Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
Introduction
- 이상적인 ML 환경이란 정의된 프로젝트 목표와 샘플 데이터를 기반으로, 지속적으로 개선되는 예측 시스템을 큰 규모로 운영하는 것이다.
- 현실은 이와는 다를 수 밖에 없다. 데이터에 대한 수집, 처리, 레이블, 버저닝이 필요하며, 적합한 모델 구조와 사전 학습된 가중치를 찾아야하고, 프로젝트에 적합하게 디버깅해야 한다. 또한 여러 학습 과정을 기록 및 리뷰해야하며, 모델 배포 후에도 끊임없이 생성되는 데이터를 기반으로 모델을 개선해야 한다.
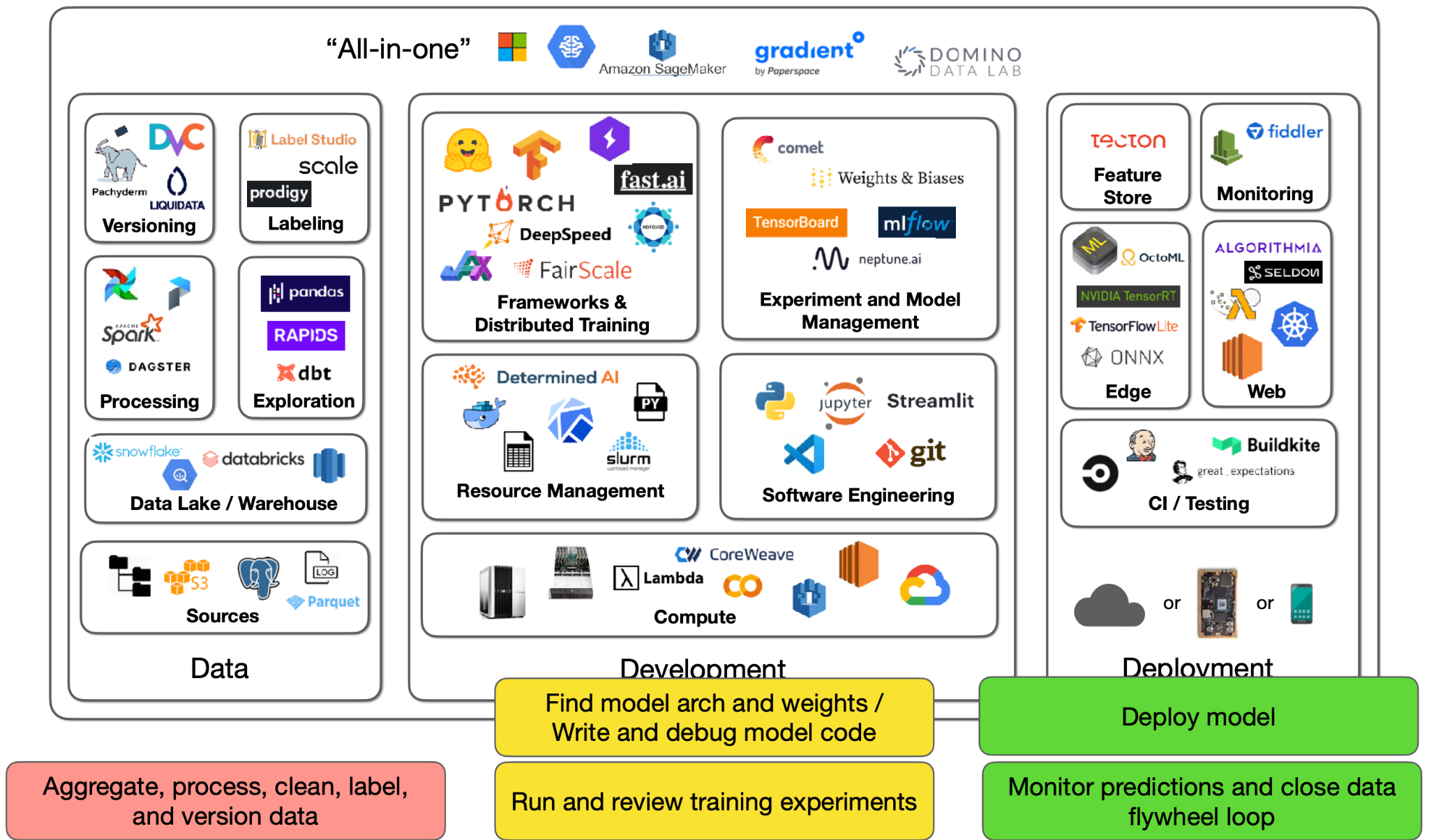
- 이러한 환경의 3가지 주요한 컴포넌트는 데이터, 개발, 배포이다. 각각의 컴포넌트는 방대한 툴을 가지고 있고, 3주간 강의를 통해 이들 모두를 전반적으로 살핀다. 본 강의의 주제는 개발이다.
