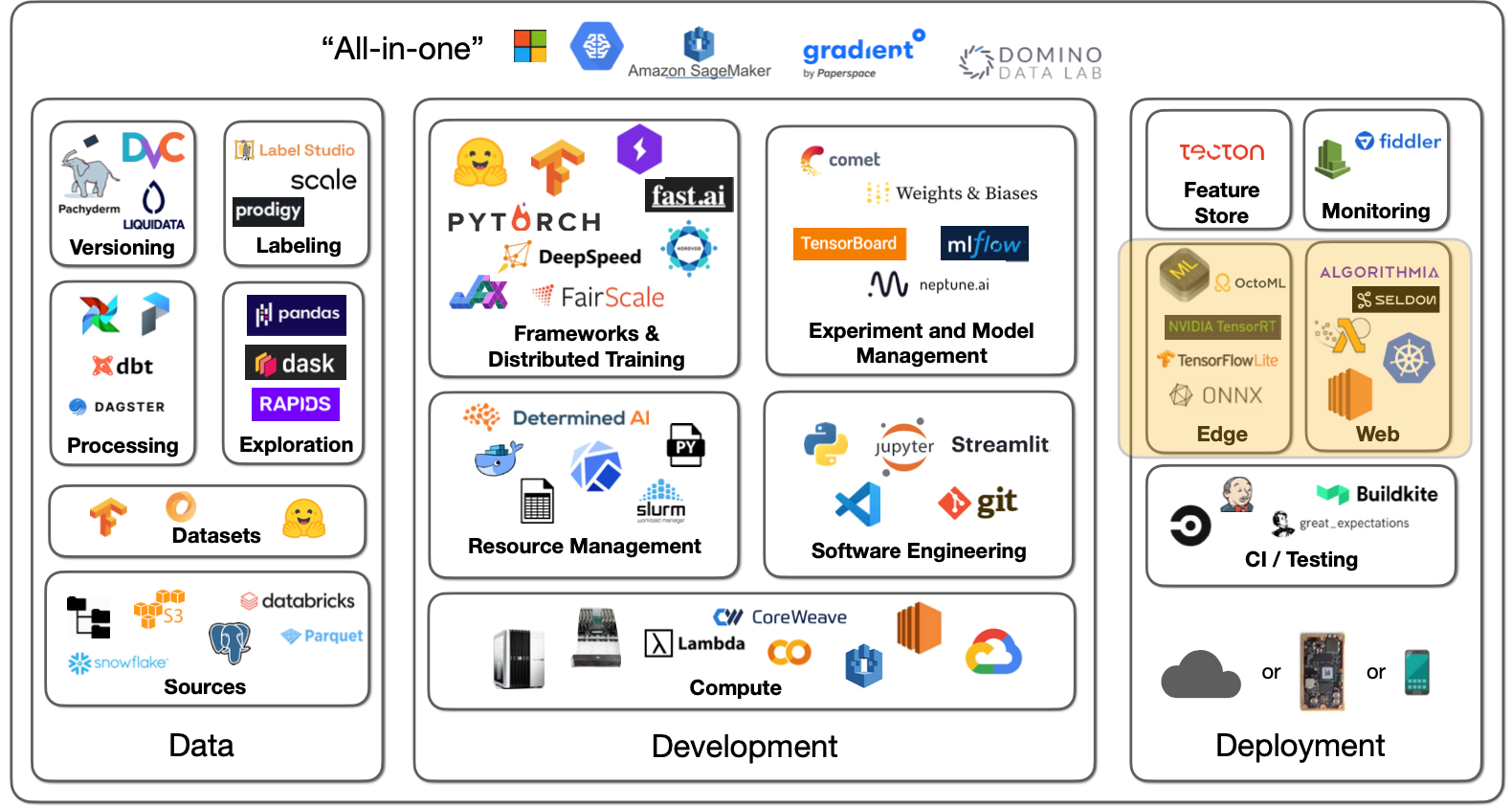
Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
-
배포 과정은 좋은 모델 개발에 있어 필수적인 요소이다. 오프라인으로 모든 평가를 진행하면 모델의 작은 실수들을 놓치기 쉽고, 사용자가 정말 필요로 하는 문제 해결 능력이 부재할 수 있기 때문. 이러한 요소는 모델 배포를 통해서만 검증이 가능한 경우가 많다.
-
다른 ML 개발 단계와 같이 최소한의 기능만을 구현한 후, 복잡한 부분들을 순차적으로 추가하는 과정을 거치는 편이 좋다. 과정은 다음과 같이 정리할 수 있다.
- 프로토타입 설계
- 모델/UI 분리
- 스케일 문제 해결
- 속도 이슈 발생 시, 엣지 디바이스 활용 검토
Build A Prototype To Interact With
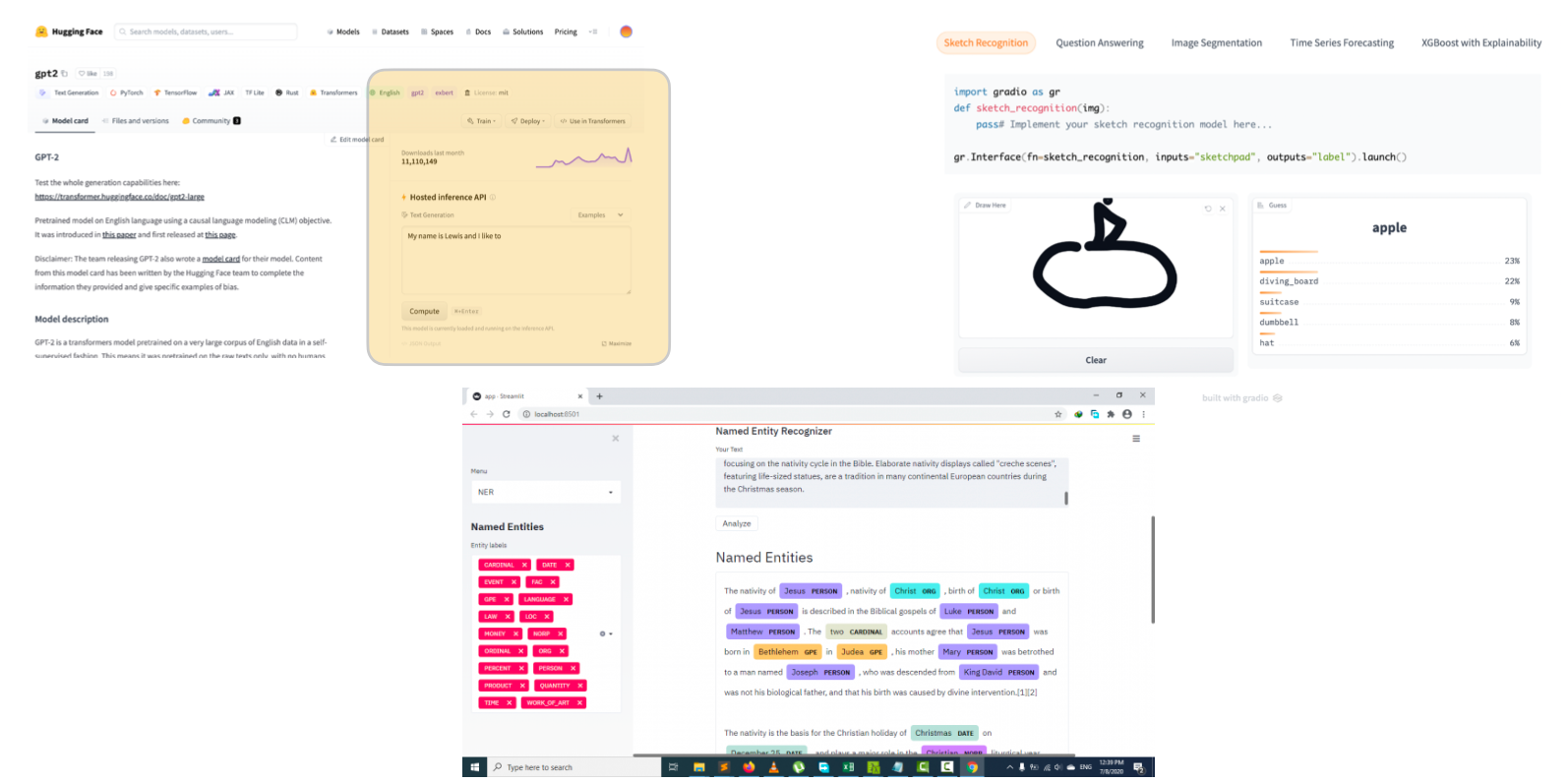
-
프로토타입 설계를 위한 툴로는 최근 HuggingFace 가 인수한 Gradio, Streamlit 등이 있다.
