
Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
Testing Software
- 테스트란 제품의 버그 발생 빈도를 줄여 더 빠른 배포가 가능하도록 도움을 주지만, 모든 버그를 차단할 수는 없다. 즉, 중요하다고 판단되는 부분에 대해서만 테스트를 작성할 것.
- 린팅 (linting) 툴 적용은 권장되지만, 모든 스타일 가이드를 맹목적으로 지킬 필요는 없다.
- 테스팅, 린팅 워크플로의 자동화 툴 또한 본 강의에서 소개.
1.1 - Tests Help Us Ship Faster. They Don’t Catch All Bugs
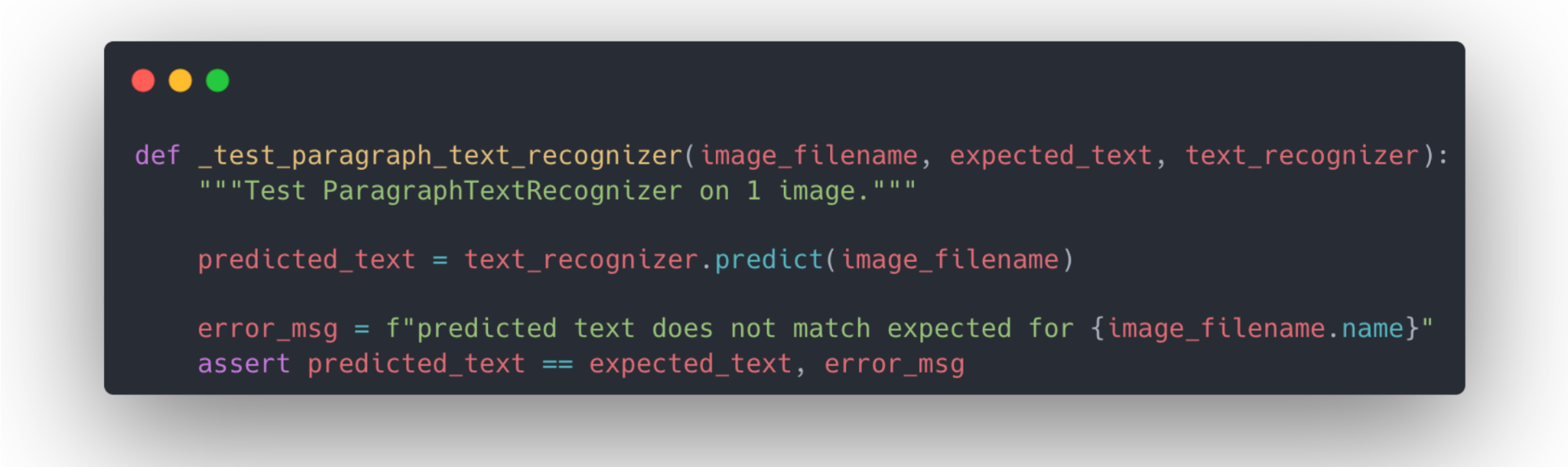
- 테스트란 작성한 코드가 실패할 시 이를 탐지하기 위해 작성된 또 다른 코드이다.
- 테스트가 존재하더라도 모든 버그를 탐지할순 없다. 특히 파이썬과 같은 하이레벨 코드에선 테스트란 단순히 보조적인 역할을 수행하게 된다.
- 또 다른 관점은 테스트를 일종의 분류기로 생각하는 것. 작성된 코드가 버그를 포함하는지 예측하는 모델을 구축한다고 볼 수도 있다.
- 분류 문제와 유사하게 테스트란 True Positive / False Positive 간 밸런스를 잡아줄 필요가 있다. 지나치게 많은 False Positive 를 방지하기 위해선 다음과 같은 질문을 해볼 필요가 있다.
- 작성된 test 가 탐지하는 실제 버그는 무엇인가?
- 버그가 존재하지 않는 경우 test 가 실패하는 경우는 무엇인가?
- 위와 같은 질문을 했을때 1번 질문 보다 2번 질문에 대한 답이 더 많다면 테스트 적용을 다시 한번 고민해 보는 것이 필요하다.
- 모델의 정확도가 특별히 중요한 경우 또한 고려해야 한다. 의료진단, 자율주행, 금융과 같은 경우를 예시로 들 수 있다.
1.2 - Use Testing Tools, But Don’t Chase Coverage
- 파이썬 코드 테스팅을 위한 기본 툴은 Pytest 이다. Test Suite 구분, 테스트간 자원 공유, 파라미터 기반 테스팅 등의 기능을 지원.
- 단순 텍스트 기반 테스트는 자동화가 어렵기 때문에 유지가 어려운 측면이 있다. 하지만 파이썬의 경우 doctest 모듈을 지원하기 때문에 documentation 내 테스팅이 가능.
- 노트북 활용 시, assert 기능과 nbformat 을 활용해 테스팅이 가능하지만, 구현이 지저분한 편.