Software Engineering
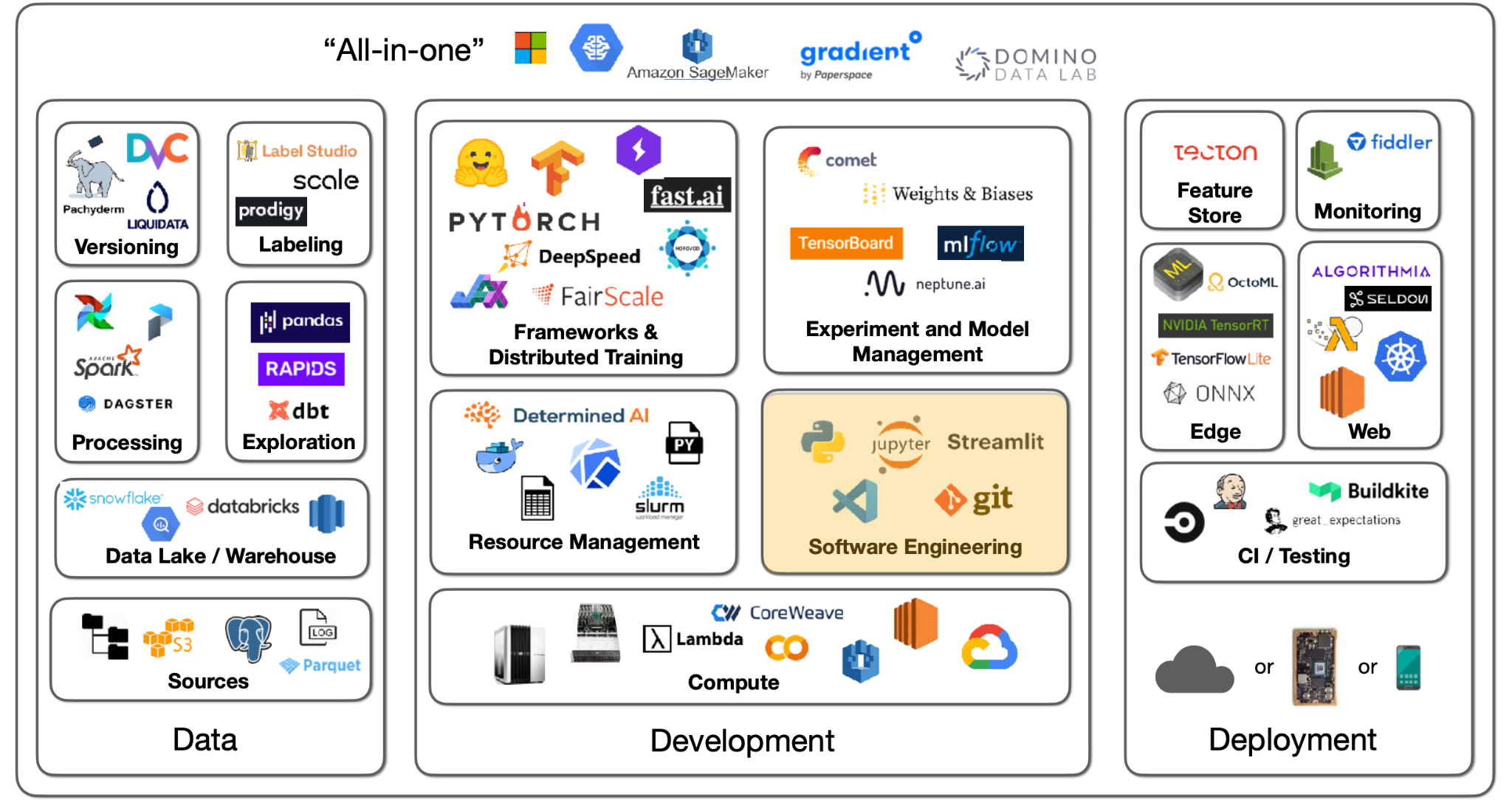
-
개발 언어의 경우 데이터 컴퓨팅 분야에선 현재 Python 이 절대적인 우위를 점하고 있다. 너무나 많은 부속 라이브러리들이 개발되었기 때문이며, Julia, C/C++ 와 같은 경쟁자가 존재했지만 사실상 Python 이 생태계를 독점하고 있다.
-
파이썬 코드를 작성하기 위해서는 에디터를 사용해야 한다. Vim, Emacs, Jupyter Notebook/Lab, PyCharm 등 수많은 옵션이 있지만 FSDL 팀이 제안하는 에디터는 VS Code 이다. 내장된 Git 버전 컨트롤, docs peeking, 원격 접속, 린터, 디버깅 기능 등을 제공하기 때문.
-
수많은 현업들이 Jupyter Notebook 환경을 사용하지만, 에디터가 별다른 기능을 제공하지 못하고, 코드의 작성 순서가 중요하지 않으며, 버전 컨트롤, 테스팅이 어렵다는 문제를 가지고 있다. Nbdev 패키지를 활용하면 이러한 문제들은 어느 정도 해결은 가능하다.
Deep Learning Frameworks
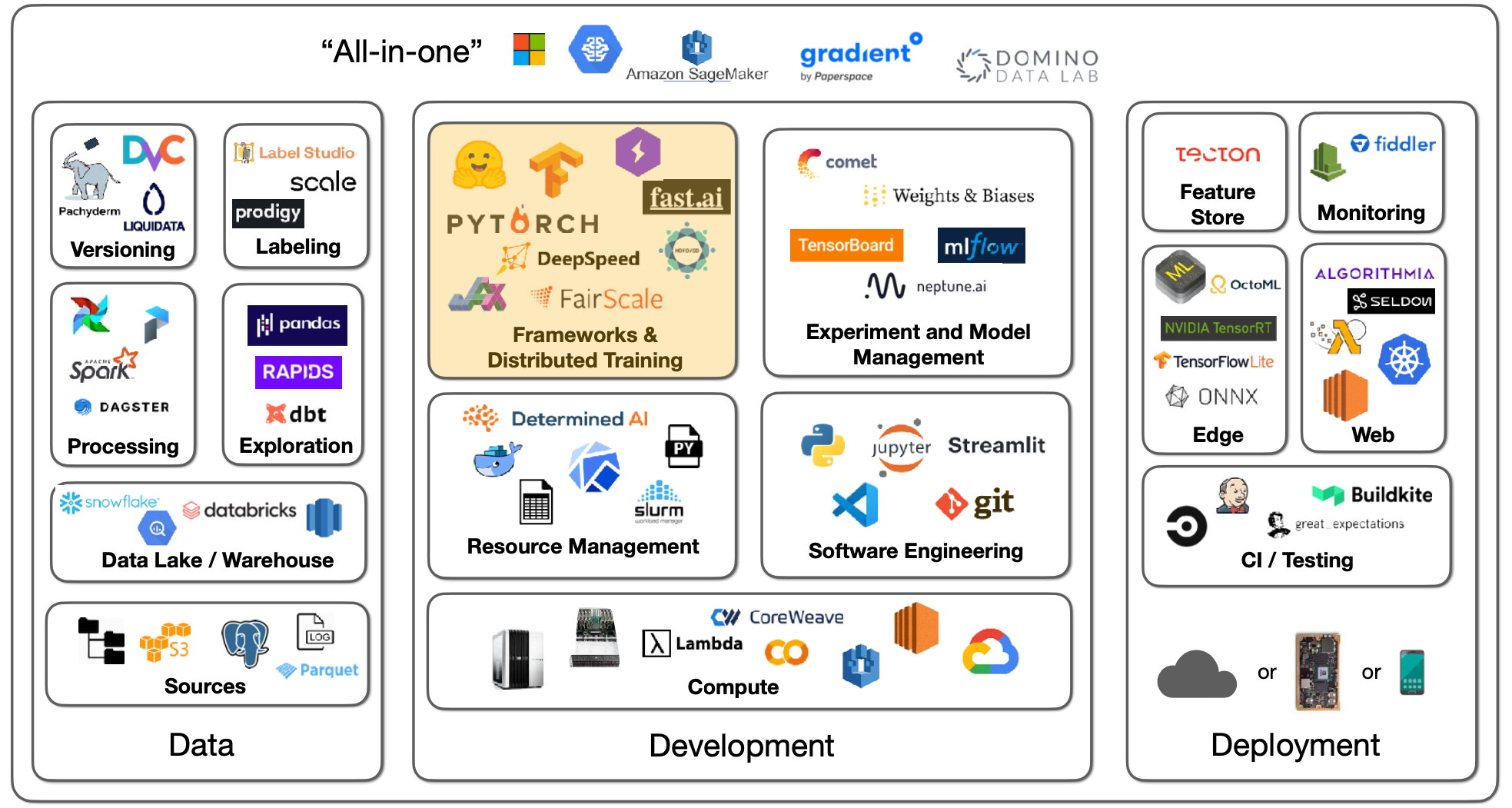
- 딥러닝의 본질적인 요소인 행렬 연산은 사실 Numpy 정도의 라이브러리만으로 해결 가능하다. 하지만 CUDA 를 통한 GPU 자원 활용, 전통적이지 않은 형태의 레이어 구축, 옵티마이저/데이터 인터페이스 활용 등을 위해서는 딥러닝 프레임워크가 필요하다.