-
좋은 프로토타입 설계를 위해서는 다음과 같은 기본적인 규칙을 지키자.
- 심플한 UI : 프로토타입의 주된 목적은 실사용 환경에서 모델을 테스트해보고, 타인의 피드백을 얻는 것이다. Gradio, Streamlit 과 같은 앱을 활용하면 많은 코드를 쓰지 않더라도 기본적인 인터페이스 구축이 가능하다.
- Web URL 활용 : URL 은 공유하기 쉬우며, 이를 기준점으로 삼아 더욱 복잡한 배포 방식을 택하면서 발생할 장단점을 생각할 수 있다. Streamlit, HuggingFace 모두 클라우드 배포 기능을 제공.
- 공수 최소화 : 강사진은 프로토타입 설계에 하루 이상을 소비하지 않을 것을 권장.
-
하지만 프로토타입은 최종 솔루션의 형태가 아니다.
- 프론트엔드 구현에 있어 분명한 한계점이 존재한다. 완성된 형태의 서비스 제공을 위해서는 커스텀 UI 제작이 필요.
- 스케일링 문제를 안고있다. 유저 수가 증가하게 된다면 스케일업을 위해 백엔드 구축이 필요.
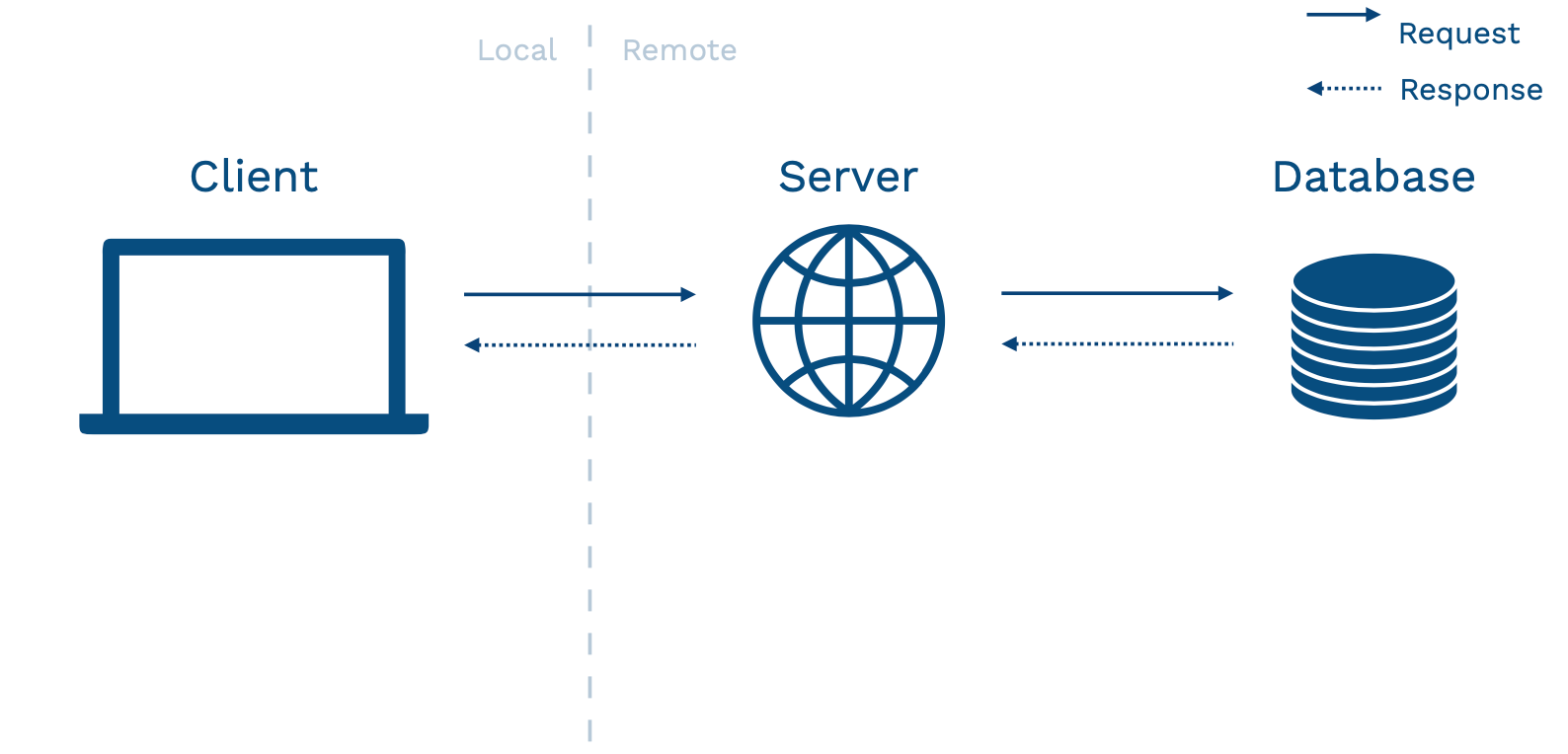
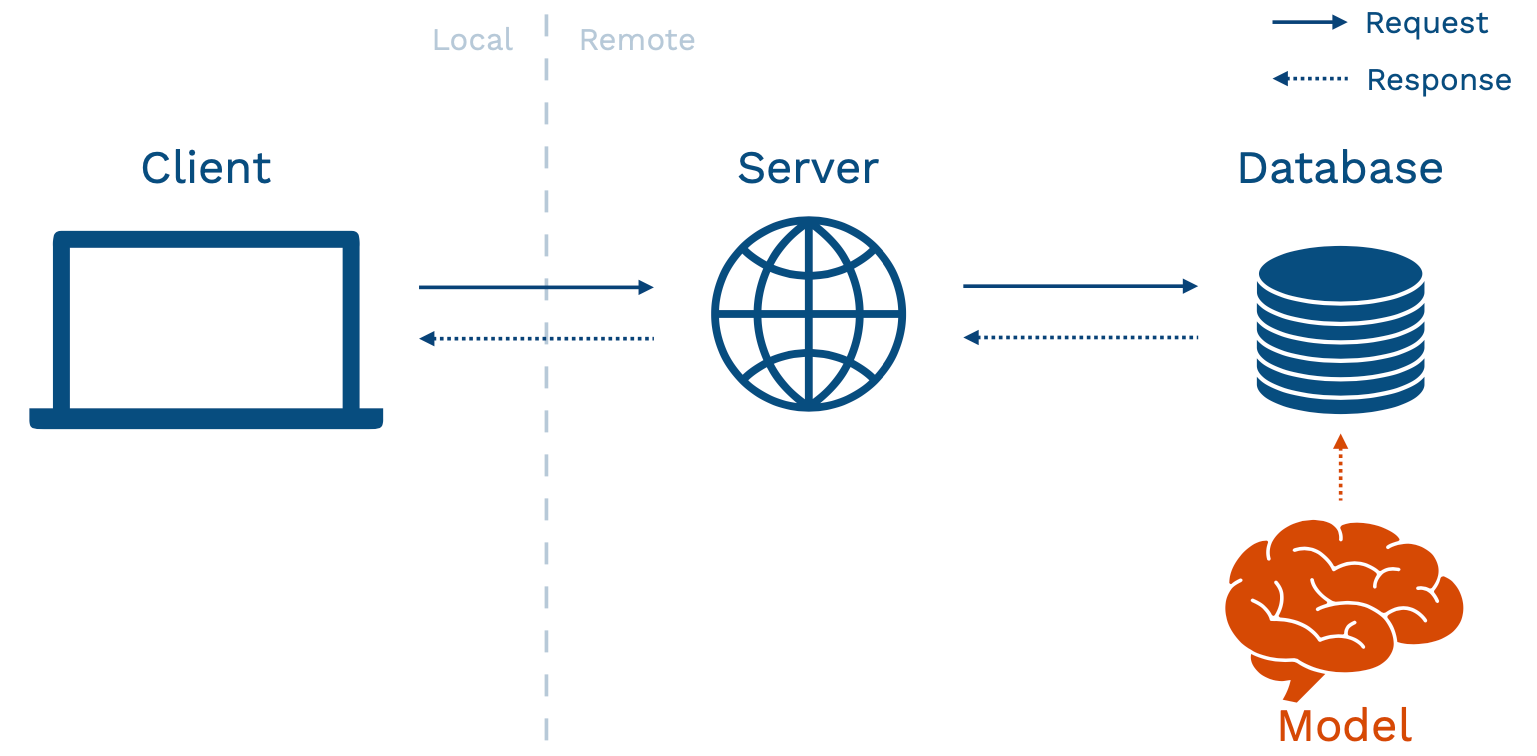