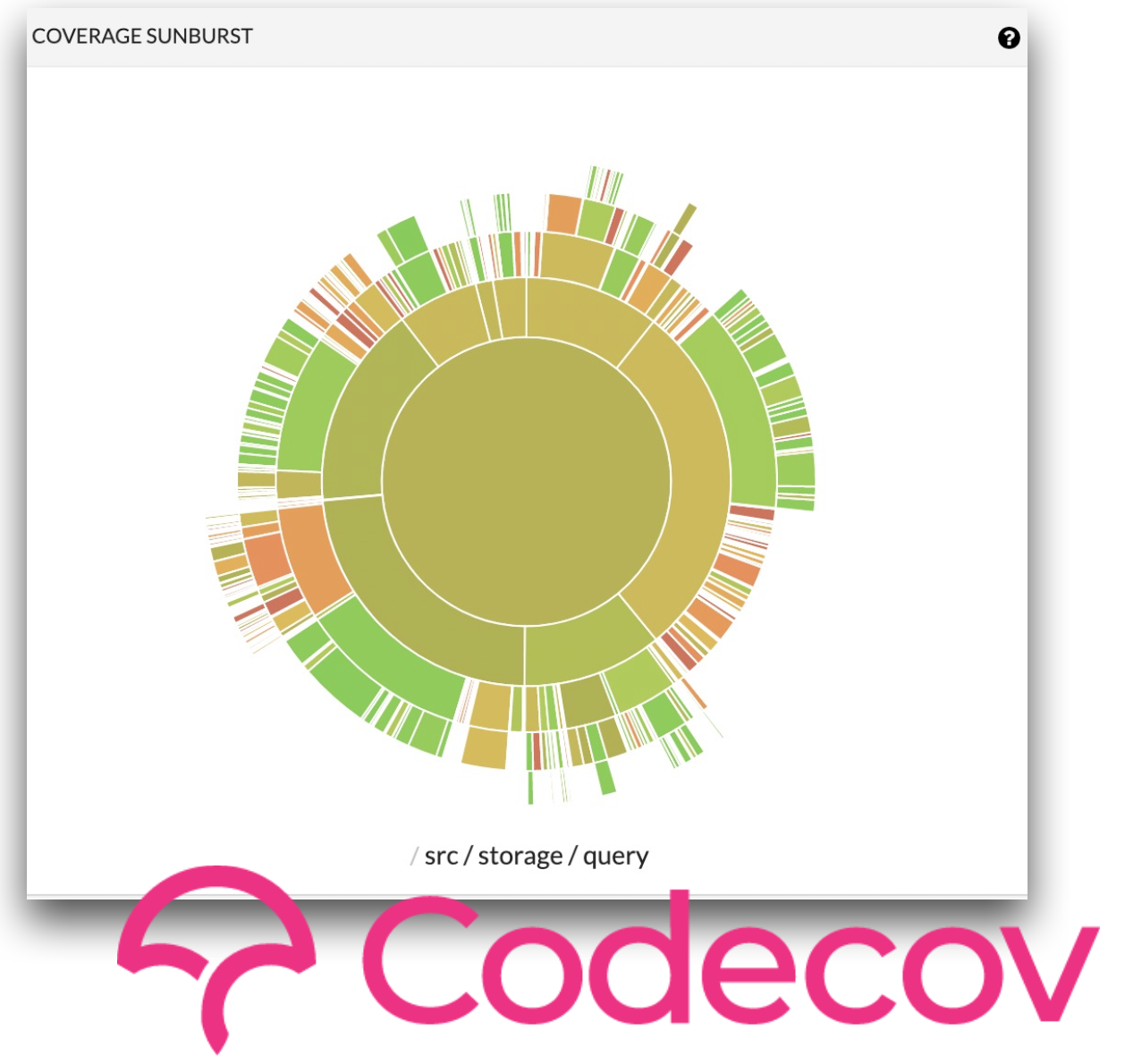
- 코드베이스 규모가 커질수록 테스팅된 코드와 그렇지 않은 코드를 관리하는 일이 복잡해진다. Codecov 란 이러한 코드 테스팅 현황을 시각화해주는 툴.
- Codecov 는 또한 코드의 일정 비율 이상이 테스팅 되지 않으면 commit 을 reject 하는 등의 개발 편의를 위한 기능들을 제공한다.