-
PyTorch, TensorFlow, Jax 등 다양한 프레임워크들이 존재하며, 모델을 구축 한 후 배포 환경에 따라 최적화된 execution graph 를 찾는다는 점에서 근본적인 작동 원리는 서로 유사하다.
- 강사진은 PyTorch 를 선호하는데, 구현된 모델 수, 연관 논문 수, 대회 수상 모델 수 등에서 압도적인 우세를 보이기 때문이다. 2021년도만 하더라도 ML 대회 우승 모델의 약 77%가 PyTorch 를 사용했다.
- PyTorch 의 경우 TorchScript 등의 파생 제품을 이용하면 실행 속도가 더욱 빨라지며, 분산 처리, 비전, 오디오, 모바일 배포 환경등의 생태계를 이루고 있다.
- PyTorch Lightning 을 PyTorch 와 함께 사용하면 코드를 보다 구조적으로 유지할 수 있으며, 어떠한 하드웨어에서도 코드를 실행할 수 있다. 모델 체크포인팅 등 추가적인 기능 또한 제공.
- TensorFlow 의 경우 브라우저에서 딥러닝을 실행할 수 있는 TensorFlow.js, 쉽게 딥러닝 개발이 가능한 Keras 등의 파생 제품을 가지고있다.
- 이외의 옵션으로는 FasiAI, JAX 등이 있으며, 이들 라이브러리를 사용할 구체적인 이유가 있지않다면 비추천.
-
대부분의 ML 프로젝트는 이미 배포/개발된 모델 구조를 기반으로 시작하게 된다.
- ONNX 는 딥러닝 모델을 저장하는 표준 방식을 제공하는 패키지이며, PyTorch 에서 Tensorflow 등으로의 모델 변환을 가능하게 한다. 잘 작동하는 경우도 있지만, 모든 경우의 수를 감안하지는 못한다.
- Huggingface 는 최근 가장 떠오르는 모델 저장소이다. NLP 라이브러리로 시작했지만, 오디오/이미지 분류 등의 다양한 분야로 확장했으며 약 60,000 개의 사전 학습 모델, 7,500 개의 데이터셋을 제공한다.
- TIMM 은 최신 비전 모델을 중점적으로 제공하는 서비스이다.
Distributed Training
- 다수의 GPU 를 내장한, 다수의 PC 에서 모델 학습이 가능한 환경에 있다고 가정하자. (1) 데이터 배치와 (2) 모델 파라미터 를 GPU 에 분산하여 처리하게 되며, 데이터 배치가 한 개의 GPU 에 저장 가능하거나 그렇지 않을 수도, 모델 파라미터가 한 개의 GPU 에 저장 가능하거나 그렇지 않을 수도 있다.
- 베스트 케이스는 데이터 배치와 모델 파라미터가 모두 한 개의 GPU 에 담길 수 있는 경우이다. 이와 같은 경우를 Trivial Parallelism 이라 부르며, 다른 GPU/PC 에서 독립적인 학습을 수행할 수 있다.
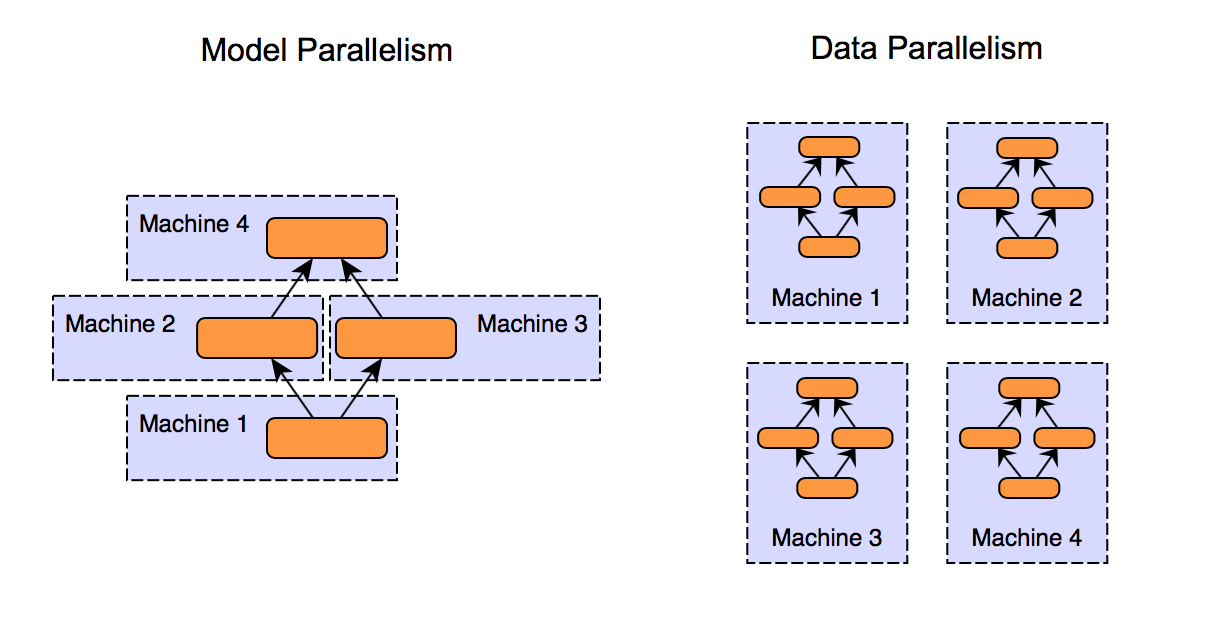
- 모델 파라미터가 한 개 GPU 에 담기나, 데이터 배치가 담기지 않는 경우 Data Parallelism 을 수행할 수 있다. 즉, 단일 배치의 데이터를 여러대의 GPU 에 분산한 후 모델에 의해 연산된 gradient 의 평균값을 구하는 것이다.
