고.
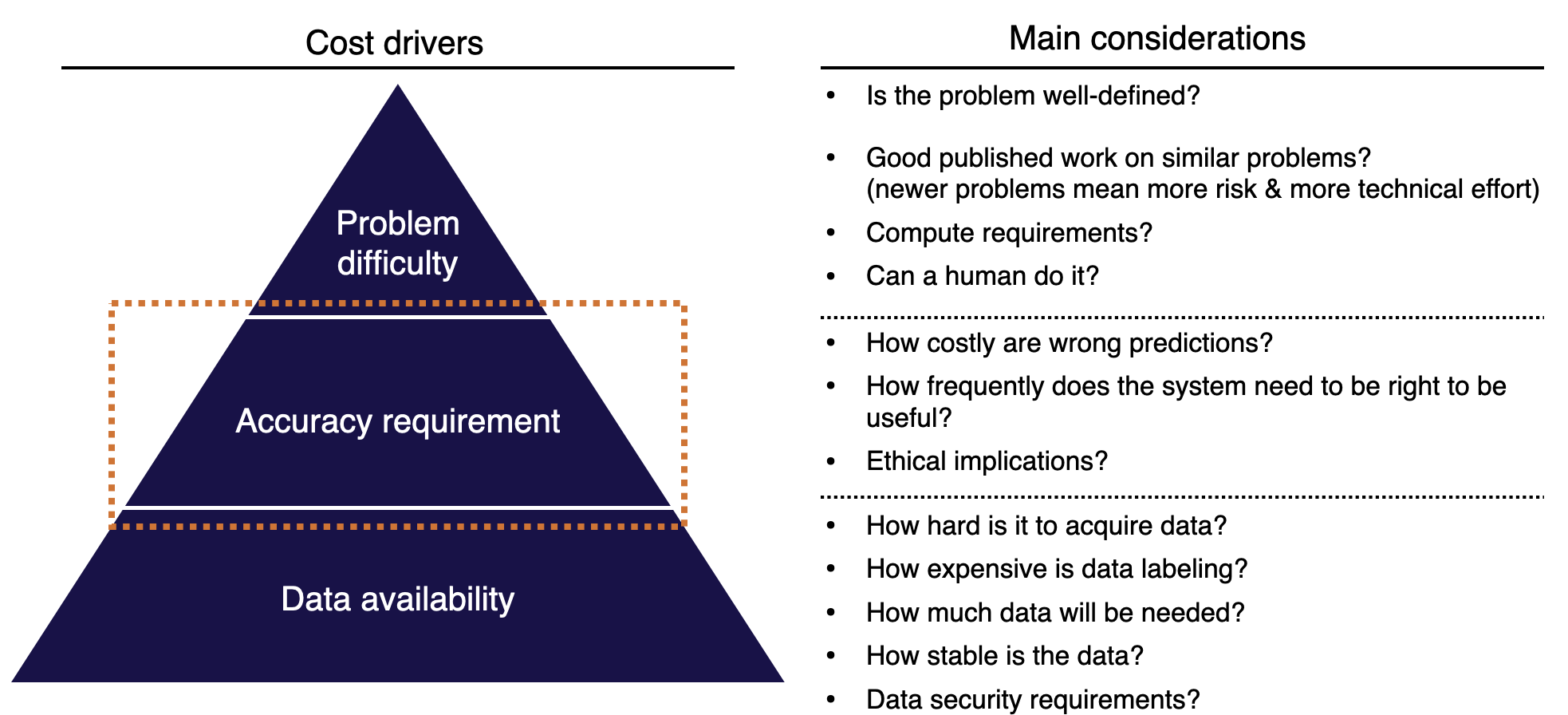
- 적은 비용을 가진 프로젝트
- 데이터 유무를 파악. 새로운 데이터를 확보하는 것은 얼마나 어려운지, 데이터 레이블링은 어느정도의 비용이 드는지, 얼마나 많은 데이터가 필요할 것인지, 데이터는 얼마나 정적인지, 어떠한 보안 규제가 존재하는지 등.