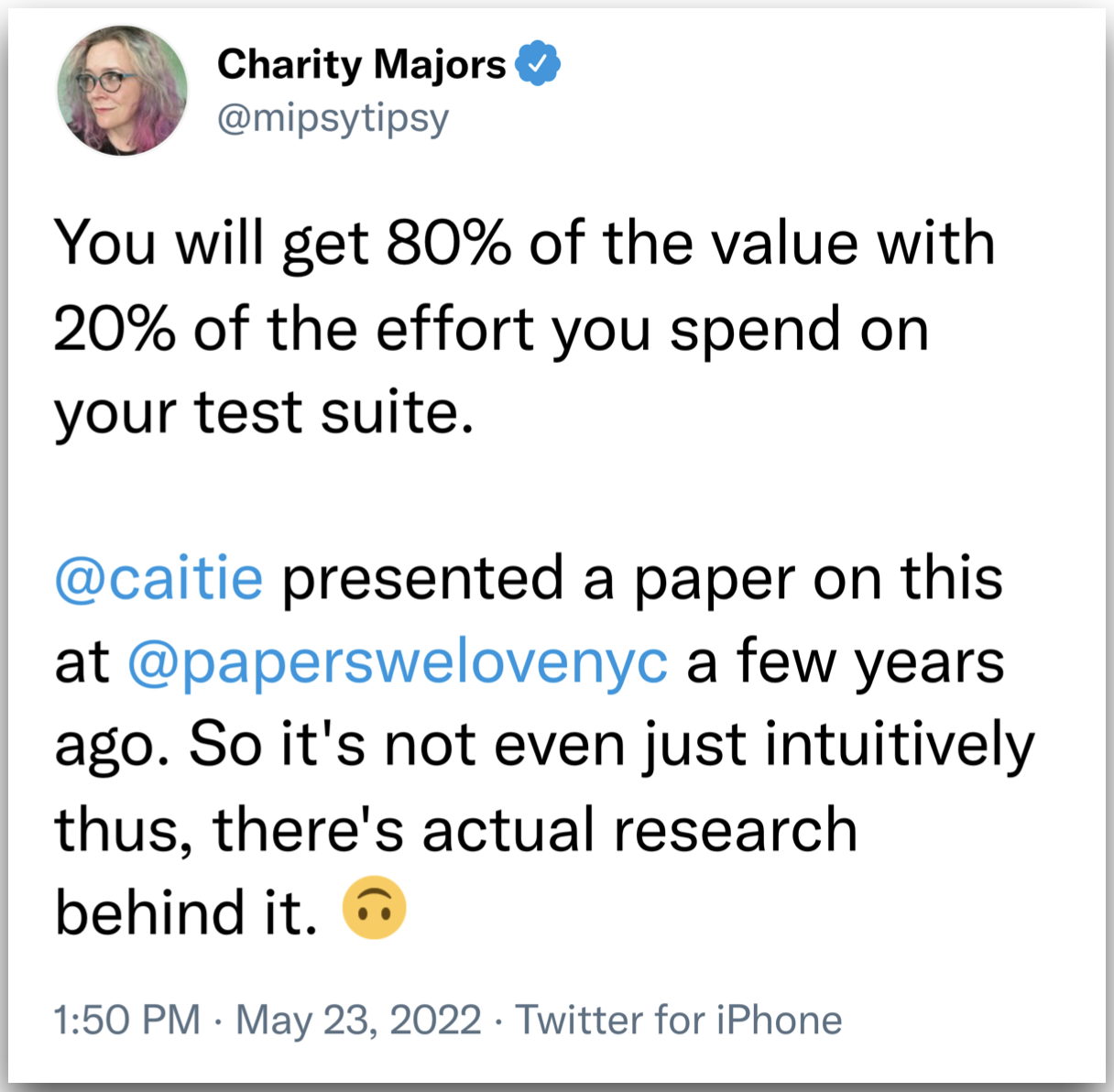
- 이와 같은 커버리지 타겟팅은 사실 강사진은 추천하지 않는 방식이며, 경험/인터뷰/연구에 의하면 의미있는 테스트는 전체 테스트의 아주 작은 부분에 불과하다.
- 엔지니어링 관점에서 가장 효과적인 전략은 의미있는 적은 수의 테스트를 아주 높은 수준으로 구현하는 것. 커버리지 타겟팅을 설정하면 질낮은 테스트를 많이 작성해 커버리지 비율에 집중하게 될 위험성이 높다.
1.3 - Use Linting Tools, But Leave Escape Valves
Clean code is of uniform and standard style.
- 통일된 스타일은 pull request 와 코드 리뷰 단계에서 불필요한 논쟁을 줄일 수 있다. 또한 스타일과 관련된 diff 수를 줄여 버전 컨트롤 시스템 활용도를 높인다.
- 스탠다드 스타일은 오픈소스 기여 시 마찰을 줄이고, 신규 프로젝트에서 새로운 팀 멤버 합류 과정 또한 더욱 매끄럽게 만들어준다.
- Black : whitespace 와 같은 일관된 포맷팅을 위한 툴이다. 기본적으로 자동화가 가능한 영역을 담당하고, 에디터와 자동화 워크플로우에 비교적 문제없이 적용이 가능하다.
