Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
Introduction
-
ML 분야가 발전되기 시작한 초기 단계에 업계가 잘 이해하지 못했던 부분은 데이터와의 접점이다. 데이터셋을 만들고, 분석하고, 전처리하는 등의 과정은 ML 프로젝트 전반에 걸쳐 필수적이다.
-
4주차 강의의 핵심 내용은 다음과 같다.
- 초도 분석에 원하는 것보다 10배 많은 시간을 할애해야 한다.
- 데이터를 고치고, 추가하고, 증강하는 것이 대체로 성능 향상에 가장 크게 기여한다.
- 데이터를 다루는 과정을 가능한 간단하게 유지할 것.
Data Sources
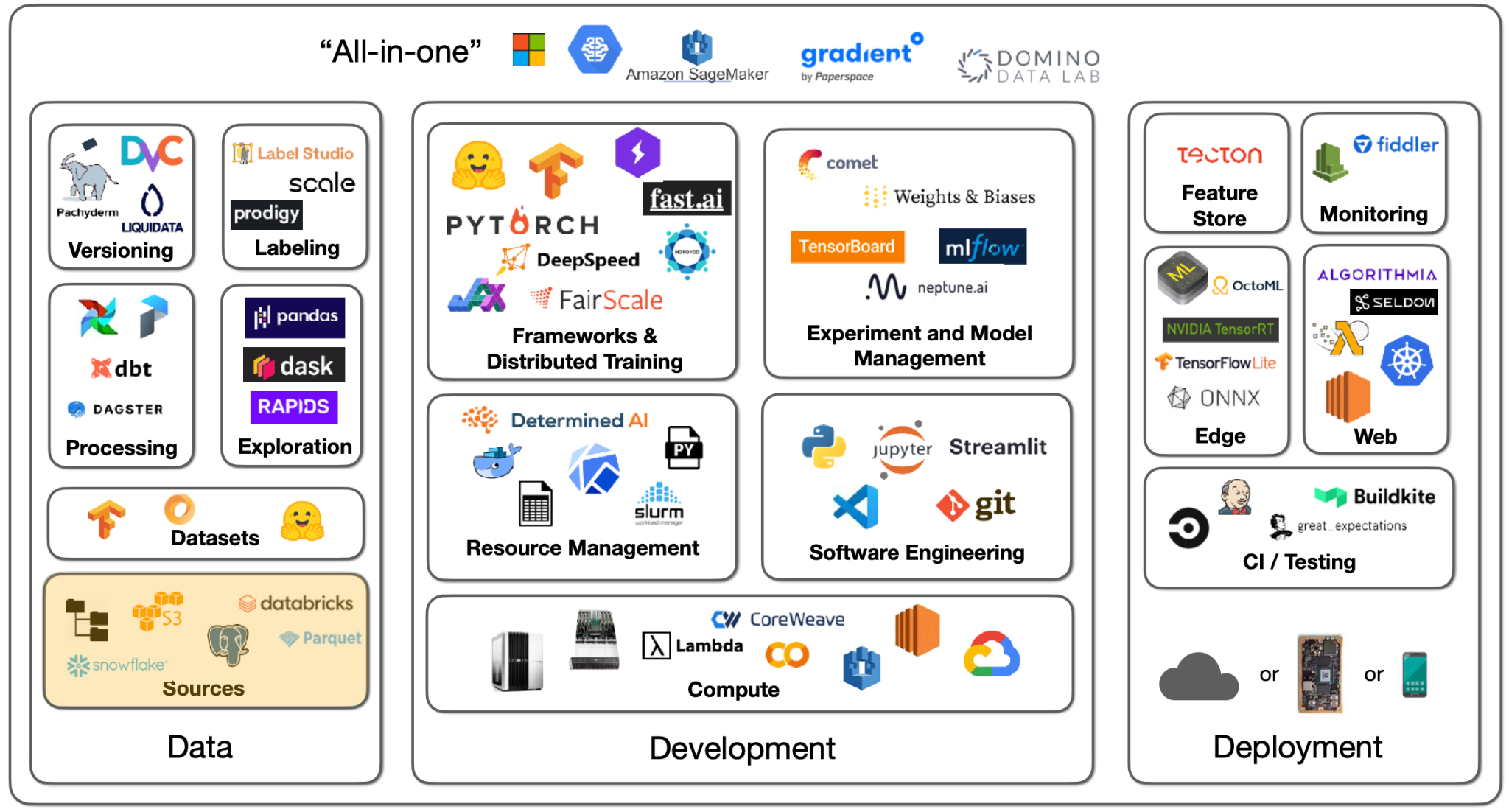

- 이미지, 텍스트, 로그, 데이터베이스 등 데이터 원천의 종류는 다양하다. 딥러닝을 위해서는 GPU 자원이 있는 로컬 파일 시스템에 데이터를 옮겨와야하며, 이렇게 학습 데이터를 옮기는 방식은 다루는 데이터 마다 차이가 생긴다.
- 이미지의 경우 S3 등의 오브젝트 스토리지에서 직접 다운로드 받을 수 있다.
- 텍스트의 경우 분산 처리를 통해 데이터를 분석하고, 일부분을 발췌해 로컬 환경으로 옮겨주는 등의 과정이 필요하다 (원문 전달 내용이 조금 불확실함).
- 로그와 데이터베이스의 경우 데이터 레이크를 활용해 데이터를 모으고, 처리할 수 있다.