- A100 등의 서버 카드를 활용한다며 연산 속도가 선형적으로 증가하며, 3090 과 같은 소비자용 카드 활용시 이보다 효율성이 떨어진다.
- PyTorch 라이브러리는 Data Parallelism 을 구현한 DistributedDataParallel 라이브러리를 제공한다. 써드파티 라이브러리로는 Horovod 같은 옵션이 있으며, PyTorch Lightning 을 활용한다면 이 두 라이브러리 활용이 더욱 쉬워진다. 두 개 라이브러리의 성능은 서로 유사한 편이다.
- 이보다 복잡한 경우는 모델 파라미터가 한 개 GPU 에 담기지 않는 경우인데, 이 경우 대표적으로 세가지의 솔루션, (1) Sharded Data Parallelism, (2) Pipelined Model Parallelism, (3) Tensor Parallelism, 이 존재한다.
-
Sharded Data Parallelism
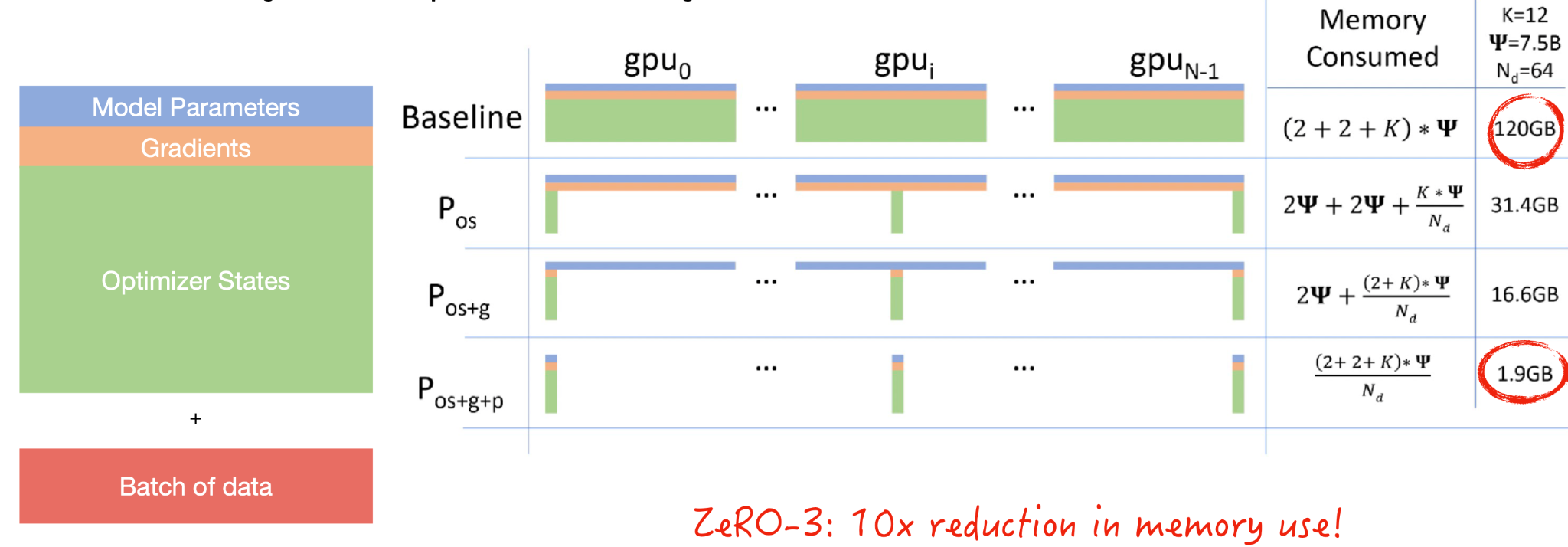
- Sharded 데이터 분산 처리는 GPU 메모리를 차지하는 요소인 (1) 모델 파라미터, (2) 미분값, (3) 옵티마이저 기록, (4) 데이터 배치를 모두 분산하여 다수의 GPU 메모리를 효율적으로 운영하는 방법이다.
- Microsoft 의 ZeRO 라는 방법론으로 처음 고안되었고, 기존 방식과 대비해 약 10배 큰 배치 사이즈를 적용할 수 있다.
- Microsoft DeepSpeed, Facebook FairScale 등의 라이브러리가 존재하며, PyTorch 또한 기본적으로 Fully Sharded DataParallel 기능을 제공한다.
- ZeRO 접근법은 한 대의 GPU 에 적용될 수 있다 (분산된 데이터를 순차적으로 처리).
-
Pipelined Model Parallelism
- 모델의 각 레이어를 개별적인 GPU 에 분산시키는 방식이다. 어렵지 않게 구현이 가능하지만 별도의 패키지를 활용하지 않는다면 각 단계에서 하나의 GPU 만 활용하게 되기에 효율적이지 않다.
- DeepSpeed 와 FairScale 같은 라이브러리는 연산 스케줄링을 통해 모든 GPU 가 한꺼번에 동작하도록 설정이 가능하다.
-
Tensor Parallelism
- Tensor Parallelism 은 연산 대상 행렬을 다수의 GPU 에 분산하는 접근법이다. NVIDIA 에서 배포한 Megatron-LM repo 는 이러한 분산 방식을 Transformer 모델에 적용했다.
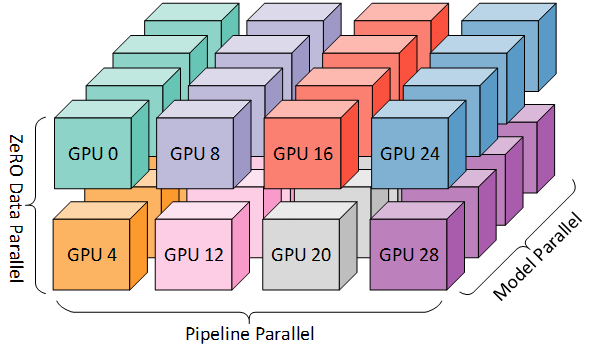
- GPT3 규모의 모델을 핸들링해야 한다면 언급한 3가지의 분산 처리 기법을 함께 사용하는 것 또한 가능하다. 관심이 있다면 BLOOM 학습 관련 자료를 참고.