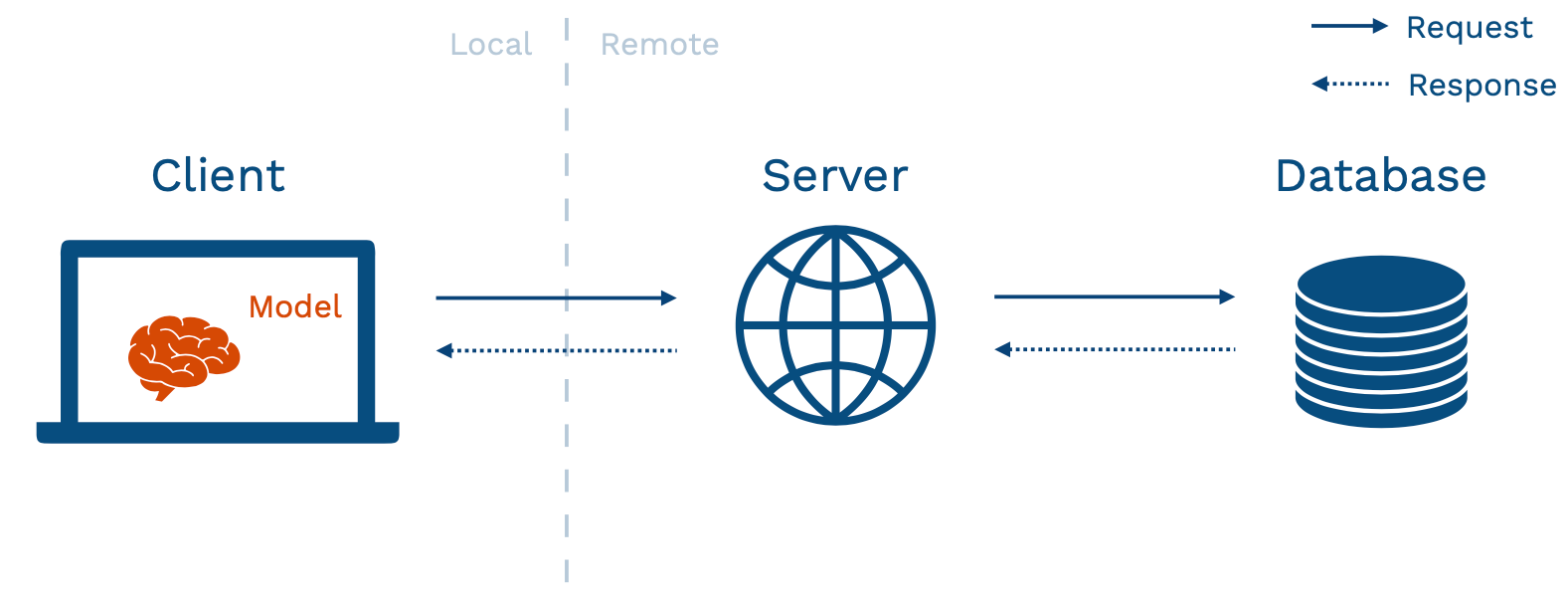
- 상단 장표는 일반적인 어플리케이션의 구조를 보여준다. Client 란 유저가 상호작용하는 기기, 즉 브라우저, 차량, 스마트폰 등이며, 이러한 기기는 네트워킹을 통해 서버와 소통한다. 서버는 데이터베이스와의 상호 작용을 통해 어플리케이션을 구동.
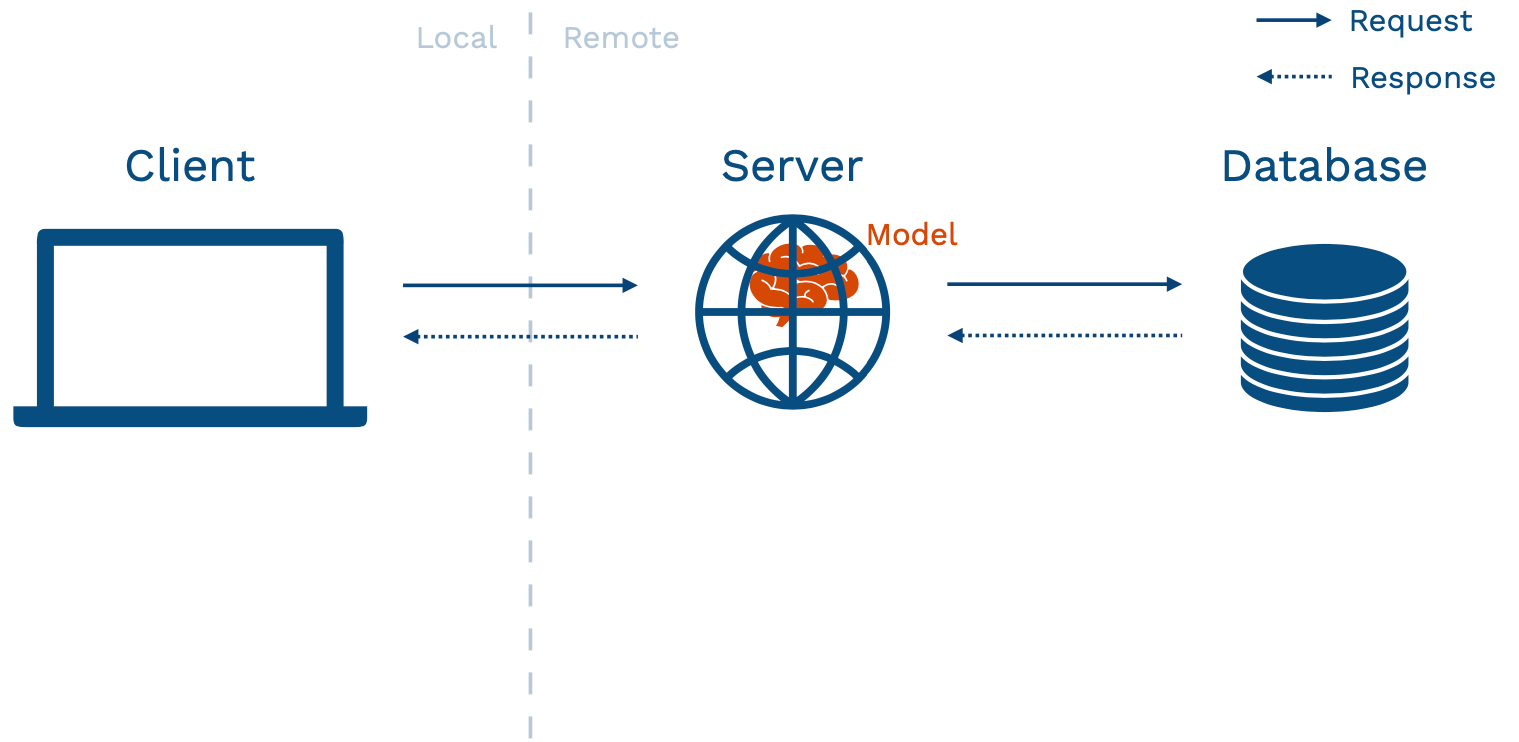
-
이러한 기본적인 어플리케이션 구조에 ML 모델을 배포하는 여러가지 방법이 존재한다. 언급된 프로토타입 접근법은 model-in-service 방식에 해당하며, 웹서버가 패키징된 모델을 품고있는 경우이다 (인스타 등 이미 성숙도가 올라간 서비스에 ML 기능을 추가하는 형태로 생각하면 됨).
-
이 방식의 가장 큰 장점은 모델의 복잡성과 무관하게 기존의 인프라를 사용할 수 있다는 점이다. 하지만 이러한 방식에는 여러가지 단점 또한 존재한다.
- 웹서버가 다른 언어로 작성. 파이썬 기반이 아니라면, 이미 구축된 모델을 서버에 통합하는 과정이 까다로울 수 있다.