- 모델 정확도의 중요성을 고려. 잘못된 예측으로 인한 비용은 어느정도인지, 실용성을 위해 모델의 정확도는 어느 정도여야 하는지를 파악해야 한다.
- 문제의 난이도에 대한 고민. ML 활용으로 해결될 문제는 얼마나 잘 정의되었는지, 관련 주제에 대한 논의가 충분히 존재하는지, 연산 자원은 얼마나 필요한지 등.
-
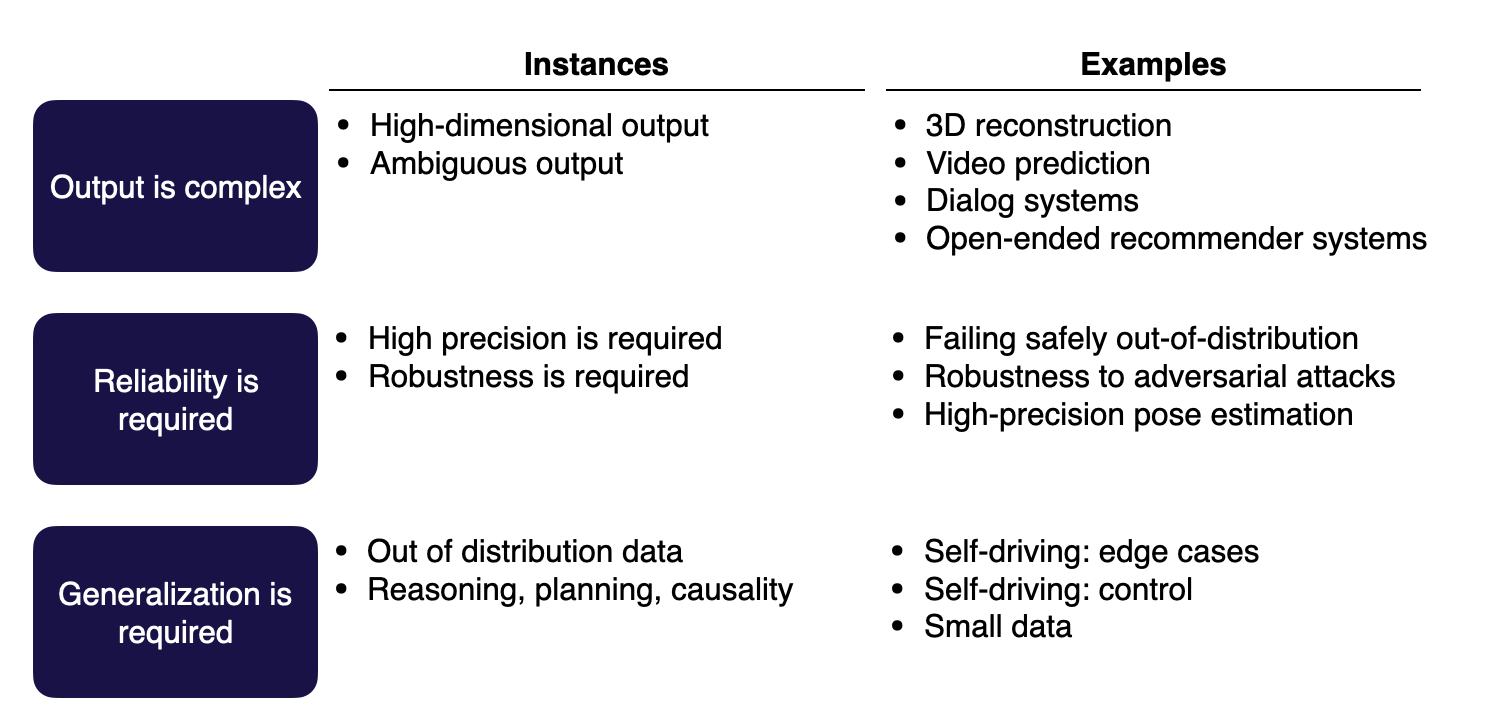
ML이 어려워하는 대표적 문제들
- 결과값이 복잡한 경우. 예측치의 정의가 불확실하거나, 고차원의 형상을 다루는 경우.