- Flake8 : missing docstring 과 같이 자동화가 어려운 영역을 담당하며, docstring completeness, type hinting, security, common bugs 등 영역에서 관련 기능을 제공하는 extension 과 plug-in 을 제공한다.
- Shellcheck : BASH 와 관련된 주요 에러 요인 등을 확인해준다. 실행 속도가 빠르고 에디터에 쉽게 적용할 수 있다.
- 스타일의 무지성적인 적용은 바람직하지 않다. 관련한 문제를 방지하기 위해 강사진은 다음과 같은 방식을 추천
- 적용되는 룰을 목적에 부합하는 수준에서 미니멀하게 유지할 것 (스탠다드 유지, 버전 컨트롤 시스템 활용 등).
- 선택적인 룰 적용. 단계적인 룰 커버리지 상승 (특히 수정이 많이 필요한 큰 기존 코드베이스에 적용할 시).
1.4 - Always Be Automating
- 앞서 설명된 테스팅, 린팅을 업무 환경에 잘 적용하기 위해선 버전 컨트롤 시스템 (VCS) 과의 연동을 통한 자동화가 필요하다.
- VCS 와의 연동은 에러 재현을 가능하게 한다거나, 자동화를 통해 개발자가 본연에 업무에 보다 집중할 수 있다는 등의 장점이 존재한다.
- 인기있는 오픈소스 repository 는 관련된 best practice 를 배울 수 있는 최적의 장소이다 (예. PyTorch Github library).

- PyTorch 가 활용하는 툴은 GitHub Actions 이며, 해당 툴은 VCS 와 연동된 자동화 기능을 제공.
- Pre-commit.ci, CircleCI, Jenkins 와 같은 유사한 기능의 툴이 존재하지만 GitHub Actions 는 현재 오픈소스 커뮤니티에서 가장 활발하게 활용되는 툴이다.
- 버전 관리 내역을 깨끗하게 유지하기 위해선 commit 전 테스팅과 린팅을 로컬 환경에서 구동할 수 있어야 한다. 강사진은 이러한 작업을 위해 pre-commit 을 추천.
- 자동화를 위해선 사용하는 툴을 깊게 이해하고 있어야한다. 예를 들어 Docker 를 단순히 사용할 줄 아는 것은 Docker 를 자동화 할 수 있는 것과 다르며, 제대로된 자동화가 아닌 경우 오히려 생산성을 저하시킬 우려가 존재한다.
- 따라서 자동화는 보다 높은 직급의 개발자가 담당하는 편이 좋으며, 코드의 오너십, 자동화에 대한 의사결정을 필요로 한다.
Testing ML Systems
- ML 테스팅은 어렵지만, 불가능하진 않다.
- 쉬운 작업부터 차근차근 시작할 것.
- 배포 환경에서 테스트를 진행하나, 질낮은 코드를 배포하지는 않을 것.
2.1 - Testing ML Is Hard, But Not Impossible
- 테스팅 개념이 발전된 영역은 소프트웨어 엔지니어링 분야이다. 소프트웨어 엔지니어링은 코드를 배포하는 과정이지만, ML 은 학습을 통해 데이터와 모델을 결합하며, 따라서 다음과 같은 어려움을 동반한다.
- 데이터는 소스 코드 보다 무겁고, 검증이 어렵다.
- 데이터는 보다 복잡하고, 명확한 정의를 가지고있지 않다.
- 데이터는 컴파일된 프로그램에 비해 빈약한 디버깅, 검증 툴 셋을 가지고있다.
- 본 섹션은 Smoke Testing 개념에 집중하며, 이는 구현이 쉽고 효과적이다.
2.2 - Use Expectation Testing on Data
- 데이터에 대한 테스팅은 기본적인 속성에 대한 검증으로부터 시작한다. null 이 존재하지 않는 컬럼, 시작일 이전의 마감일 등 데이터에 대한 기본적인 기대치에 대한 검증을 진행하는 식.

- 강사진은 이와 같은 작업을 위해 great_expectations 라이브러리를 추천한다. 본 툴은 데이터 질에 대한 리포트를 자동으로 생성하며, logging, alerting 등의 기능 또한 지원.

원활한 작업 진행을 위해서는, 가능한 모델러와 데이터 간 거리를 좁히는 편이 좋다.
- 첫째 방안은 프로젝트 시작 시 모델 개발자가 임의로 데이터를 레이블링 하는 것.
- 하지만 더 많은 개발자가 팀에 들어오고, 데이터 레이블링을 진행한 개발자가 다른 일에 착수하며 관련된 정보는 필연적으로 유실된다. 이보다 나은 솔루션은 모델 개발자와 주기적으로 소통하는 데이터 레이블링 조직을 운영하는 것.
- 최적은 방안은 모델 개발자들이 순차적으로 레이블링 작업을 진행하는 것이다. 이러한 방식을 통해 모델 개발자는 데이터에 대한 이해와 전문성을 높일 수 있다.