-
파일시스템
- 파일시스템이란 “파일” 이라는 기초 단위에 기반한 추상화 개념이다. 파일이란 흔히 생각하듯 텍스트, 바이너리 등 다양한 형태를 취할 수 있으며, 버전의 개념을 가지지 않는다.
- 파일시스템은 보통 사용하는 기기에 연결된 디스크에 저장되며, 연결의 개념은 물리적일 수도, 온프레미스, 클라우드, 혹은 분산시스템에 기반한 원격 연결을 의미할 수도 있다.
- 디스크 성능을 평가하는데 가장 중요한 요소는 속도와 대역폭이다. 저장장치 포맷은 주로 HDD 와 SSD 로 나뉘어지며, 동일한 SSD 이더라도 SATA 와 NVMe 연결방식 간 약 100배의 속도차이가 발생한다.
-
오브젝트 스토리지
- 오브젝트 스토리지란 파일시스템 활용을 위한 API 를 뜻하며, 가장 기본이 되는 단위는 이미지, 오디오, 텍스트 등의 바이너리 형태 “오브젝트” 이다.
- 버저닝, 중복 저장 개념이 존재하며, 로컬 파일시스템에 비해서는 속도가 느리지만 클라우드 활용을 위해서는 충분.
-
데이터베이스
-
데이터 웨어하우스
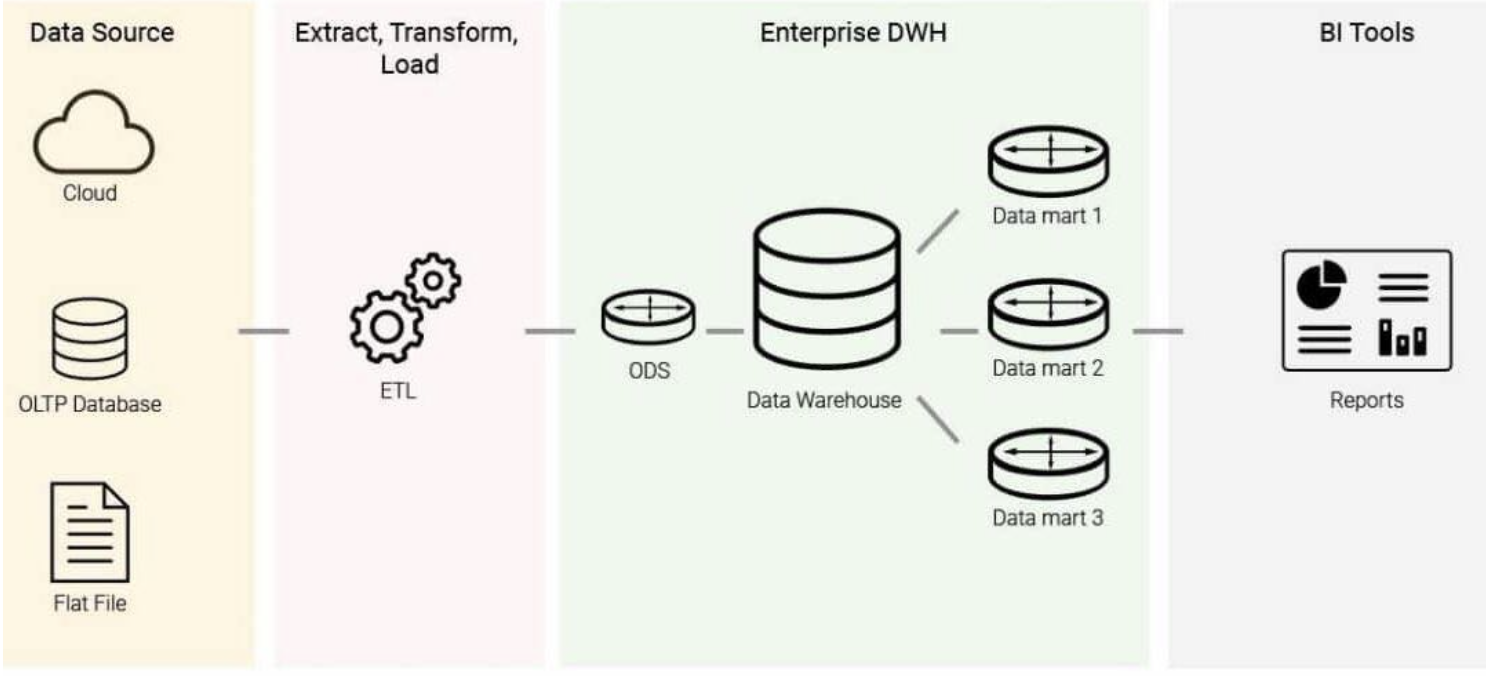
- 데이터베이스가 온라인 트랜잭션 처리 (OLTP) 를 위해 설계되었다면, 데이터 웨어하우스를 온라인 분석 처리 (OLAP) 을 위해 설계된 데이터 처장 체계이다.
- OLTP : 네트워크 상의 여러 이용자가 실시간으로 DB 의 데이터를 갱신하거나 조회하는 등의 단위작업 처리 방식. Row-oriented, 즉 개별적인 정보에 중점을 둠.
- OLAP : 데이터를 분석하고 유의미한 정보로 치환하거나, 복잡한 모델링을 가능하게끔 하는 분석 방법. Column-oriented, 즉 통계적인 정보에 중점을 둠.