- 모델이 서버 코드보다 자주 업데이트 될 수 있음. 어플리케이션이 이미 성숙 단계에 접어들었으나 모델이 초기 단계에 있다면, 모델 업데이트 마다 재배포 과정을 겪어야 할 수 있다.
- 웹서버에 비해 모델의 크기가 지나치게 클 수 있음. 이러한 경우 모델을 직접적으로 사용하지 않더라도 전반적인 어플리케이션 사용 경험에 부정적인 영향이 미칠 수 있다.
- 서버 하드웨어는 ML 작업에 최적화되지 않음. 이러한 서버 장비에 GPU 가 내장되어 있는 경우는 굉장히 드물다.
- 스케일링 속성의 차이가 발생할 수 있음. 따라서 모델과 기존 어플리케이션 간 스케일링 규칙의 차등을 두어야 할 수 있다.
Separate Your Model From Your UI
- 모델을 UI 에서 완전히 분리하는 방법은 크게 (1) Batch Prediction, (2) Model-as-Service 방식으로 나뉜다.
Batch Prediction
-
Batch Prediction 이란 모든 데이터 포인트에 대한 예측치를 사전에 구한 후, 결과값을 데이터베이스에 저장하는 방식이다. 경우에 따라 가장 적절한 방식일 수 있는데, 인풋값이 제한된 경우 주기적으로 예측치를 구하는 것만으로 충분히 최신 정보가 반영된 예측치를 사용자에게 전달할 수 있다.
-
이러한 방식이 적절한 예시는 초기단계의 추천 시스템, 내부 활용을 위한 마케팅 자동화 시스템 등.
-
주기적으로 예측값을 구하기 위해서는 데이터 처리 자동화 파이프라인 활용이 필요하다. (1) 데이터 처리, (2) 모델 로딩, (3) 예측, (4) 예측값 저장 순의 작업이 필요한데, Dagster, Airflow 등의 DAG 시스템이 처리하기에 적절한 문제이다. 유사한 ML 전용 툴인 Metaflow 또한 존재.
-
Batch Prediction 의 장점
- 구현이 간단하다. 이미 학습에 배치 처리 툴을 활용하고 있다면 이러한 구조를 재사용 할 수 있다.
- 스케일링이 쉽다. 데이터베이스는 기본적으로 스케일링에 최적화 되어있는 시스템이다.
- 대형 시스템에서 수년간 검증된 구조. 이미 많은 기업들이 이와 같은 예측 파이프라인을 활용해왔고, 예상하지 못한 문제가 발생할 확률이 상대적으로 적다.
- 예측치 전달이 빠름.
-
Batch Prediction 의 단점
- 경우의 수가 많은 인풋을 처리할 수 없음. 모든 경우의 수에 대한 모든 예측치를 구하는 것에는 분명한 한계가 존재한다.
- 예측치가 가장 최신의 정보를 반영하지 못함. 이러한 정보가 매분, 매초 의미있는 변화를 가진다면, 유저가 보는 예측치는 이미 유의미한 정보를 제공하지 못할 확률이 높다.
- Batch Job 실행 실패를 감지하기 어려움.
Model-as-Service
-
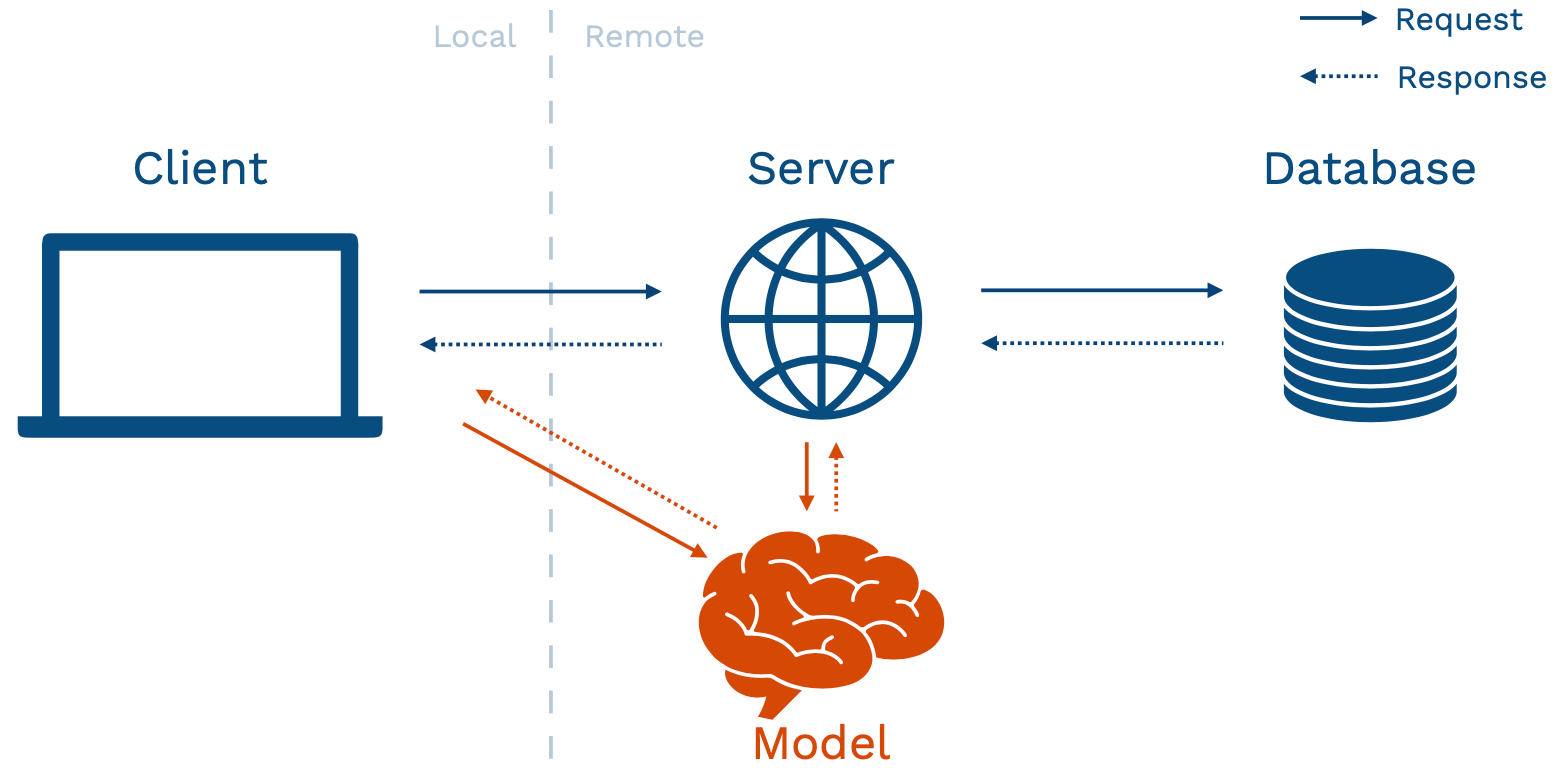
Model-as-Service 란 모델을 별도의 온라인 서비스로서 운영하는 방식이다. 모델은 백엔드, 또는 클라이언트에서 송출한 request 에 대해 response 를 보내는 방식으로 소통하게된다.
-
Model-as-Service 의 장점
- 신뢰성. 모델에서 발생한 버그가 전체 웹 어플리케이션을 다운시킬 확률이 감소하게 된다.
- 스케일링. 목적에 최적화된 하드웨어를 선택하고, 알맞은 방식으로 스케일링을 적용할 수 있다.
- 유연성. 여러 어플리케이션이 모델 인프라를 공유할 수 있다.
-
Model-as-Service 의 단점
- 레이턴시. 별도의 서비스인 만큼, 서버/클라이턴트가 모델을 사용할 때 시간적 비용이 발생.
- 복잡한 인프라. 구축/운영에 대한 새로운 비용이 발생함.
-
이러한 단점들은 감안하더라도 model-as-service 구조는 대부분의 ML 제품 배포에 적합한 방식이다. 복잡한 어플리케이션의 구조에서 모델 서비스를 개별적으로 스케일링 할 수 있다는 점은 중요하기 때문.
-
5주차 강의에선 이러한 모델 서비스를 구축하기 위한 부분들을 설명한다. 이는 (1) Rest API, (2) 디펜던시 관리, (3) 성능 최적화, (4) 수평 스케일링, (5) 롤아웃 등의 개념을 포함한다.