2.3 - Use Memorization Testing on Training
- 암기는 가장 단순한 형태의 학습이다. 특히 딥러닝의 경우 데이터를 암기하는 작업을 특히 잘 수행하기 때문에 전체 데이터셋의 일부분을 잘 암기하는지 확인하는 것 만으로 학습이 원활하게 이루어지는지 확인할 수 있다.
- 이러한 방식으로 확인 가능한 이슈는 아주 심각할 확률이 높다. 예를 들어 gradient 계산이 제대로 이루어지지 않거나, numerical type 이슈가 존재하거나, 레이블이 섞여있는 등.
- 보다 작은 규모의 문제 확인을 위해서는 학습에 소요되는 런타임을 확인하는 것이 좋다. 기대 수준의 성능을 달성하기 까지 소요되는 배치 수가 갑자기 증가한다면, 학습 과정에서 버그가 발생했을 가능성이 있다.
- PyTorch Lightning 은 이러한 작업을 위해 overfit_batches 기능을 제공.
- Memorization 테스팅 개발 시에는 실행 속도를 염두해두어야 한다. 잦은 테스팅을 위해 실행 속도가 빨라야하며, 10분 이내의 테스팅 타음으로 모든 PR, 또는 코드 변경 후 실행하는 편이 좋다.
- 실행 속도 개선을 위해서는 다음 이미지 참조 - 이러한 아이디어들은 여러 시나리오에 따른 학습 결과를 사전에 확인할 수 있는 방법이기도 함.

- 또 다른 테스팅 방법은 이전과 동일한 조건의 학습을 새로운 코드로 실행하는 것. 자주 수행이 가능하지는 않지만, 학습 파이프라인에서 예기치 못하게 발생한 문제를 바로 확인할 수 있다.
- 이러한 방법의 주된 단점은 학습에 필요한 많은 리소스이다. CircleCI 와 같은 CI (Continuous Integration) 플랫폼은 GPU 활용에 많은 비용을 청구하며, GitHub Actions 는 관련 기기 접근에 많은 제약이 있다.
- 가장 좋은 방법은 배포 환경에서 새로 유입되는 데이터를 활용해 주기적인 학습을 진행하는 것. 여전히 많은 리소스가 소요되지만, 실제 모델 개선에 직접적으로 기여하며 관련 작업을 위해 data flywheel 을 필수적으로 구축하게 된다.
2.4 - Adapt Regression Testing for Models
- 모델은 하나의 함수로 규정할 수 있다 - 기본적으로 인풋에 의한 아웃풋을 출력하기 때문. 따라서 보통의 함수와 같이 regression testing (코드 변경 전후, 동일한 인풋에 대한 아웃풋 출력을 대조하는 방법) 을 통한 코드 검증이 가능하다.
- Regression testing 은 분류기와 같은 보다 단순한 모델에 가장 적합하며, 구조가 복잡한 경우 또한 적용이 조금 어려울순 있지만 배포 과정에서 도움을 줄 수 있다.
- 보다 우아한 테스팅 방법은 손실값과 모델 지표를 활용한 test suite 작성이다.
- 하기 test-driven development (TDD) 코드 작성 패러다임 (테스트 작성 후 코드를 작성하는 방식, 코드에 기인한 테스트 작성을 방지함으로서 테스트가 본연에 역할에 보다 충실할 수 있다) 과 유사한데, 일정 수준의 손실값을 사전에 정의한 후, 모델이 정의된 성능을 보일때 까지 개발을 진행하게 된다.
- 하지만 손실값 threshold 기반의 테스팅은 에러 발생의 원인을 특정할 수 없기 때문에 TDD 와 완전한 동일 선상에서 볼 수는 없다.
- 이와 같은 문제를 보완하기 위해서 손실값이 가장 크게 발생한 데이터를 면밀히 살펴볼 필요가 있다. 이러한 데이터들을 하나의 세트로 모은 후 해당 세트를 기반으로 별도의 테스팅을 진행할 수도 있는데, 이에 따른 이점은 (1) 모델이 개선 가능한 영역을 확인할 수 있으며 (2) 데이터 자체의 문제 또한 찾을 수 있다는 점 (레이블 오류 등).
- 특이 데이터 확인 시에는 타입별로 데이터를 묶는 작업이 필요할 수 있다. 자율운행을 예시로 들자면 주위 환경이 너무 어두운 경우, 앞유리에 빛반사가 발생한 경우 등을 그룹핑.
- 이러한 방법을 통해 모델 개선시 동일한 문제가 발생하지 않는지 확인하는 작업이 가능하다.

- 꽤나 손이 많이 가는 작업인데, 별도 레이블링 팀과의 협업 등을 통해 효율 개선이 가능한 부분. Domino, Checklist 와 같이 이러한 문제를 별도 ML 모델로 해결하는 방법 또한 존재한다.