Compute
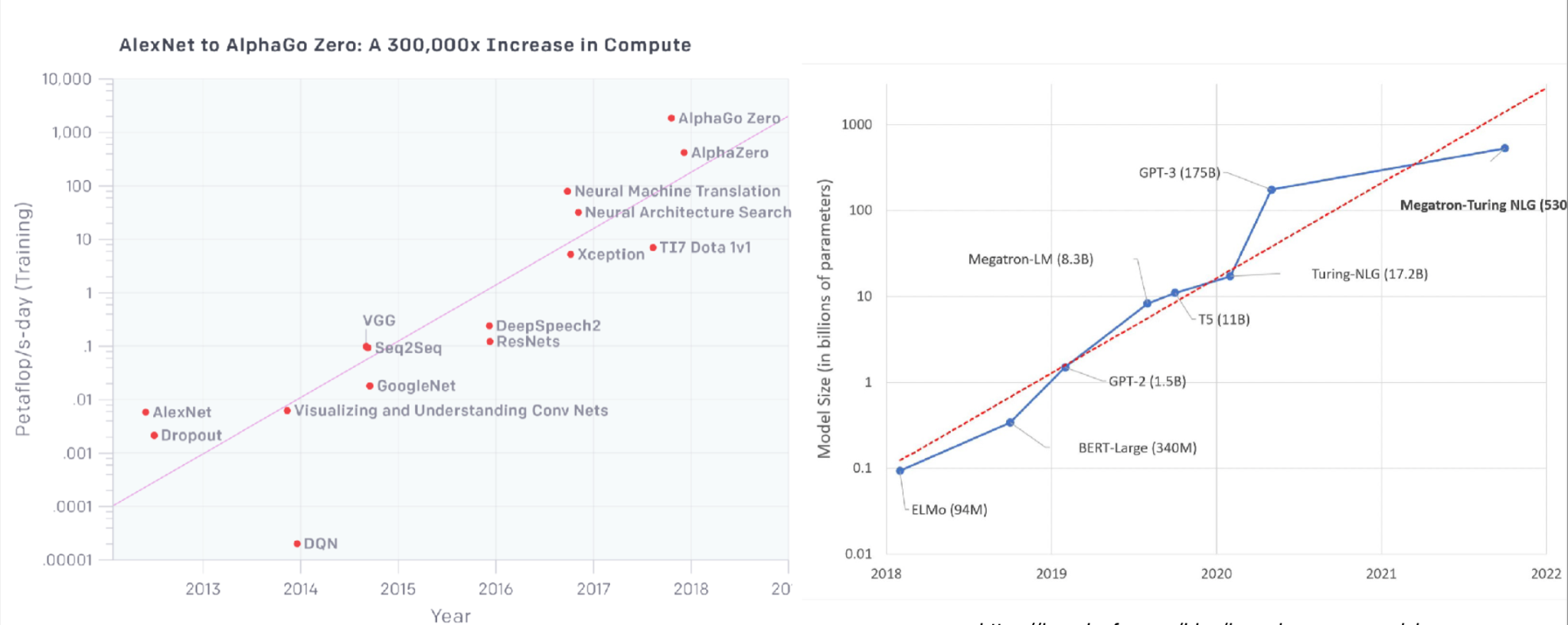
-
지난 10년 간 발전된 ML 모델이 요구하는 연산 자원은 빠른 속도로 성장했다.
-
모델의 효율적인 학습을 위해선 GPU 활용은 필수적이다. 제조사 중 가장 큰 영향력을 행사하는 기업은 NVIDIA 이지만, Google 또한 자체적으로 설계/생산한 TPU 를 Google Cloud 를 통해 제공한다.
-
GPU 를 선택할땐 다음의 3가지 고민이 필요하다
- 한번에 얼마나 많은 데이터를 처리할 수 있는가?
- 데이터를 얼마나 빠르게 처리할 수 있는가?
- CPU 와 GPU 간 통신 속도는 어느정도인가? 다수의 GPU 간 통신 속도는 어느정도인가?
-
개선된 성능의 최신 GPU 구조는 거의 매년 소개되고 있다. 이러한 GPU 들은 소비자용과 기업용으로 나눌 수 있는데, 기업 환경에서는 항상 서버 카드를 사용해야 한다.
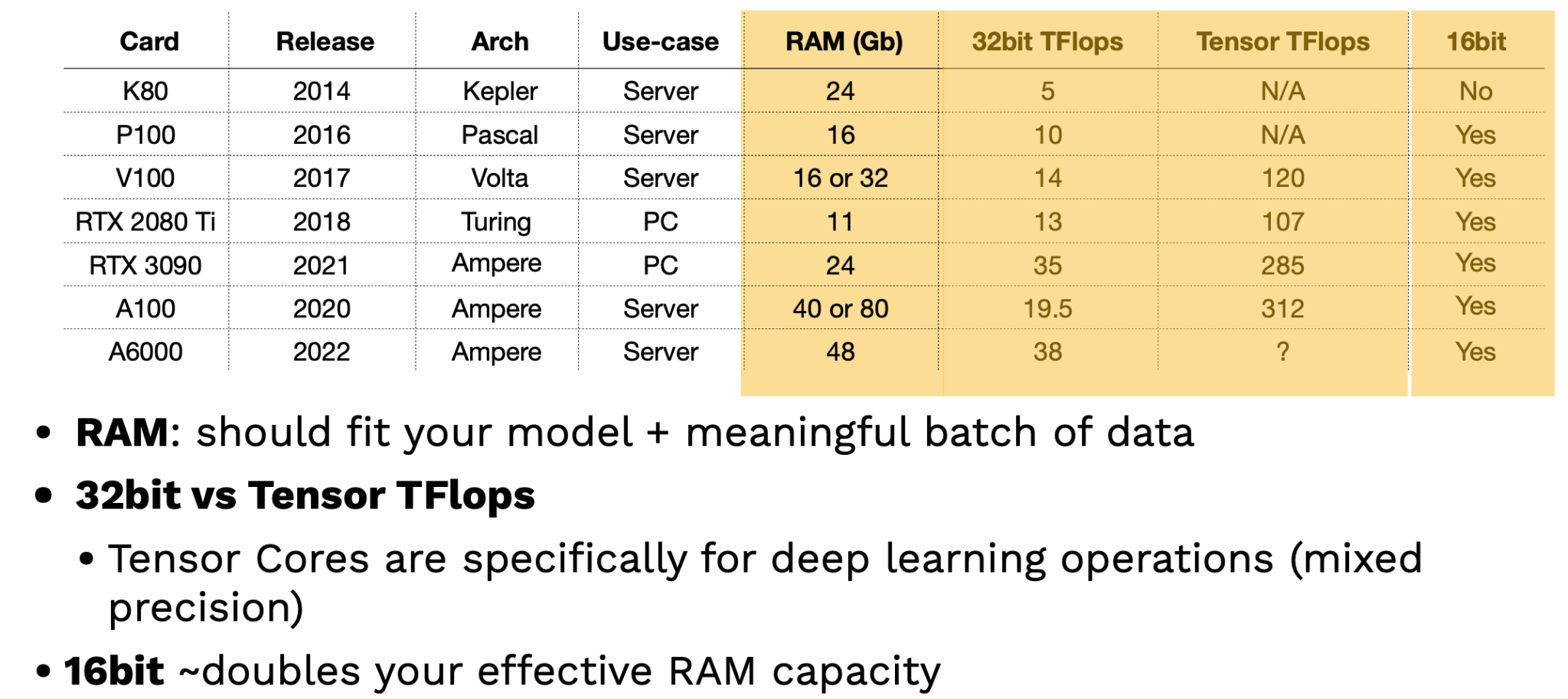
-
GPU 를 평가하는 2가지 중요한 지표는 RAM 과 Tensor TFlops 이다.