Rest APIs
-
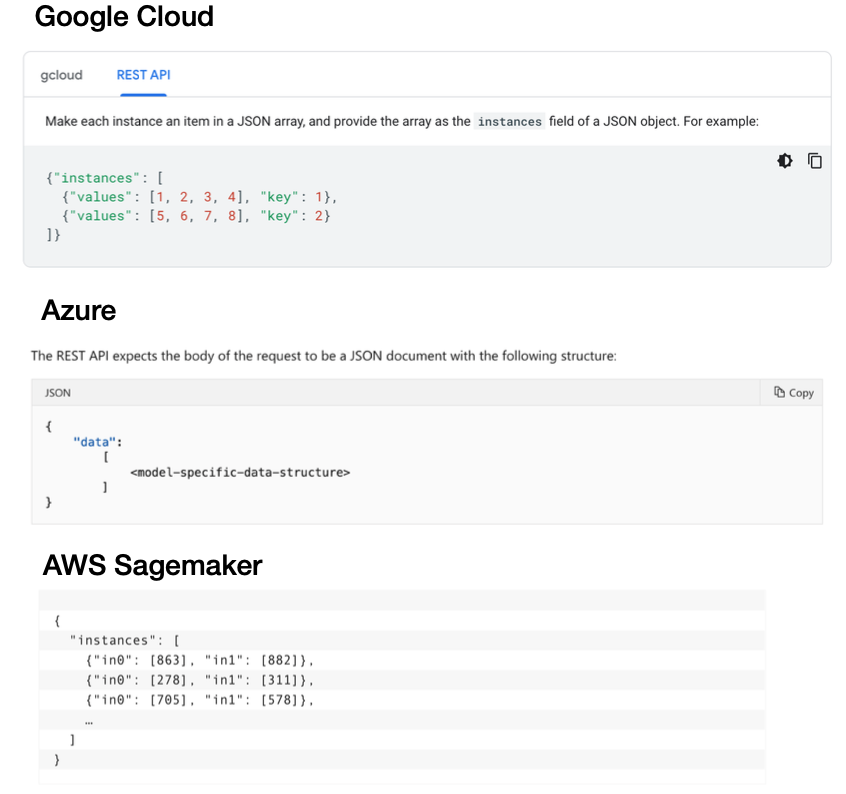
ML 제품의 Rest API 란 약속된 형태의 HTTP 요청에 따라 예측값을 반환하는 형태를 칭한다.
-
인프라에 호스팅된 대안적인 프로토콜은 gRPC, GraphQL (모델 서비스에 적합하지 않을 수 있음) 이 존재.
-
아직 모델 서비스 분야에선 Rest API 문법이 통일되지 않은 상태.
- Google Cloud 는 key, value 페어를 가진 리스트를 인풋으로 정의
- Azure 는 모델 구조에 따라 변동하는 데이터 오브젝트를 다룸
- AWS Sagemaker 는 Google Cloud 와 유사한 형태의 인풋을 기대하지만, 세부적인 형태의 차이 존재.
Dependency Management (디펜던시 관리)
-
예측값은 코드, 모델 가중치, 그리고 디펜던시에 따라 결정된다. 따라서 기대하는 예측값을 얻기 위해서는 웹서버에 개발 환경과 동일한 디펜던시가 세팅되어야 하지만, 이를 항상 보장하는 것은 어려운 작업이다 (개발 환경에서 혹여나 패키지 업데이트가 이루어진다면 서버에서 동일한 업데이트를 매번 진행해야 함, 개발자가 많아지면 관리가 어려워진다).
-
이러한 디펜던시를 관리하는 방법은 크게 두가지가 있다.
- 디펜던시에 무관하게 실행 가능한, 표준화된 모델 개발
- 컨테이너 활용

1. 모델 표준화
-
모델 표준화는 ONNX (Open Neural Network Exchange) 라이브러리를 활용해 이루어진다. 라이브러리는 환경에 무관하게 실행 가능한 ML 모델을 개발할 수 있도록 돕는데, 언어, 패키지 버전 등과 무관하게 동일한 기능을 제공하는 것을 목표로 한다.
-
하지만 실사용 환경에선 많은 라이브러리들이 지나치게 빠른 속도로 업데이트되기 때문에 변환 과정에서 버그가 자주 발생하고, 이를 해결하기 위해 오히려 ONNX 를 사용하지 않는 것 보다 더 많은 작업이 발생하는 경우가 있다.
-
또 torchvision 과 같은 주변 라이브러리는 아예 지원이 안되는 경우가 많다.
2. 컨테이너
-
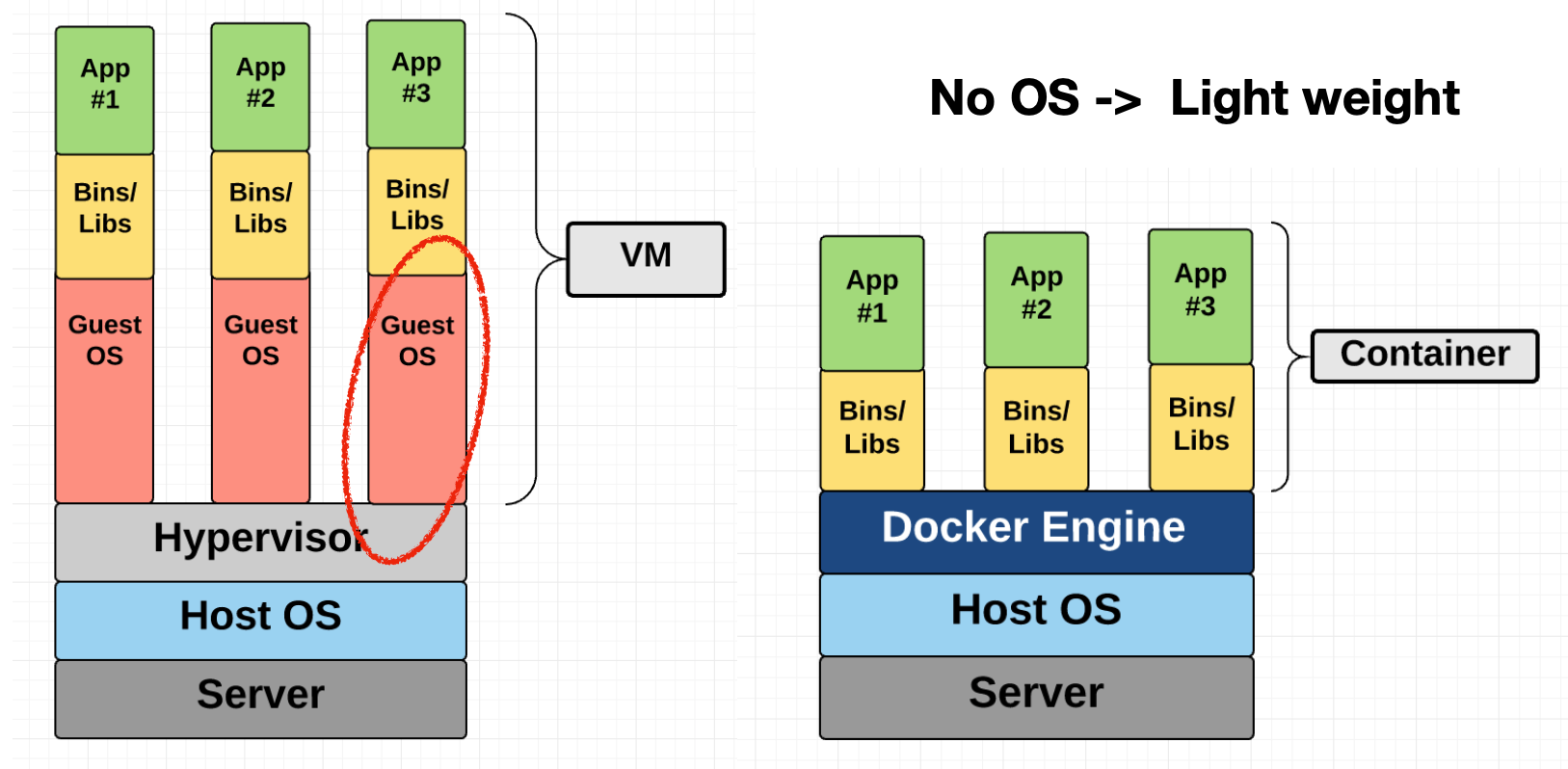
컨테이너를 설명하기 전, 우선 도커와 가상머신의 개념을 구분해 정리할 필요가 있다.