- 데이터 웨어하우스로 여러 데이터를 끌어오는 작업을 ETL (Extract-Transform-Load) 이라 칭하며, 비즈니스 관점의 의사결정을 위한 정보를 웨어하우스에서 끌어오게 된다.
- 데이터베이스가 온라인 트랜잭션 처리 (OLTP) 를 위해 설계되었다면, 데이터 웨어하우스를 온라인 분석 처리 (OLAP) 을 위해 설계된 데이터 처장 체계이다.
-
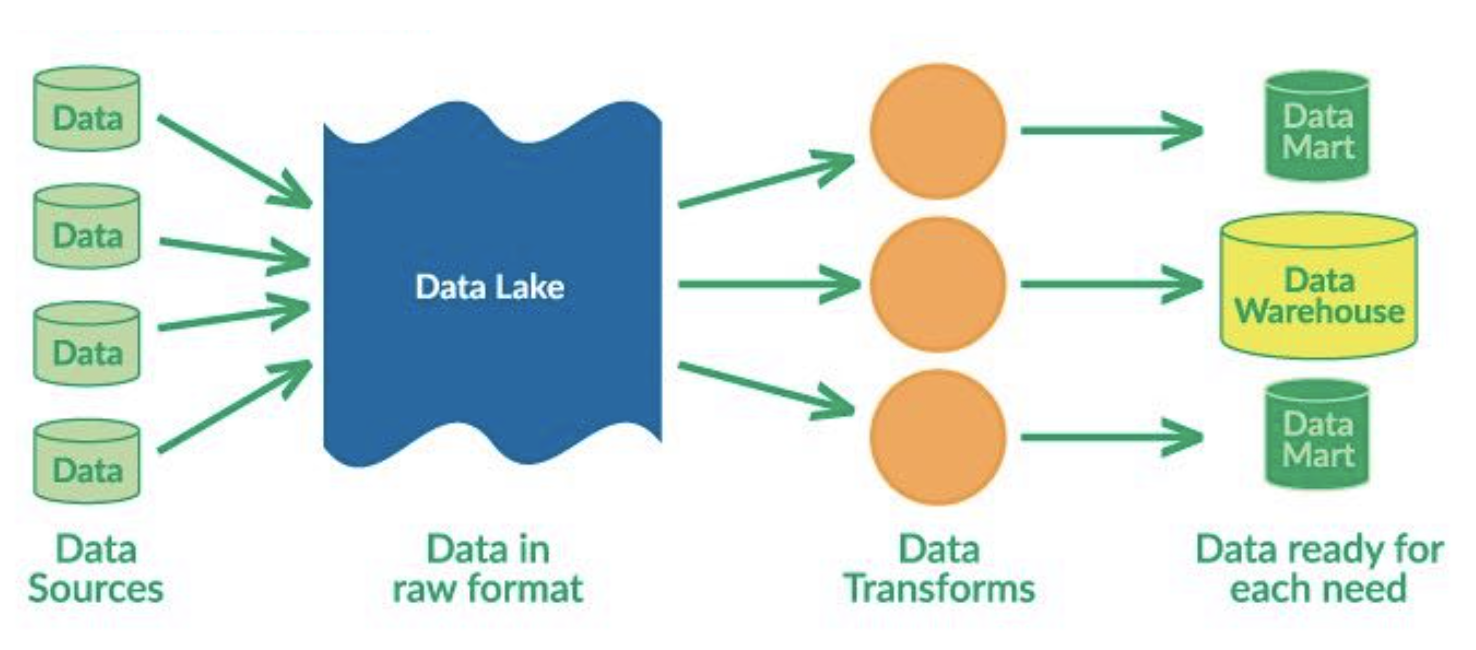
데이터 레이크
- 데이터 웨어하우스와 유사하나, 데이터를 사전에 가공하는 ETL 방식과 달리 일단 데이터를 모으고, 사용시 가공하는 ELT (Extract-Load-Transform) 방식을 사용한다.
-
최근 트렌드는 데이터 웨어하우스와 데이터 레이크를 통합하는 솔루션들이다. 정형 데이터와 비정형 데이터가 같은 저장소에서 다뤄질 수 있으며, Snowflake 와 Databricks 등의 업체가 분야를 선도하고 있다.
-
분야에 관심이 있다면 Designing Data-Intensive Applications 라는 책을 추천.
Data Exploration
-
데이터 탐색은 주로 SQL 과 DataFrame 을 활용해 수행한다.
-
SQL 은 정형 데이터를 다루는 기본적인 인터페이스이며, 수십년간 사용되고 발전되어왔다. RDBMS 등의 트랜잭션 기반 데이터베이스에서 주로 활용.
-
Pandas 는 Python 생태계에서 사용되는 주된 DataFrame 이며 SQL 과 유사한 작업을 수행할 수 있다. OLAP 등의 분석 기반 환경에서 주로 활용.
-
DASK DataFrame 은 Pandas 작업을 여러개의 CPU 코어에서 분산 처리 할 수 있도록 돕는다. RAPIDS 는 동일한 분산 처리 작업을 GPU 에서 수행.
Data Processing
-
데이터 처리는 예시와 함께 설명하는 편이 좋다.
-
SNS 플랫폼에 업로드되는 사진을 기반으로, 사진의 인기도를 예측하는 모델을 매일 학습하는 상황이라고 가정하자. 모델러는 다음과 같은 데이터를 활용하게 된다.