- 높은 정확도를 요구하는 경우. ML 모델은 예상치 못한 부분에서 실패하기 때문에, 일정 수준 이상의 정확도를 요구하는 경우 ML 적용이 적절하지 않을 수 있음.
- 일반화가 필요한 경우. 통계치에서 벗어난 데이터에 대한 예측을 요구하거나, 논리/계획을 세우거나 인과관계를 판단하는 작업을 요구하는 경우.
-
같은 ML 프로젝트라 할지라도 프로젝트의 성격에 따라 계획 과정은 판이하게 달라진다. 관련한 방법론을 수립하기 위해 강사진은 다음과 같은 3가지 카테고리로 ML 제품을 구분한다.
- Software 2.0 : 전통적인 소프트웨어에 머신러닝을 적용하는 경우이다. 코드 작성 AI 인 Github Copilot 을 예시로 들 수 있다.
- Human-in-the-loop : ML 시스템이 사람의 의사결정 체계를 돕거나, 효율성을 향상시키는 경우를 말한다. 단순한 스케치를 기반으로 PPT 슬라이드를 생성하는 등의 예시를 들 수 있으며, 이 경우 모델 아웃풋의 품질을 사람이 확인하는 과정이 수반된다.
- Autonomous Systems : ML 을 활용해 사람이 개입할 필요가 없는 완전한 자동화 시스템을 구축하는 경우이다. 자율주행 등을 예시로 들 수 있다.

- Software 2.0 의 경우, ML 적용이 실제 성능 개선에 도움이 되는지를 꼼꼼하게 점검해 볼 필요가 있다. 또한 서비스 배포 후 data flywheel, 즉 신규 데이터를 기반으로 모델을 개선시킬 수 있는 사이클이 구축될 수 있는지 또한 검토가 필요하다.
- Human-in-the-loop 시스템의 경우 사용자가 어떠한 배경, 환경을 가지고 모델을 활용하는지를 염두해야 하며, 그들의 니즈 또한 파악할 필요가 있다. 유저에게 실질적인 도움을 제공하려면 어느 정도 수준의 성능을 보여야 하는지 등을 고려해야 한다.
- Autonomous 시스템은 실패율과 그에 따른 결과에 집중할 필요가 있다. 사람이 개입할 여지가 없다면 실패 케이스들을 면밀하게 주시해야 하며, 자율주행이 이에 대한 좋은 예시라고 할 수 있다.
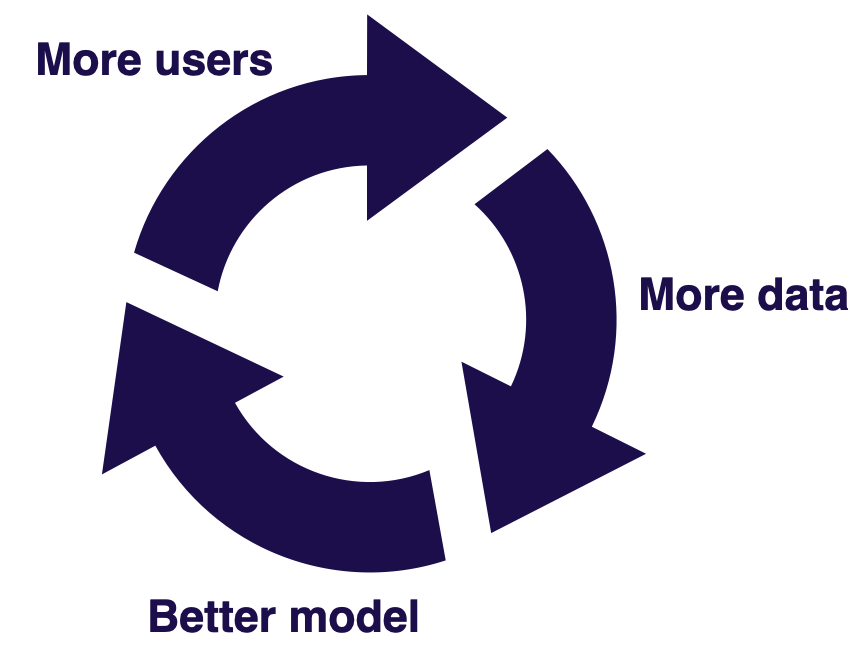
- 언급했듯 Software 2.0 프로젝트 내에선 data flywheel 개념을 곱씹을 필요가 있다. 경우에 따라 차이가 존재할 수 있지만, 대체로 유저의 데이터를 수집하여 모델 개선에 활용한다면 성능이 서비스 기간이 지남에 따라 개선될 가능성이 높다.