- RAM 이 더 큰 GPU 는 상대적으로 더 많은 모델 파라미터와 데이터를 처리할 수 있다.
- Tensor TFlops 란 NVIDIA 에서 개발한 딥러닝 전용 GPU 코어를 뜻한다. Mixed Precision 연산, 즉 연산 성격에 따라 16bit 와 32bit 부동소수점 (floating point) 타입을 적절히 혼용하여 연산 속도와 사용 용량을 개선하는 작업에 최적화 되어있다.
-
Lambda Labs, AIME 과 같은 업체는 실사용 환경에 기반한 벤치마크 자료를 제공한다. NVIDIA A100 은 기존 V100 보다 2.5 배 정도 빠르며, RTX 칩 또한 V100 을 상회하는 성능을 보여준다.
-
대형 클라우드 서비스인 Microsoft Azure, Google Cloud Platfrom, Amazon Web Services 등이 이러한 GPU 연산 자원을 이용할 수 있는 가장 기본적인 장소이며, 유사한 스타트업 서비스인 Paperspace, CoreWeave, Lambda Labs 또한 참고할 만 하다.
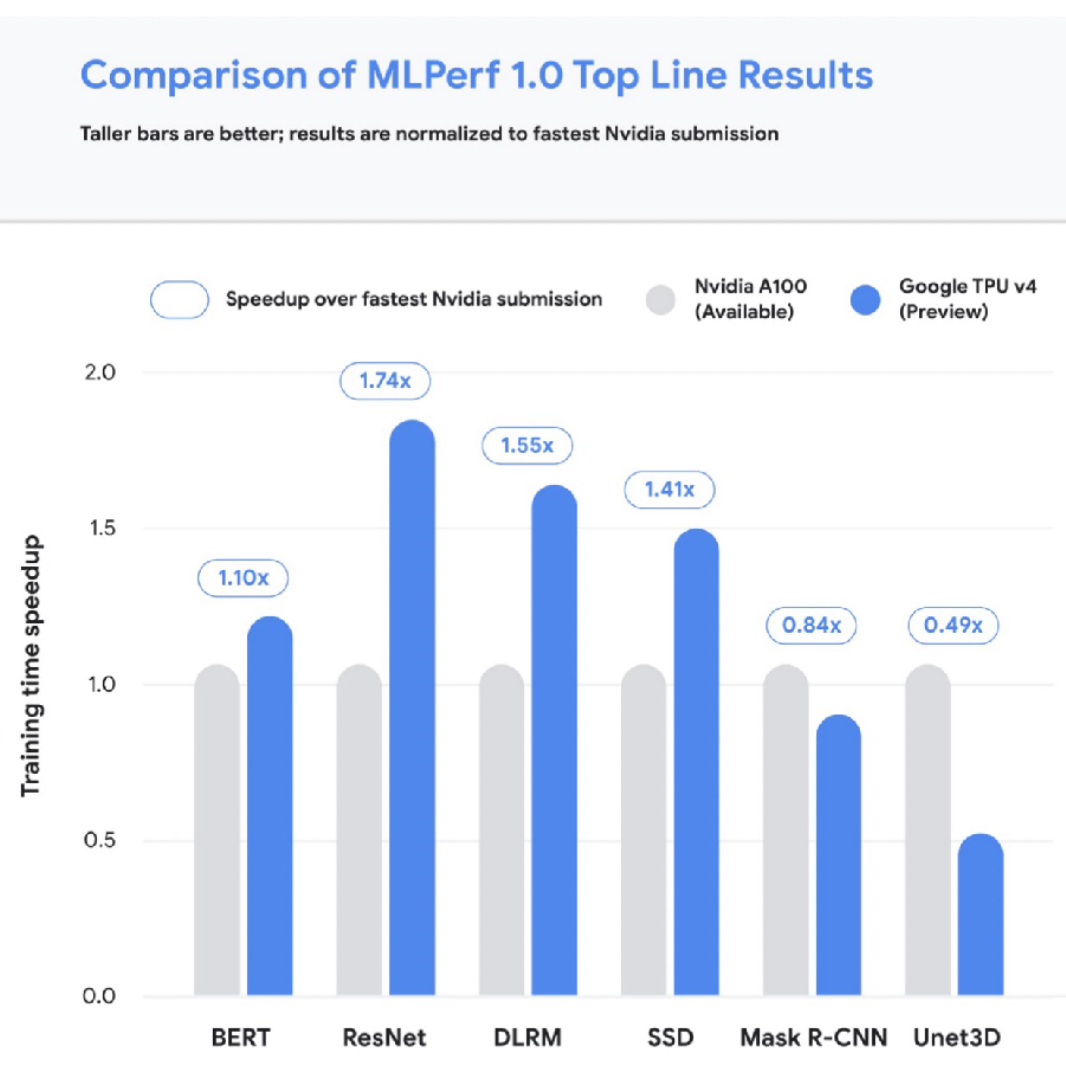
-
TPU 의 경우 현재 4세대 까지 발전한 상태이며, 딥러닝을 위한 최적의 하드웨어이다. 상단의 그래프는 TPU 와 NVIDIA A100 의 성능을 비교한다.
-
클라우드 서비스를 활용한 GPU 가용 비용은 미리 계산하기 까다로운 측면이 있기에 FSDL 팀은 이러한 문제를 해결하기 위한 GPU Cost Metric 툴을 공개했다.