2.5 - Test in Production, But Don’t YOLO
- 테스트는 실제 배포 환경에서 진행되어야 한다. 특히 ML 분야의 경우 배포 환경과 개발 환경 간 데이터 유사성을 담보하기 어렵기 때문에 배포 환경 내 테스팅이 중요.
- 또한 배포 환경 테스팅을 위해서 구축하게 되는 툴과 인프라는 실제 배포 문제가 발생했을때 이를 해결하는데 활용될 수 있다.

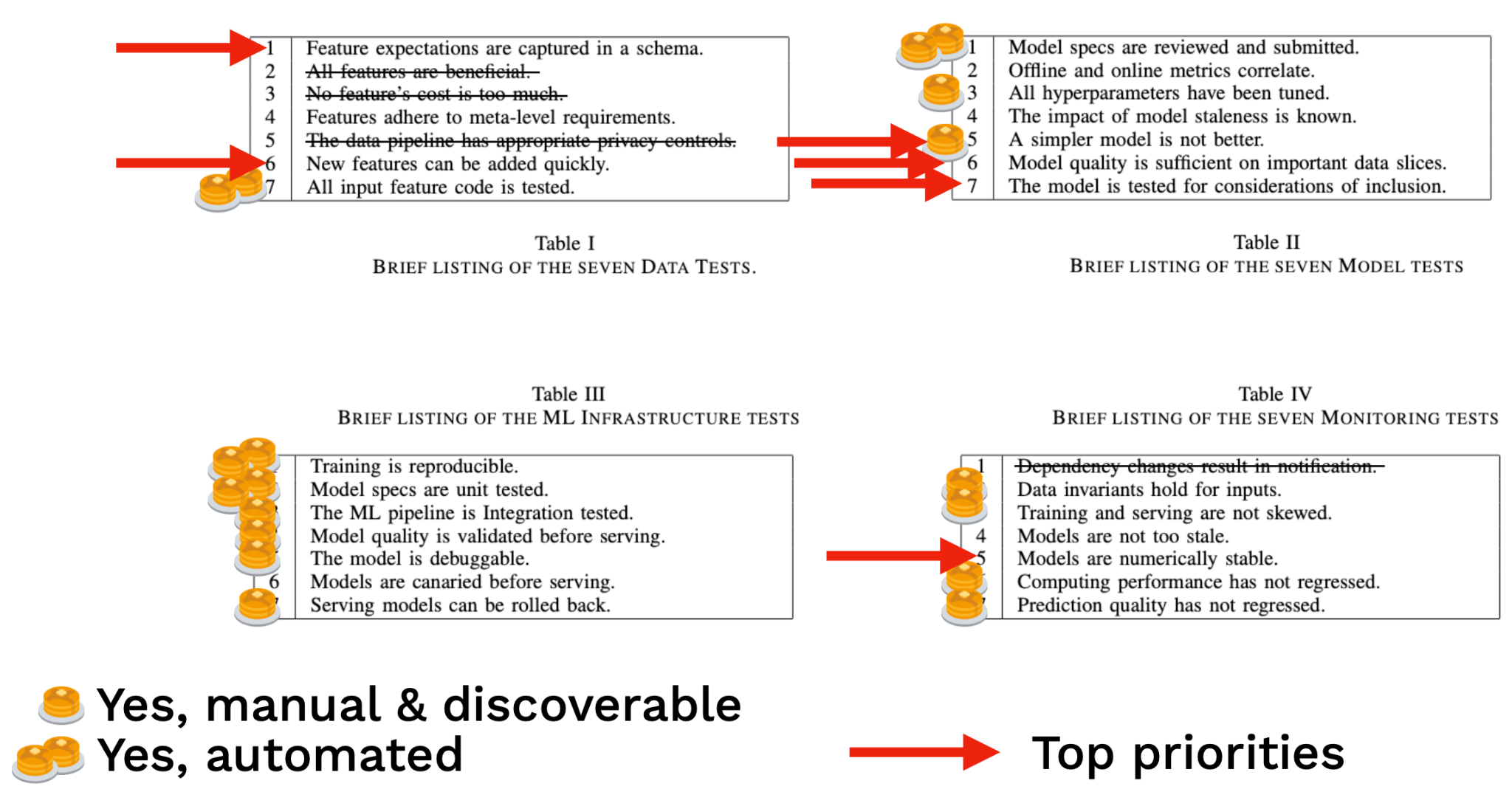
2.6 - ML Test Score
- 코드베이스가 커지고, 팀이 성숙해가며 단순한 smoke testing 보다 완전한 형태의 테스팅이 필요해질 수 있다. 이러한 예시 중 하나가 ML Test Score.
- ML Test Score 는 구글 ML 개발팀에서 발전한 평가기준인데, 데이터, 모델, 학습, 인프라, 배포 모니터링 등의 영역을 객관적으로 평가할 수 있도록 한다.