- 데이터베이스 내 메타데이터 (업로드 시간, 제목, 장소 등)
- 로그 데이터 기반 유저 정보 (로그인 횟수 등)
- 별도 분류 모델 기반 사진 정보 (컨텐츠, 스타일 등)
-
따라서 최종적인 모델 학습이 진행되기 전, 데이터베이스 쿼리 작업, 로그 처리 작업, 모델 예측 작업 등 많은 데이터 처리 작업이 수행되어야 하며, 이러한 사전 작업을 정해진 순서대로 처리해야 할 필요가 생긴다.
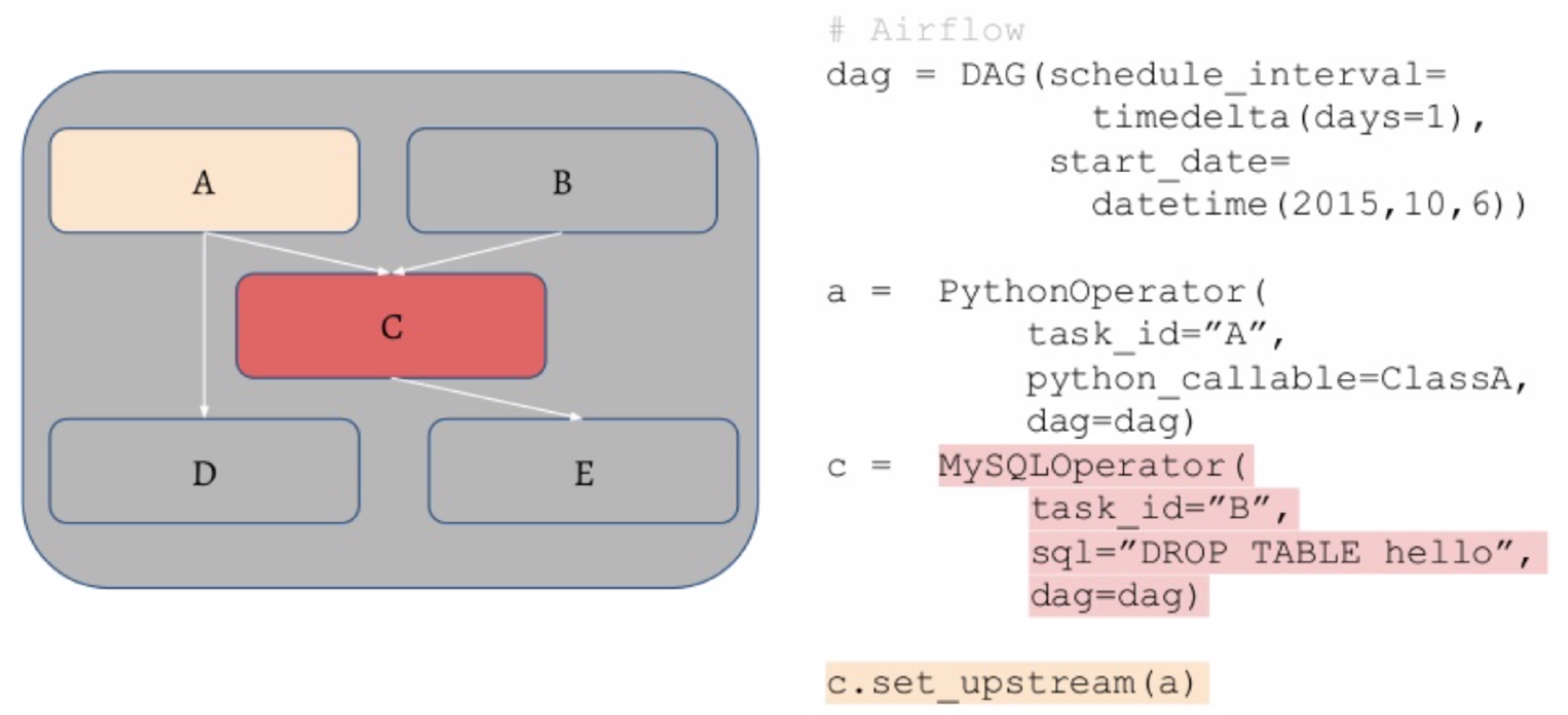
-
Airflow 는 언급된 기능을 수행하는 Python 생태계의 기본 스케줄러 툴이다. DAG (Directed Acyclic Graph) 라는 개념을 활용해 순차적인 작업 설정이 가능하며, 이러한 작업이란 SQL 쿼리, Python 함수 등 다양한 종류가 있다.
Feature Store
-
데이터 처리 과정이 모델 학습과 병렬로 진행될 떄, 모델은 이후 학습에서 어떤 데이터가 신규로 생성되었는지, 어떤 데이터가 이미 학습에 활용되었는지 등을 파악할 필요가 발생할 수 있다 (필수적인 요소는 아님).
-
이러한 경우 Feature Store 기능을 활용한 데이터 관리가 필요해지게 된다.
-
Feature Store 라는 개념은 Uber 의 ML 플랫폼 Michalengelo 를 소개하는 이 글에서 처음 등장했다. Uber 의 시스템 특성상 학습은 오프라인, 예측은 온라인으로 진행되기에 두 과정의 싱크를 맞춰줄 필요가 생겼고, 이를 해결하기 위한 수단으로 Feature Store 개념을 사용.
-
Tecton 은 해당 분야에서 가장 널리 사용되는 SaaS 솔루션이며, 이외에도 Feast, Featureform 등의 옵션이 존재.