- 가상머신 (VM) : 라이브러리, 어플리케이션은 물론 운영체계 (OS) 까지를 하나의 패키지로 묶는 방식이다. 용량은 물론 실행에 필요한 자원 소모가 큰 편.
- 도커 : OS 를 적은 용량/자원으로 가상화하여, 필요한 라이브러리와 어플리케이션 만을 구동하는 방식.
-
이렇듯 실행이 가벼운 도커는 일반적으로 구분 가능한 작업 마다 개별적으로 생성된다. 예시로 웹앱은 (1) 웹서버, (2) 데이터베이스, (3) Job 관리, (4) Worker 총 4개의 컨테이너가 함께 동작하는 방식으로 운영.
- Job 관리 (Job Queue) : Airflow, Rundeck 등의 Job Scheduler 에서 유지하는, 앞으로 실행할 Job 에 대한 데이터 구조.
- Worker : 요청한 태스크를 수행하는 자원 (예. 주문 내역을 파싱 및 데이터베이스로 이동).
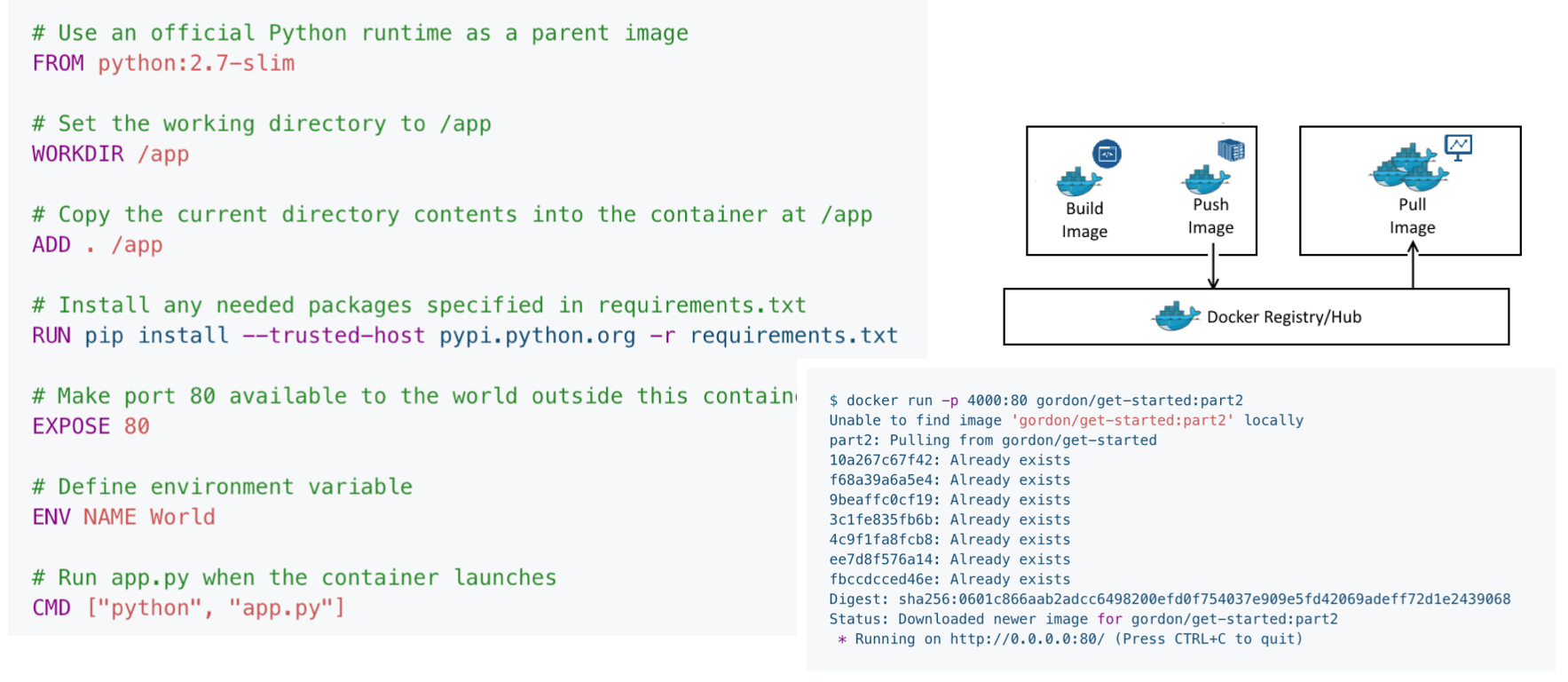
-
도커 컨테이너는 도커 파일을 통해 생성된다. 각 컨테이너는 서로 다른 도커 파일을 통해 환경을 생성하며, 클라우드나 별도 서버에 저장된 도커 허브를 통해 컨테이너를 공유하는 것 또한 가능하다.
-
도커는 다음과 같은 3가지 요소로 구성되어 있다.
- 클라이언트 : 도커 이미지 구성. 로컬 환경에서 여러 커맨드를 통해 조작이 가능하다.
- 도커 호스트 : 클라이언트에서 입력된 커맨드 실행 및 이미지/컨테이너 생성. 서버 혹은 로컬 환경 모두 구성이 가능함.
- 레지스트리 : 여러 개의 컨테이너 저장. 도커 호스트와 직접 소통.
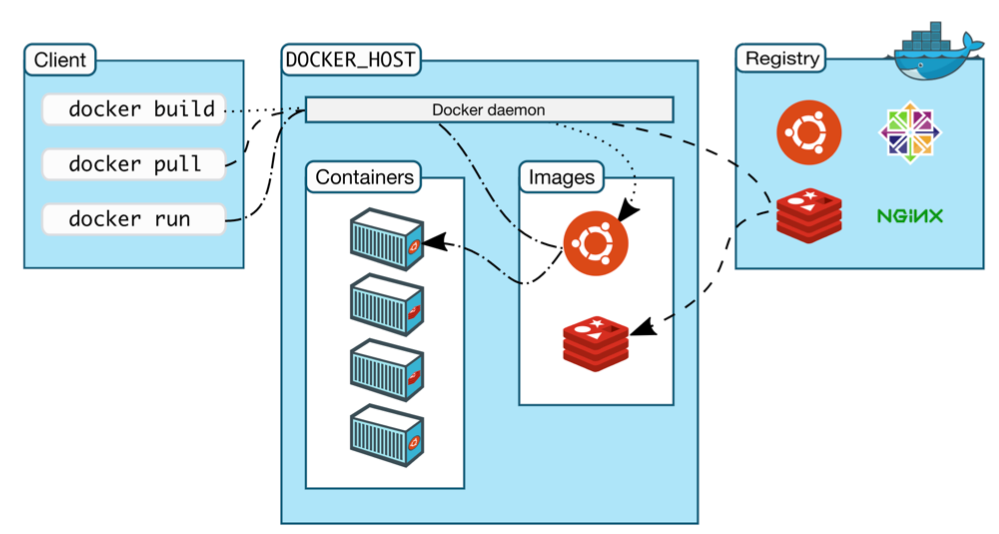
-
이와 같은 태스크 분리를 통해 노트북 등의 로컬 자원, 도커 호스트에 저장된 이미지에 등에 의해 도커 활용에 제약이 가해지지 않는다.
-
공개된 여러 퍼블릭 도커 허브엔 다양한 이미지가 호스팅 되어 있으며, 프라이빗 이미지를 저장할 수 있는 기능 또한 제공하고 있다. 최근엔 그 인기가 급상승해 이렇나 도커 허브 활용을 기본 전제로 하는 경우가 잦은 편이다.
-
도커는 입문 난이도가 다소 높은 편이다. Cog, BentoML, Truss 와 같은 서비스는 이러한 과정을 간소화 해주며 지정된 모델 호스트 활용, 모델 패키징 등 다양한 기능을 제공한다.
Performance Optimization (성능 최적화)
- 예측 연산을 효율화하기 위해선 GPU, concurrency (여러 모델 활용), model distillation (모델 간소화), quantization (파라미터 용량 제한), caching (캐싱), batching (배치 관리), GPU sharing, 관련 라이브러리들을 논할 필요가 있다.
1. GPU
-
호스트 서버에 GPU 자원을 포함시키는 것에서 얻는 장점은 다음과 같다.
- 학습이 이루어진 것과 같은 환경에서 예측이 이루어진다면 환경 관련 이슈가 발생할 염려가 없다.
- 많은 트래픽을 더욱 빨리 처리할 수 있다.