- data flywheel 을 구축하기 전, 다음과 같은 3가지 질문에 대한 답이 필요하다.
- 데이터 loop 이 존재하는가? Data flywheel 을 구축하기 위해서는 정제된 데이터를 스케일링이 가능한 방식으로 유저로 부터 수집할 수 있어야 한다.
- 더 많은 데이터가 더 나은 모델과 상응하는가? 모델러의 역량과는 별개로 문제 특성상 더 많은 데이터가 더 나은 모델을 의미하지 않는 경우가 발생할 수 있다. data flywheel 시스템 구축 전 더 많은 데이터가 가치를 전달하는지를 확실히 해 둘 필요가 있다.
- 모델의 성능이 제품 활용성에 기여하는가? 보다 근본적인 질문인데, 모델의 성능 개선이 유저의 경험에 긍정적으로 기여할 수 있는지 또한 짚고 넘어가야 할 부분이다.
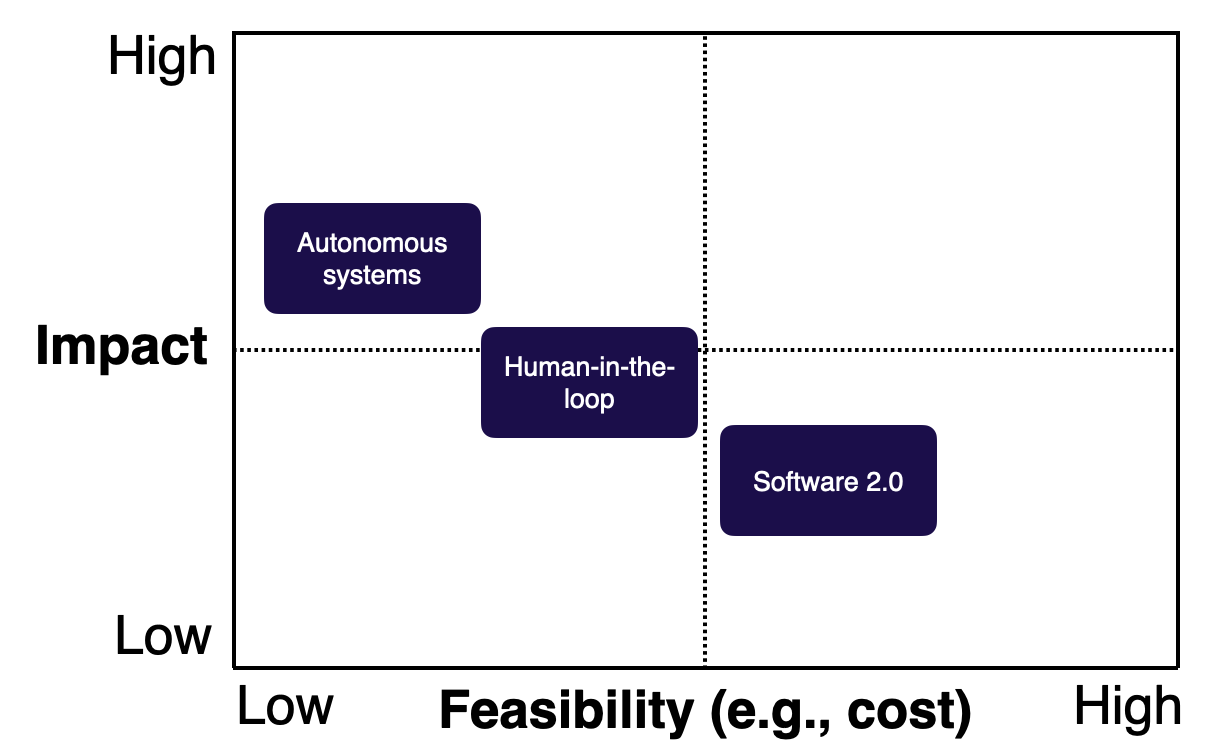
-
상단 이미지는 영향성 vs. 실현 가능성 그래프에서 정의된 3가지 타입의 과제가 상대적으로 어디에 위치해 있는지를 보여준다. 대체로 모델을 구축하기 힘들수록 더 큰 영향을 끼친다라는 규칙이 통용된다.