Datasets
-
HuggingFace Datasets 는 ML 학습에 특화된 8000+ 데이터셋을 제공하며, 비전, NLP 등 분야가 다양한 편이다. 호스트된 Github-Code 데이터를 예시로 들자면 데이터 핸들링을 돕기 위해 Aparche Parquet 형태로 스트림 할 수 있기 떄문에 1TB+ 용량의 전체 데이터를 다운로드 할 필요가 없다.
-
또다른 훌륭한 데이터셋의 예시로는 RedCaps 를 들 수 있다. Reddit 에서 수집된 12M 의 이미지-텍스트 페어를 제공.
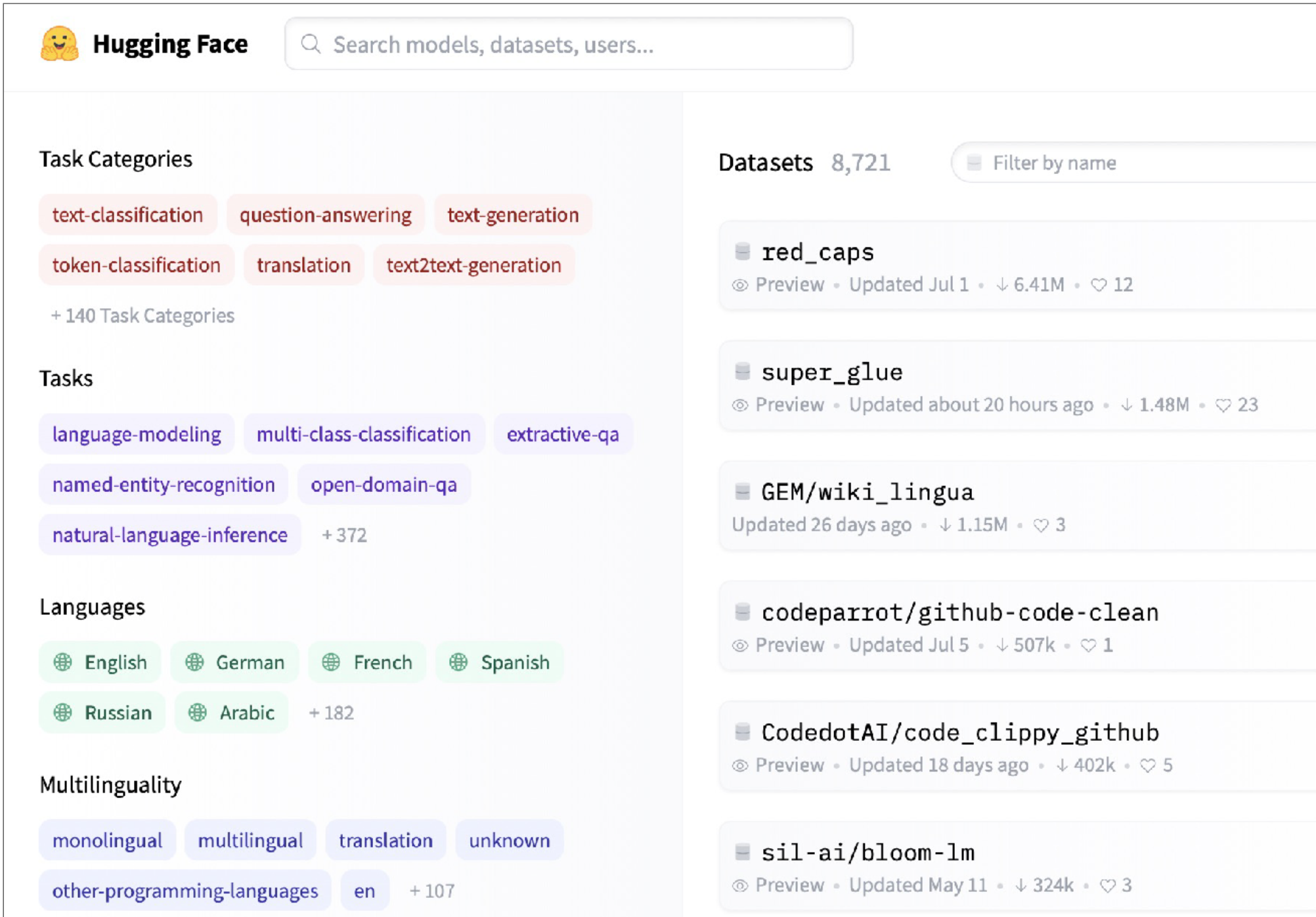
- HuggingFace Datasets 와 유사한 서비스로는 Activeloop 이 있는데, 데이터 다운로드 없이 분석과 기타 데이터 활용이 가능하도록 돕는다.
Data Labeling
-
데이터 레이블링 작업을 시작하기 전, 정말 레이블링이 필요한지를 스스로에게 물어볼 필요가 있다.