-
하지만 GPU 자원은 세팅이 보다 어렵고, 트래픽에 의한 비용폭이 크기 때문에 CPU 만을 활용한 초기 모델 서비스 또한 고려해봄직 하다.
-
하기 테크닉을 통해 보다 적은 비용으로 CPU 자원에서 연산 속도를 개선하는 것 또한 가능함.
2. Concurrency
-
여러개의 CPU, 또는 CPU 코어에서 복수의 모델을 실행하는 방식.
-
Thread Tuning 과정이 필요하며, 이와 같은 테크닉을 통해 로블록스는 일일 10억 리퀘스트에 대한 BERT 서비스를 CPU 자원만으로 해결.
3. Model Distillation
-
학습된 모델의 행동을 모방하는 작은 규모의 모델을 생성하는 방식.
-
이 글 에서 관련된 테크닉을 소개하고 있으며, 직접 구현시 성능이 다소 떨어질 수 있다.
-
서비스 환경에서 자주 활용되지는 않지만, DistilBERT 와 같은 예외 경우 또한 존재.
4. Quantization
-
모델 전체, 또는 일부분을 보다 작은 용량의 number representation 을 활용해 실행하는 방식이다.
-
대게 활용되는 representation 으로는 16-bit floating point, 8-bit integer 가 있으며, 모델 정확도에 부정적인 영향을 끼치게 된다. 속도 개선이 정확도 보다 중요하다고 판단되면 고려할 수 있음.
-
PyTorch, Tensorflow 등의 패키지는 자체 quantization 라이브러리를 포함하고 있으며, Huggingface 의 사전학습 모델 활용 시 Huggingface Optimum 또한 활용이 가능하다.
-
학습 시 quantization 과정을 감안한 quantization-aware training 이라는 테크닉이 존재하고, 적은 용량으로 representation 변경 시 보다 개선된 정확도를 보인다.
5. Caching
-
자주 처리되는 인풋을 캐시에 미리 저장해둠으로 처리 속도를 개선시키는 방식. 자원 활용이 큰 연산을 수행하기 전에 인풋이 캐시에 존재하는지 먼저 확인한다.
-
캐싱에는 다양한 방식이 존재하지만, Python functools 라이브러리를 활용하는 것을 추천.

6. Batching
-
배치 처리 시 연산 속도가 개선된다는 점을 활용해 (특히 GPU 활용 시) 일정 수만큼의 인풋을 저장 후 처리하는 방식.
-
인풋을 모으는 기간 동안 유저가 레이턴시를 경험할 수 있기 때문에 배치 사이즈 조절이 필요하다. 레이턴시가 너무 길어진다면 이를 별도로 처리해야하며, 구현이 복잡하기 때문에 라이브러리 등을 활용.
7. GPU Sharing
- 단일 GPU 에 여러개의 모델을 구동시키는 것 또한 가능하다. GPU sharing 기능을 지원하는 패키지 활용.
8. 라이브러리
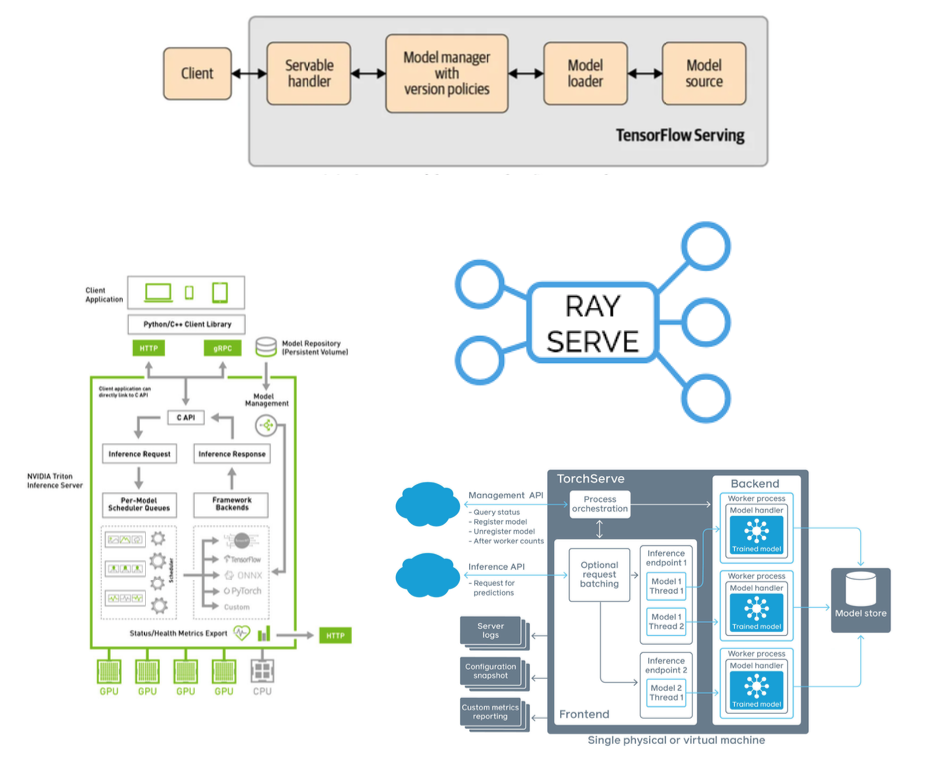
- PyTorch, Tensorflow, NVIDIA, Ray Serve 등의 옵션이 있다. NVIDIA 쪽이 가장 좋은 성능을 보여주지만 입문장벽이 있는 편이고, Ray Serve 의 경우 비교적 난이도가 쉬운 편.
Horizontal Scaling (수평 스케일링)
-
트래픽이 증가할 수록 단일 서버보다는 여러대의 서버에서 복제된 모델을 운영할 필요가 생긴다. 이를 수평 스케일링이라 부르며, 한대의 서버에서 처리했을 트래픽을 여러개의 서버로 분산하는 작업을 필요로한다.
-
각 서버엔 서비스되는 모델의 복제본이 저장 되어있으며, nginx 와 같은 load balancer 라는 툴을 이용해 분산된 트래픽을 처리한다. 모델 서비스의 경우 이를 구현하는 방식으로는 크게 container orchestration 와 serverless 가 존재한다.
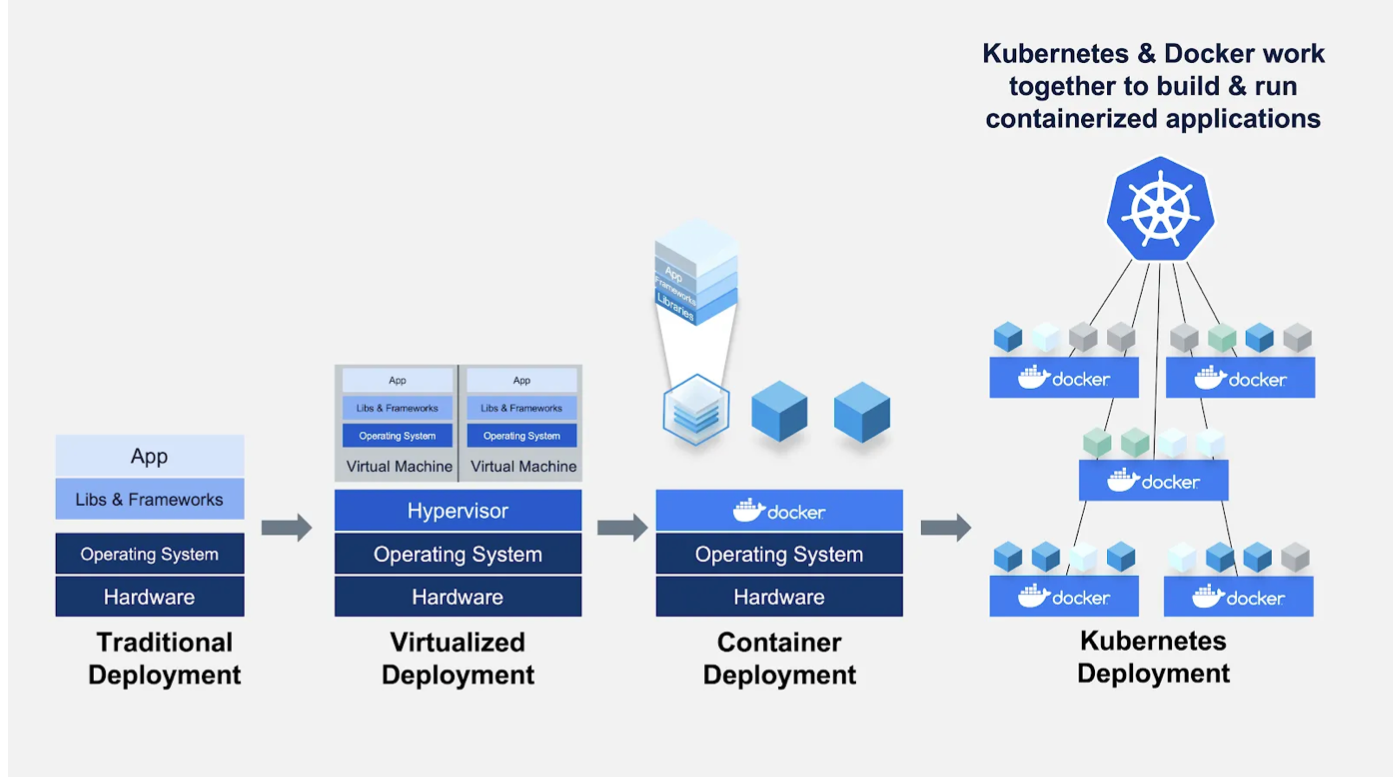
1. Container Orchestration
-
Kubernetes 를 활용해 다수의 도커 컨테이너를 여러대의 서버에서 분산처리 할 수 있도록 돕는 방식.