-
성능/비용을 함께 고려했을때 고성능 GPU 는 시간당 비용이 비싸더라도 전체 학습 관점에서 비용을 절감하는 효과를 가질 수 있다. 예를 들어 동일한 트랜스포머 학습 시 4개의 V100 GPU 에서 72시간 동안 1,750 달러의 비용이 발생하지만, 4개의 A100 GPU 에선 8시간 동안 250 달러의 비용만 발생한다. 때문에 무조건 단가가 싼 GPU 를 활용하기 보다는 이러한 비용 절감 요소를 고려해 자원을 선택할 필요가 있다.
-
다음과 같은 룰이 이러한 자원 선택 과정에 도움을 줄 수 있다.
- 가장 저렴한 클라우드 서비스에서 시간당 비용이 가장 비싼 GPU 활용할 것.
- Paperspace 와 같은 스타트업은 메이저 클라우드 사업자 대비 저렴한 비용으로 GPU 자원 제공.
-
온프레미스 자원을 활용한다면 조립 PC 를 구축하거나, NVIDIA 와 같은 제조사에서 판매하는 딥러닝용 PC 를 구매할 수 있다. 128 GB 램, 2개의 RTX 3090 이 탑재된 PC 를 약 7,000 달러 정도에 구축할 수 있으며, 이보다 향상된 성능이 필요하다면 Lambda Labs 에서 판매하는 60,000 달러 학습용 PC 와 같은 옵션이 있다 (8개의 A100 탑재).
-
온프레미스 vs. 클라우드
- GPU 자원을 소유하고 있다면 비용을 최소화한다는 관점보다는 활용도를 최대화한다는 관점에서 문제 접근이 가능하다.
- 스케일 아웃을 지향한다면, 가장 저렴한 클라우드 사업자를 이용하는 편이 맞다.
- 연산 부담이 큰 작업이라면 TPU 활용을 진지하게 고려해야 한다.
Resource Management
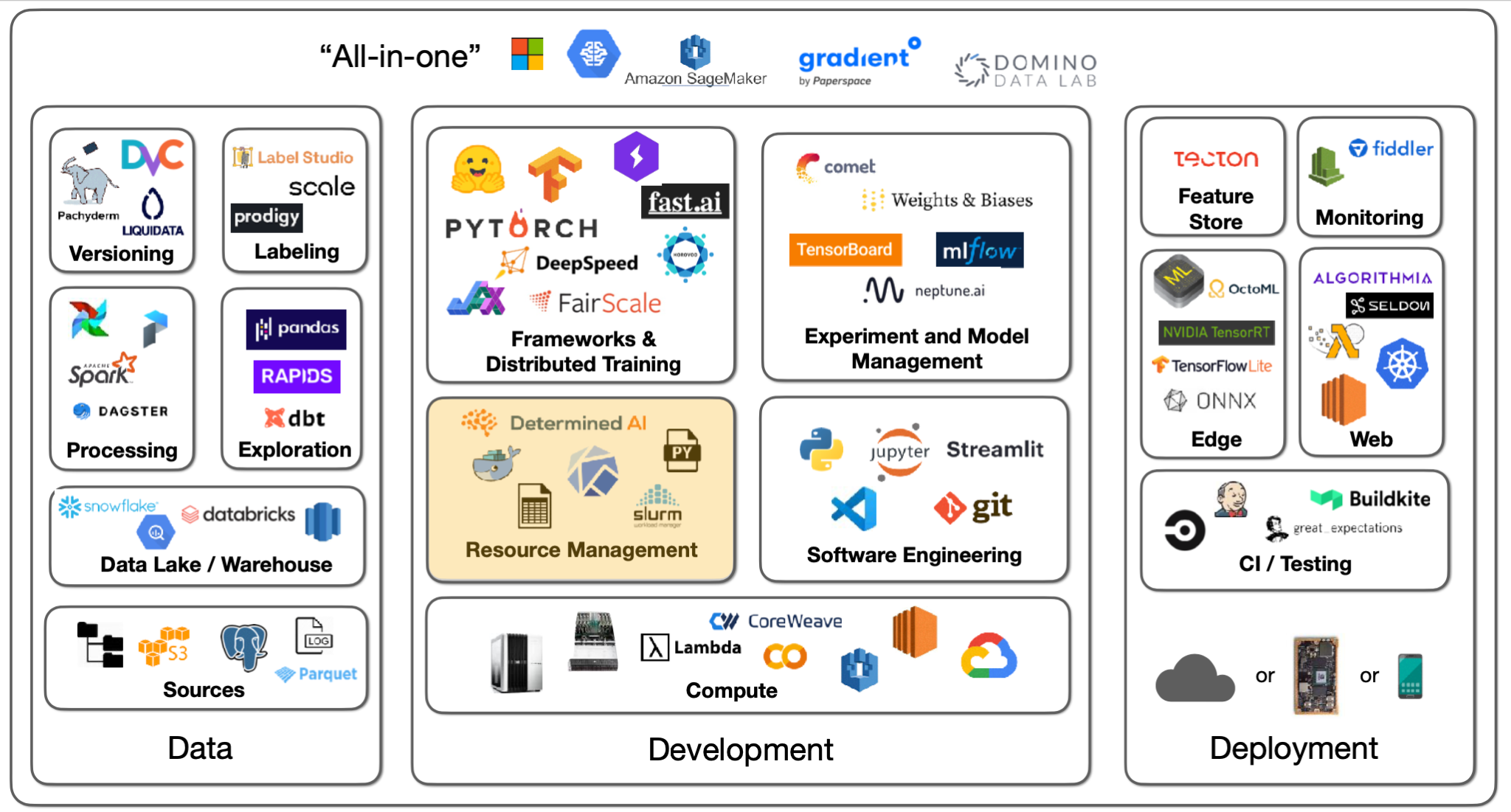
-
다수의 연산 자원이 확보되었다면 해당 자원들을 어떻게 관리/운영 할 것인지에 대한 고민 또한 필요하다.
-
단일 자원 환경에선 poetry, conda, pip-tools 와 같은 패키지 매니저 / 가상환경을 활용해 쉽게 분석 환경을 설정할 수 있다. 이에 반해 다수의 자원을 활용할 때에는 SLURM 과 같은 리소스 매니저 활용이 필요하다.
-
휴대성/이식성을 위해서는 Docker 를 통해 가볍게 모든 디펜던시 스택을 패키징할 수 있다. 자원 클러스터에서 다수의 Docker 컨테이너를 운영하기 위해서는 Kubernetes 와 같은 툴이 필요하며, Kubeflow 는 Kubernetes 에 기반한 ML 프로젝트 운영을 돕는다.