-
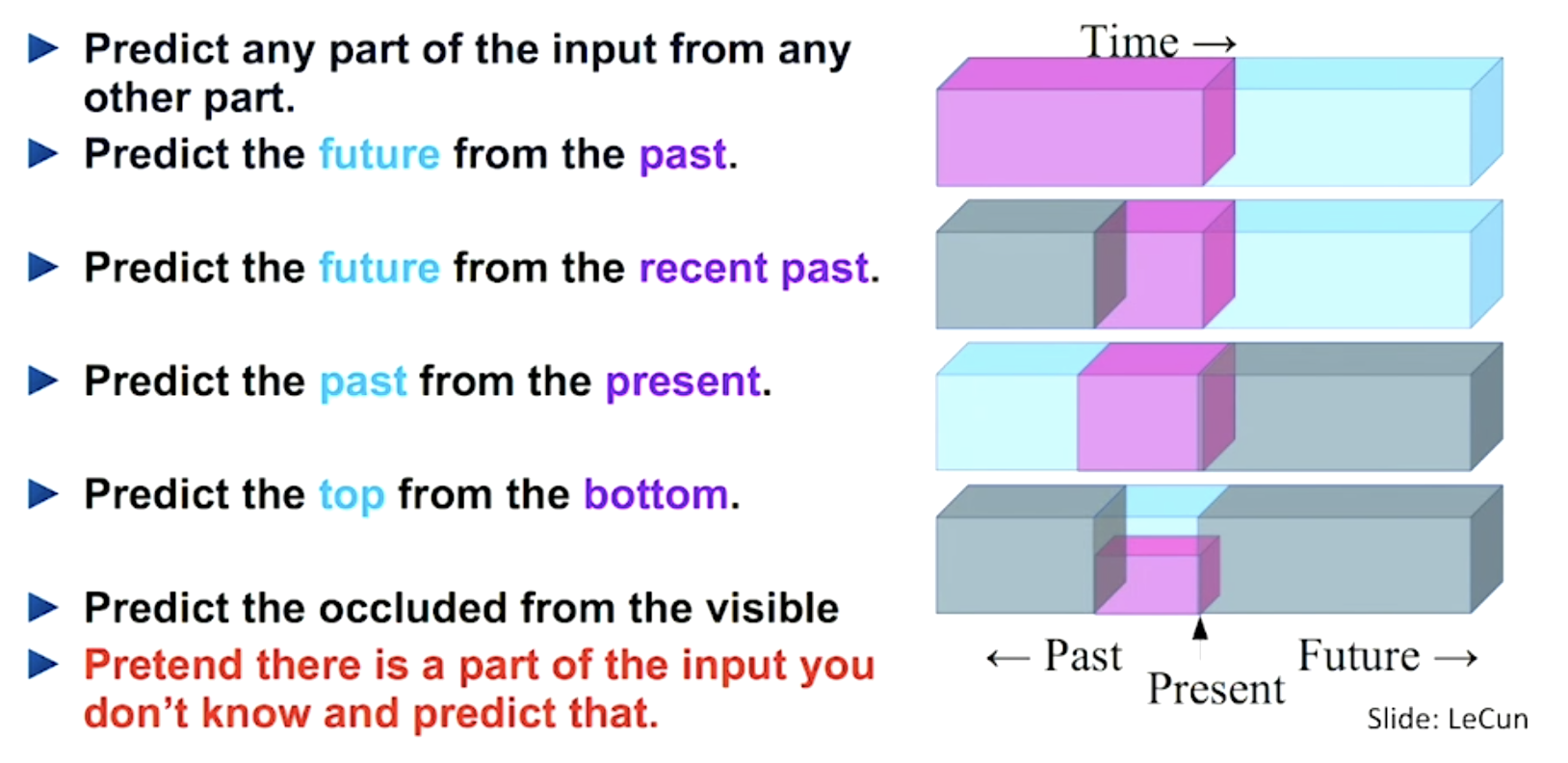
자기지도학습 (self-supervised learning) 이란 직접적인 레이블링 작업 없이 데이터의 일부분을 레이블로 활용하는 학습 방식을 뜻하며, NLP 과제에서 중요한 요소로 자리매김하고 있다. 마스킹 등의 기법을 통해 데이터의 한 부분을 예측하는 과제이며, OpenAI CLIP 과 같이 cross-modality 과제에서 (이미지-텍스트 등) 또한 활용이 가능하다.
-
이미지 데이터 증강은 비전 모델에서 사실상 필수적인 요소이다. torchvision 과 같은 라이브러리를 활용하여 간단하게 구현할 수 있으며, 이미지의 “의미"를 변질시키지 않는 선에서 데이터에 변형을 주는 것을 목표로 삼는다.
-
이외 데이터 형태에 대한 증강 방식은 다음과 같이 정리할 수 있다.
- 정형 데이터의 경우 랜덤하게 선택된 셀 정보를 삭제함으로 미입수 데이터를 모방할 수 있다.
- 텍스트의 경우 증강 기법이 상대적으로 부족한 편. 단어의 순서를 변경하거나, 부분적으로 삭제하는 방식이 존재한다.
- 오디오 데이터는 속도를 조절하거나, 빈 오디오를 중간에 삽입하는 방식 등이 있다.
-
Synthetic Data (합성 데이터) 또한 고려해볼 필요가 있다. 레이블에 대한 사전 지식을 통해 기존에 존재하지 않는 데이터를 생성할 수 있으며, 적용 예시로는 영수증, 손글씨 이미지 등이 있다. 많은 공수가 필요하기 때문에 다른 방법은 없는지 충분히 검토 후 도입.