- 해당 방법은 기준치가 매우 높고, 영역이 광범위하다. 강사진이 개발한 모델 조차 몇개의 영역에서 기준에 미치지 못하기 때문에 일종의 참고 자료로 활용하는 것이 좋다.
Troubleshooting Models
- 테스팅은 잘못된 부분을 찾도록 돕지만, 트러블슈팅은 실제 잘못된 부분을 고치는 과정이다. ML 트러블슈팅이란 다음과 같은 순차적 방법론으로 정의할 수 있다.
- Make It Run - 자주 발생하는 에러를 방지해 모델이 작동하도록 할 것.
- Make It Fast - 비효율성을 개선해 모델이 빠르게 동작하도록 할 것.
- Make It Right - 검증된 구조와 보다 방대한 데이터 활용으로 올바른 모델을 구축할 것.
3.1 - Make It Run
- 세단계의 과정 중 가장 쉬운 단계이다. 모델 실행을 막는 버그는 아주 일부분에 불과한데, 이러한 버그들은 미리 내용을 숙지한 후 사전에 방지하는 편이 좋다.
- 첫번째 타입은 shape error, 즉 행렬 연산 과정에서 행렬의 크기가 맞지 않는 경우이다. 이러한 에러를 방지하기 위해 개발 과정에서 예상되는 텐서의 크기를 중간 중간 코드 내에 적어주는 것이 좋다.
- 두번째 타입은 메모리 에러이다. GPU 에 비해 지나치게 큰 용량의 텐서를 처리할 시 발생되며, 이를 예방하기 위해서는 가능한 낮은 precision 을 활용할 것 (주로 16비트 precision).
- 다른 원인은 지나치게 많은 데이터, 혹은 배치 사이즈. PyTorch Lightning 내 autoscale batch size 기능을 활용해 방지 가능하며, 이로도 해결이 어렵다면 tensor parallelism, gradient checkpoint 등의 옵션을 검토.
- NaN, Infinite 등의 값이 텐서 내 발생하는 경우 또한 학습 실패로 이어질 수 있다. 주로 gradient 발생 후, 모델에 전파되는 형태이며 PyTorch Lightning 은 이러한 이슈 트래킹을 위한 기능을 제공.
- 주로 Normalization Layer 에서 발생하며, 64 비트 float 적용 시 문제가 해결될 수 있다.
3.2 - Make It Fast
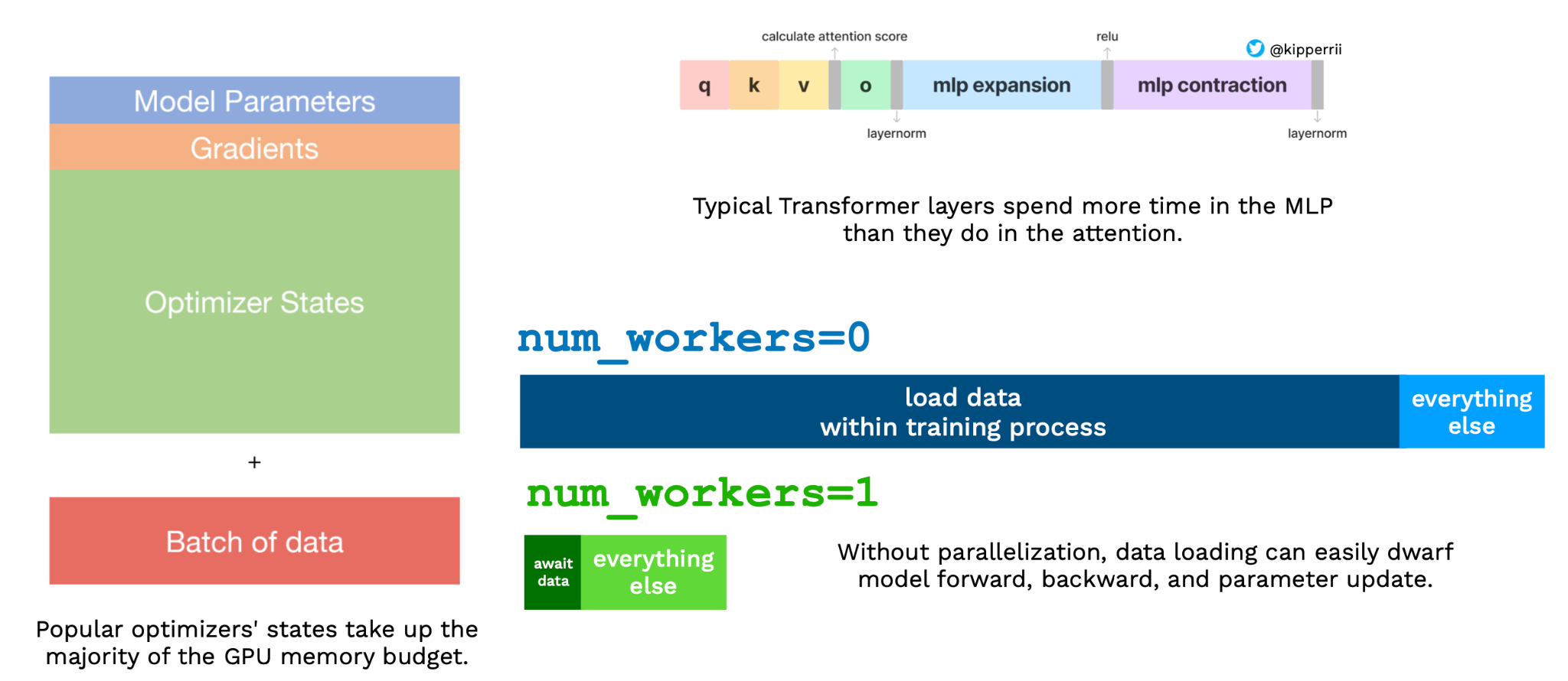
- 모델이 정상적으로 작동한다면, 이후 실행 속도 개선이 필요하다.