-
자원 클러스터 구축을 위한 옵션은 다음과 같다
- AWS 를 활용한다면 Sagemaker 를 통해 데이터 레이블링 부터 모델 배포 까지의 과정을 모두 마칠 수 있다. Sagemaker 는 AWS 에만 존재하는 많은 설정값을 가진다는 단점이 있지만, 학습을 위한 수많은 학습 알고리즘을 제공하고 있다. 약간의 추가 비용이 발생하지만, PyTorch 또한 점차 지원하고 있는 추세이다.
- Anyscale 의 Ray Train 은 Sagemaker 와 유사한 형태의 자원 클러스터 구축 도구이다. 하지만 비용이 다소 비싸다는 단점이 있다.
- Determined.AI 는 온프레미스와 클라우드 클러스터를 관리하는 툴이다. 분산 학습 등의 기능을 지원하며, 계속 개발이 진행되고 있는 서비스이다.
-
다양한 클라우드 자원을 관리하는 작업은 난이도가 있고, 아직 개선의 여지가 존재하는 영역이다.
Experiment and Model Management
-
연산 자원 관리와는 달리, 학습 모니터링은 체계확립이 거의 완료된 영역이다. 학습 모니터링이란 모델 개발과정에서 변동하는 코드, 모델 파라미터, 데이터 셋에 대한 관리를 뜻하며, 다음과 같은 옵션이 존재한다.
- TensorBoard : 구글이 개발한 단발적인 학습 모니터링 툴이며, 다수의 학습을 체계적으로 관리하기 어려운 측면이 존재.
- MLFlow : Databricks 에서 개발한 모델 패키징, 학습 모니터링 툴이며, self-hosting 이 필수적이다.
- Weights and Biases : 개인적, 학업적 사용은 무료이며, “experiemnt config” 커맨드를 통해 학습 내용을 로그에 기록할 수 있다.
- Neptune AI, Comet ML, Determined AI 또한 연관 기능을 제공.
-
상단에 언급된 다수의 툴은 Hyperparameter Optimization 기능을 제공한다. 모델 튜닝을 효율적으로 수행하는데 도움을 주는데, 예를 들어 Weights and Biases 의 Sweeps 같은 기능이 이 역할을 수행한다.
“All-In-One”
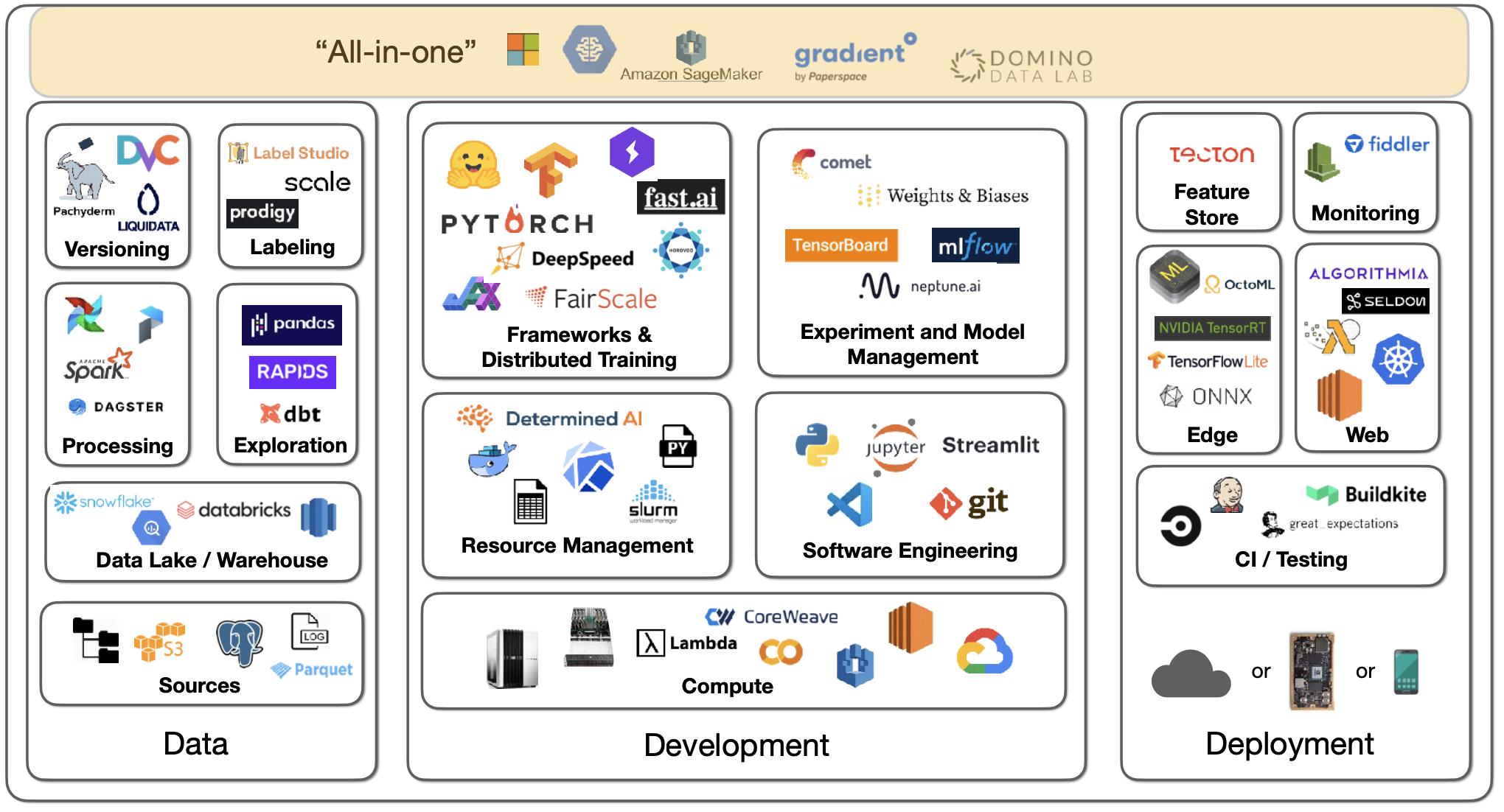
-
학습 모니터링, 분산 처리, 배포, 스케일링 등 언급된 모든 기능을 수행하는 인프라 솔루션 또한 존재하는데, 그 가격이 상당한 편이다.
-
Gradient by Paperspace, Domino Data Lab, AWS Sagemaker 와 같은 옵션이 있다.