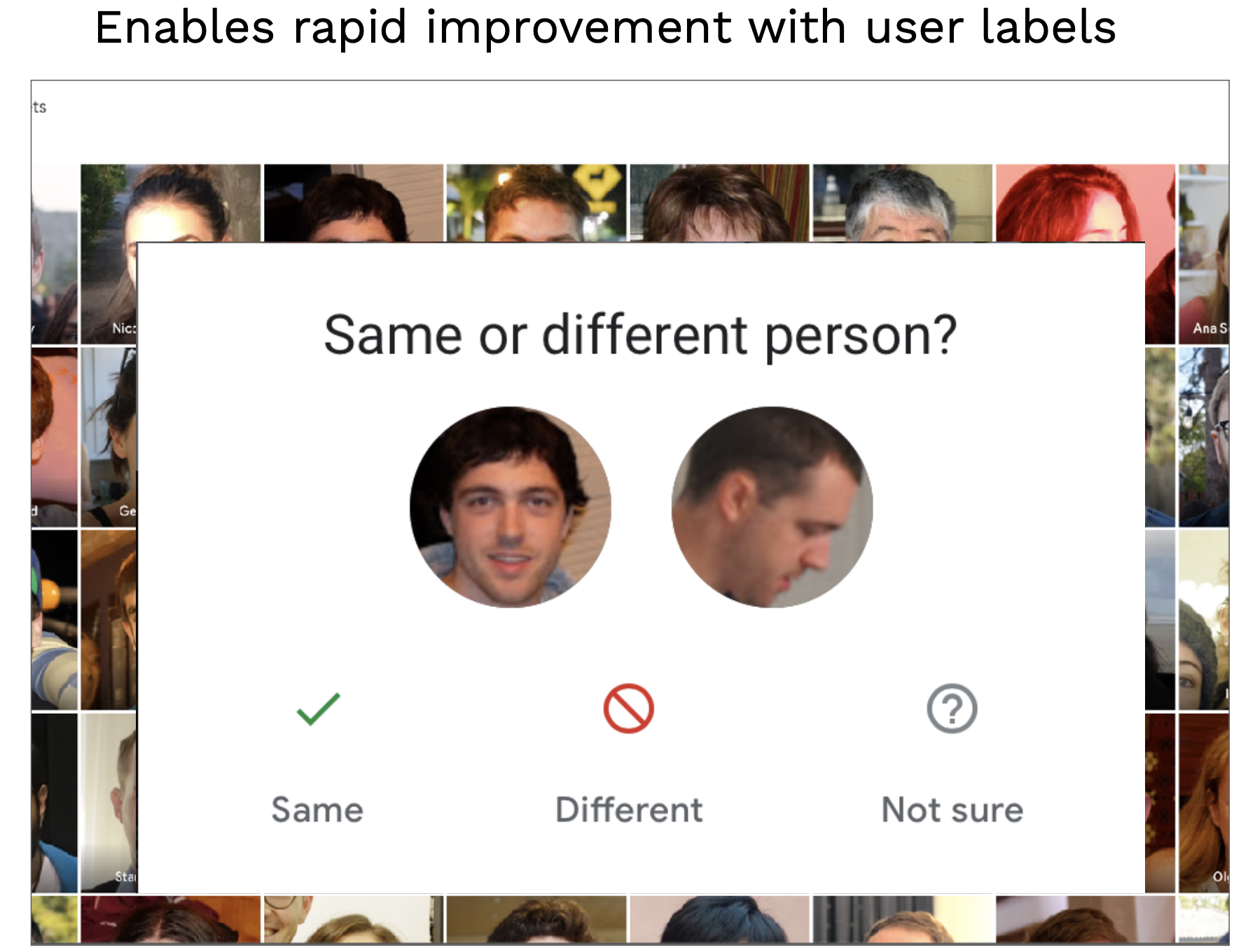
-
보다 창의성을 발휘해 유저에게 레이블링 작업을 맞기는 것 또한 가능하다. 위 이미지와 같이 Google Photos 는 유저에게 이미지 레이블링 작업을 요구.
-
유저의 직접적인 레이블링은 언급된 data flywheel 개념의 적용 예시이다. 유저는 모델 성능 향상에 기여하고, 이로 인해 유저의 제품 경험 또한 개선된다.
-
이렇듯 데이터 레이블링을 우회하는 다양한 방법이 존재하지만, 결국 모델링 작업을 시작하기 위해서는 어느정도의 레이블링 작업은 불가피하다.
-
레이블링이란 bounding box 와 같이 표준적인 형태의 주석을 기록하는 작업이다. 주석의 형태보다는 레이블러가 올바른 교육을 받는 것이 가장 중요하며, 이들이 레이블링 표준을 준수하도록 하는 것은 어렵지만 가장 핵심적인 요소이다.
-
레이블러 고용 시 다음과 같은 옵션이 존재한다.
- 데이터 레이블링을 전문적으로 수행하는 업체.
- 레이블러의 직접적인 고용.
- Mechanical Turk 와 같은 크라우드 소싱. 레이블링 품질을 위해 가능한 피하는 편이 좋다.
-
레이블링 전문 업체들은 소프트웨어 개발, 인력 관리, 품질 관리 까지의 다양한 작업을 수행한다. 업체 활용이 필요하다면 데잍러를 충분히 이해한 후, 샘플 레이블 등을 통해 여러 경쟁 업체를 비교한 후 의사결정을 내리는 편이 좋다.
- Scale AI 는 업계에서 가장 규모가 큰 데이터 레이블링 솔루션이다. 경쟁자로는 Labelbox 와 Supervisely 가 있다.
- LabelStudio 는 가장 널리 알려진 오픈소스 솔루션이며, 직접 레이블링을 수행할 때 활용하게 된다. 경쟁자로는 Diffgram 이 있다.