- DNN 의 경우 실행 속도와 관련해 직관적이지 않은 부분이 다소 존재하는데, 예시적으로 트랜스포머 모델 내 MLP 레이어 실행 속도가 Attention 레이어 실행 속도보다 느리거나, 데이터 로딩 등에 상당한 시간이 소요될 수 있다.
- 이러한 이슈를 해결하기 위해서 가장 좋은 방법은 단순히 코드를 재점검하는 것. 관련해 아주 작은 코드 변화도 큰 효과를 가져올 수 있다.
3.3 - Make It Right
- 기존 소프트웨어와는 다르게 ML 모델은 태생적으로 완벽할 수 없다.
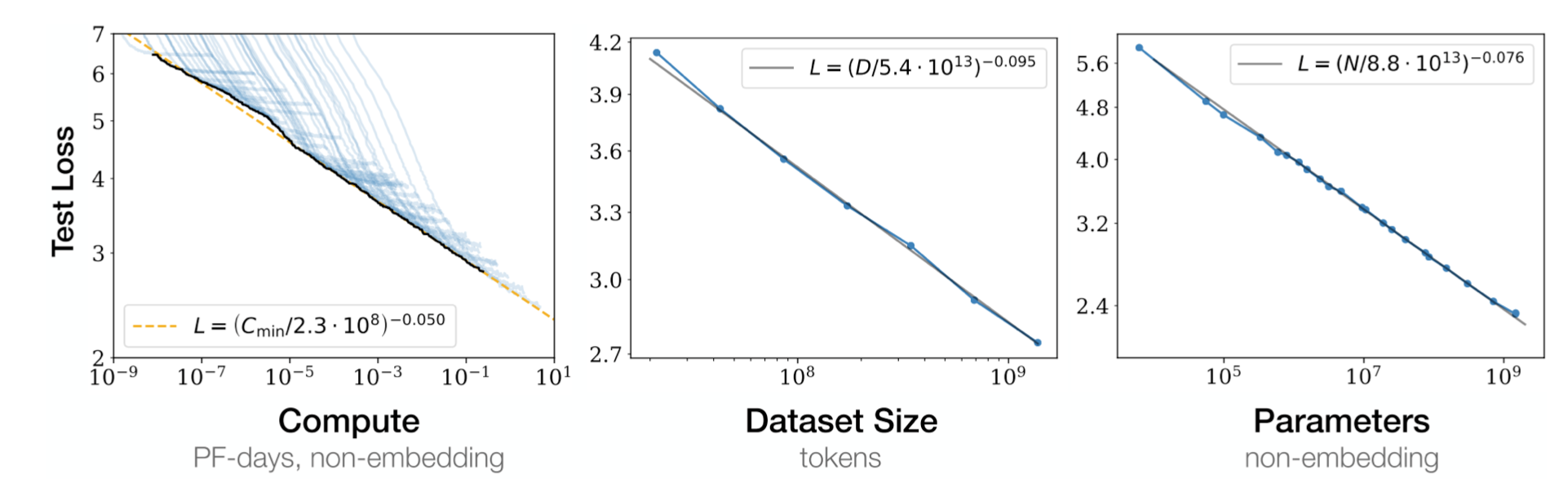
- 하지만 모델/데이터 스케일링을 통해 모델은 상당한 성능 개선을 보일 수 있는데, OpenAI 리서치에 의하면 스케일링에 의한 장점은 명확히 측정될 수 있고, 리소스, 데이터 사이즈, 파라미터 수 등에 기반해 예측될 수 있다.
- 직접적인 스케일링이 어렵다면, finetuning 을 검토.
- 언급된 조언보다 세부적인 사항들은 모델과 관련 과제 마다 많은 차이가 있을 것. 가능하면 이미 존재하는 모델 구조와 하이퍼파라미터 등을 활용하는 편이 좋다.