- Software 2.0 는 data flywheel 구축을 통해 더 큰 영향력을 가질 수 있다. 모델의 성능이 증가하며, 이로 인한 사용자의 경험이 계속 개선되기 때문.
- Human-in-the-loop 시스템의 경우 충분한 고민이 반영된 설계 과정, 혹은 적절한 단계에서 배포 후 점차 성능을 개선시킨다는 “good enough” 마인드 셋이 제품에 대한 기대치와 목표 성능을 낮추는데 도움을 줄 수 있다.
- Autonomous 시스템은 사람의 개입을 유도해 모델의 실패에 대비하는 체계가 도움을 줄 수 있다.
-
하지만 결국 엔지니어링의 가장 중요한 측면은 무언가를 만드는 일이다. 우리는 Google, Uber 와 항상 같은 환경을 구축할 필요가 없으며, 최신 툴과 완벽한 체계를 추구하기 전 먼저 문제에 대한 해결책을 찾는 것이 핵심이라는 점을 상기해야 한다.
Lifecycle
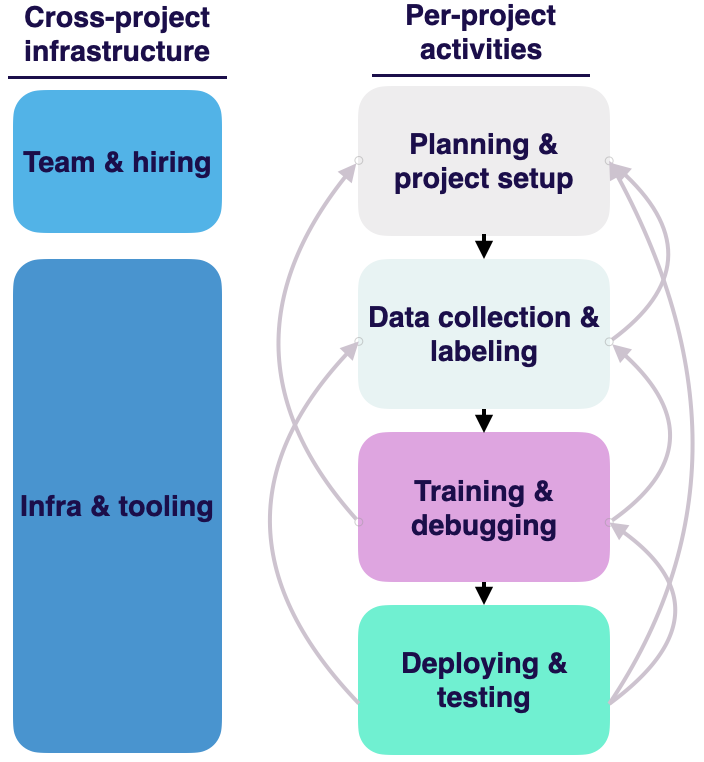
- ML 프로젝트가 계획적/단계적으로 진행되기엔 현실적으로 어려운 부분이 많으며, 중간 과정에서 발견된 인사이트로 인해 이전 단계의 작업을 번복하거나, 성능 요건을 재정의 하는 등 단계 별 작업이 병렬적으로 진행되는 경향이 있다.
- 본 부트캠프는 이러한 프로젝트 lifecycle 의 각 단계를 가급적 성공적으로 수행하는 방법을 전달하고, 채용, 인프라 등 프로젝트 외 요소들 또한 어떻게 다루어야 하는지 공유한다.