- Snorkel 은 weak supervision 기반 레이블링 툴이며, “amazing” 이라는 단어가 들어간 모든 문장을 “긍정” 카테고리로 구분하는 등의 빠른 레이블링 작업을 돕는다.
Data Versioning
- 데이터 버전 관리는 단계적으로 구분이 가능하다.
- Level 0 : 단순한 파일시스템 관리로, 버전 관리가 이루어 지지 않는다. 모델이란 코드와 데이터가 합쳐져 만들어진 결과물이기 때문에, 데이터가 바뀌면 동일한 모델을 구현하지 못하게 된다.
- Level 1 : 학습시 데이터에 대한 스냅샷을 저장하는 방식. 모델에 활용된 데이터가 특정 가능하지만, 이상적인 방식이라고 보기엔 어렵다.
- Level 2 : 코드 버전 관리와 같은 개념을 도입. Git-LFS 와 같은 툴을 사용하게되며, 적극적으로 권장되는 방식이다.
- Level 3 : 대용량 데이터 관리를 위한 특별한 솔루션을 도입. 합리적인 이유 (데이터 용량이 지나치게 크거나, 데이터에 많은 규제가 붙는 경우 등) 가 없다면 불필요하다.
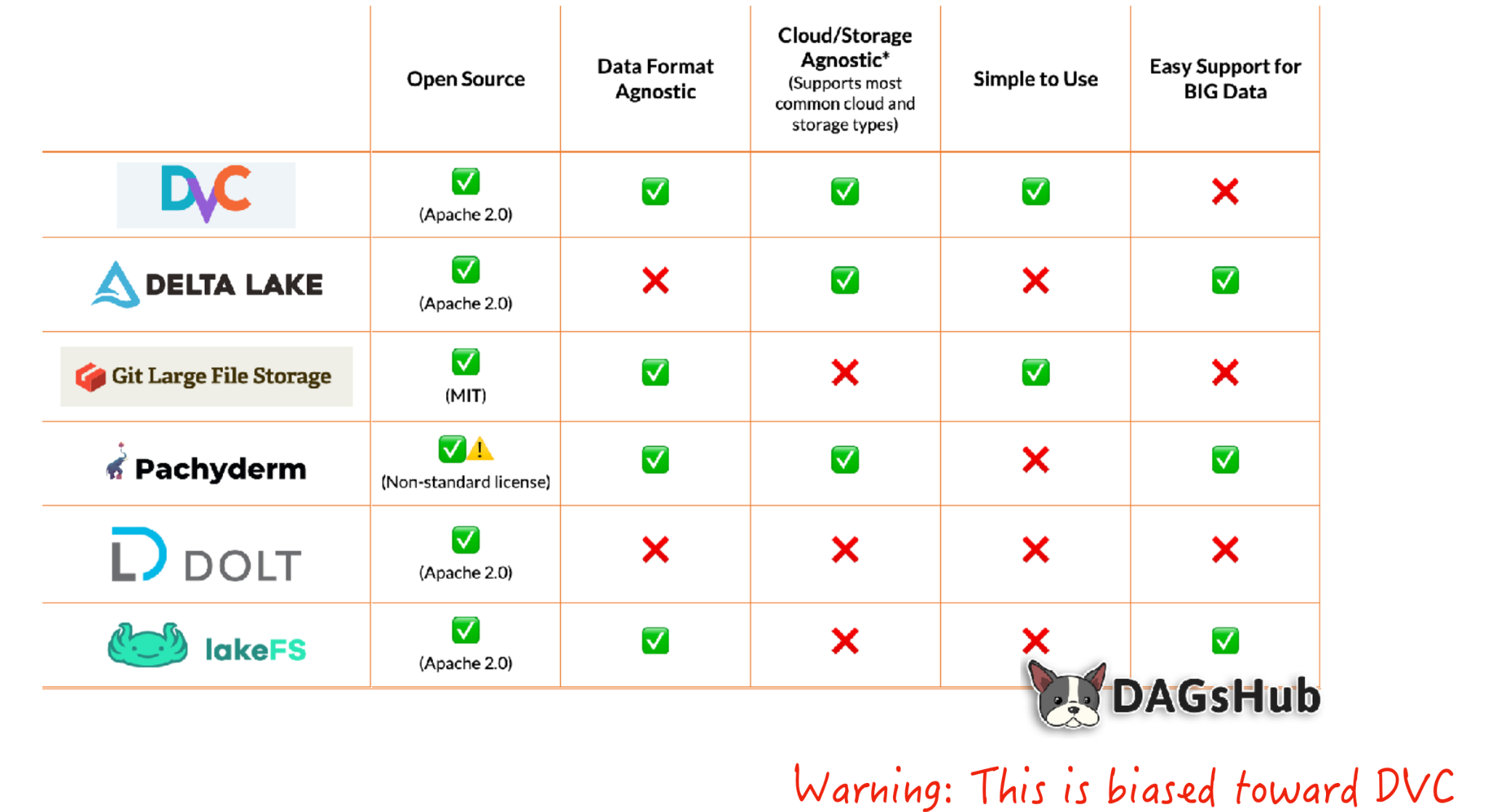
- 이러한 작업을 위한 툴로는 DVC 가 있다. 데이터를 원격 저장소에 저장하고, 필요시 이전 버전으로 회귀하는 기능을 제공.