-
단순히 모델 배포가 목적이라면 굳이 Kubernetes 를 활용할 필요는 없다. Kubeflow, Seldon 등 관련 작업을 간소화 하는 옵션이 존재.
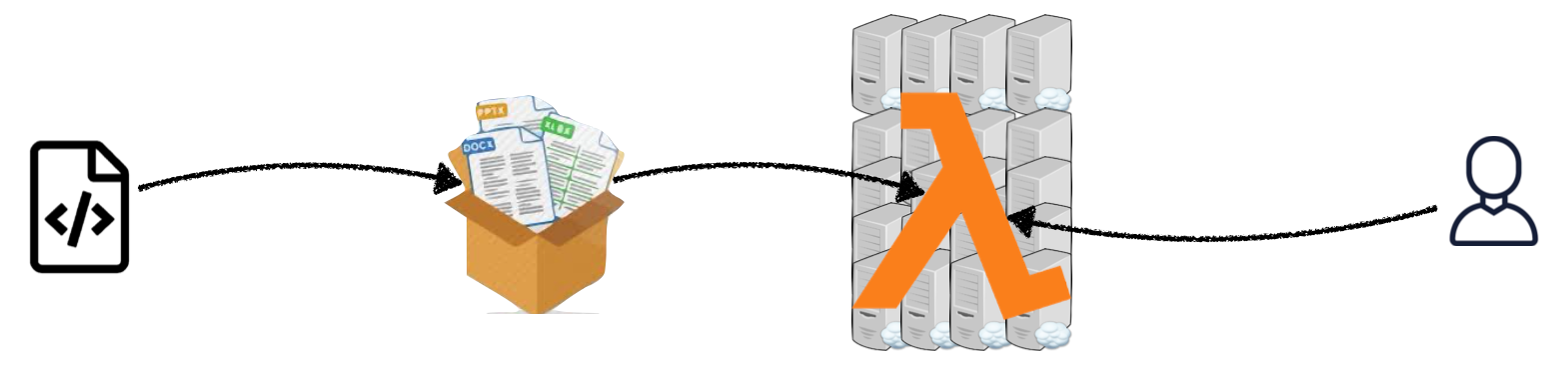
2. Serverless
-
어플리케이션을 구성하는 코드와 환경을 zip 파일, 또는 도커 컨테이너로 압축한 후 하나의 함수 (model.predict() 등) 를 통해 예측치를 연산하도록 구성.
-
이와 같이 패키징 된 모델은 AWS Lambda 와 같은 서비스를 통해 배포되며, 인프라와 관련된 모든 작업은 클라우드에서 자동적으로 처리된다 (증가한 트래픽에 따른 스케일링 등). 유저 입장에서는 제때 비용만 정산하면 됨.
-
구체적인 이유로 Kubernetes 를 활용하는 것이 아니라면, Serverless 로 배포를 시작하는 편이 좋다. 단점은 다음과 같이 정리할 수 있다.
-
배포 패키지의 사이즈 제한이 존재한다. 용량이 큰 모델은 이와 같은 방식으로 배포가 어려운 편.
-
트래픽 미발생으로 서버가 닫혀있는 상태에서 다시 예측치를 내기 까지의 시간 소요가 길다. 이를 cold start 문제라 부르며, 초단위에서 분단위 까지의 시간을 필요로 한다.
-
파이프라인 등 복잡한 소프트웨어 기능 구현이 어렵다.
-
서버 상태 모니터링과 별도 배포 툴 적용이 어렵다.
-
Serverless 환경은 대체로 GPU 를 포함하지 않으며, 실행 시간에 제한을 둔다. 보다 작은 규모의 Banana, Piepeline 과 같은 스타트업들은 GPU 를 활용한 서버리스를 제공.
-
Model Rollouts (롤아웃)
-
이미 배포된 상태의 모델을 업데이트하고, 관리하는 과정을 의미한다.
-
새로운 모델을 효율적으로 배포 하기 위해서는 다음과 같은 배포 방식이 모두 가능해야 한다.
- 점진적 배포 : 기존 배포 버전에서 새로운 배포 버전으로 트래픽 양을 점진적으로 증가.
- 즉각적 배포 : 문제가 발생한 배포 버전에서 새로운 배포 버전으로 즉각적인 변경.
- 배포 버전 관리 : 두 개의 배포 버전을 두고 트래픽 배분.
- 파이프라인 배포 : 개발된 파이프라인 플로우를 모델과 함께 배포.
-
이러한 기능들은 직접 구현이 어려우며, 일반적으로 managed service 를 통해 모델 배포에 적용하게 된다.
Managed Options

-
클라우드 3사 모두 배포 과정을 간소화하는 managed service option 기능을 제공하며, BentoML, Banana 등의 스타트업 또한 관련 기능을 제공.
-
가장 인지도 있는 서비스는 AWS Sagemaker 이다. Huggingface class, SciKit-Learn model 등 일반적인 형태의 모델의 경우 적용이 쉬운 편이다. 하지만 일반적인 EC2 인스턴스에 비해 50~100% 가량 비용이 비쌈.
Move To The Edge?
-
웹에서 벗어나 클라이언트 기기 (엣지 디바이스) 내에서 모델 예측을 구현하는 방식 또한 고려해 볼 수 있다. 인터넷 액세스가 불안정한 환경이거나, 민감한 개인정보를 다룰 경우 엣지 디바이스 활용은 필수적.
-
엣지 디바이스 활용을 필수적으로 요구하는 환경이 아니라면, 모델의 정확도와 레이턴시 간 유저 경험에 더 중요한 요소를 선택해야한다. 레이턴시를 줄일 수 있는 모든 옵션이 이미 적용되었다면, 엣지 디바이스 활용을 고려할 것.
-
엣지 디바이스 inference 는 구현이 복잡하기 때문에 반드시 필요한 경우에만 적용해야 한다. 서버에서 학습된 모델 가중치를 엣지 기기에 불러온 후, 이후 모든 예측 과정을 엣지 기기에서 수행하는 방식으로 진행.
-
대표적인 장점은 레이턴시 감소이다. 네트워크를 사용할 필요가 없으며, 트래픽에 의한 비용이 발생하지 않는다. 이에 반한 단점은 하드웨어와 소프트웨어의 제약이다. 모델 업데이트 또한 과정이 보다 복잡해지는 문제가 있다.
Frameworks
-
엣지 배포에 필요한 적절한 프레임워크는 학습 과정과 엣지 기기에 따라 달라질 수 있다.
- TensorRT : 엣지 기기가 NVIDIA 하드웨어라면 가장 적절
- MLKit, CoreML : Android, 혹은 iPhone 을 대상으로 한다면 공식 프레임워크 검토
- PyTorch Mobile : iOS 와 Android 환경을 모두 지원
- TFLite : 핸드폰과 같은 일반적인 기기가 아닌 경우 또한 TF 사용 환경을 지원
- TensorFlow JS : 브라우저 배포 전용 프레임워크
- Apache TVM : 라이브러리, 타깃 기기와 무관하게 활용 가능. 가능한 많은 환경을 지원하고자 한다면 적절함
Efficiency
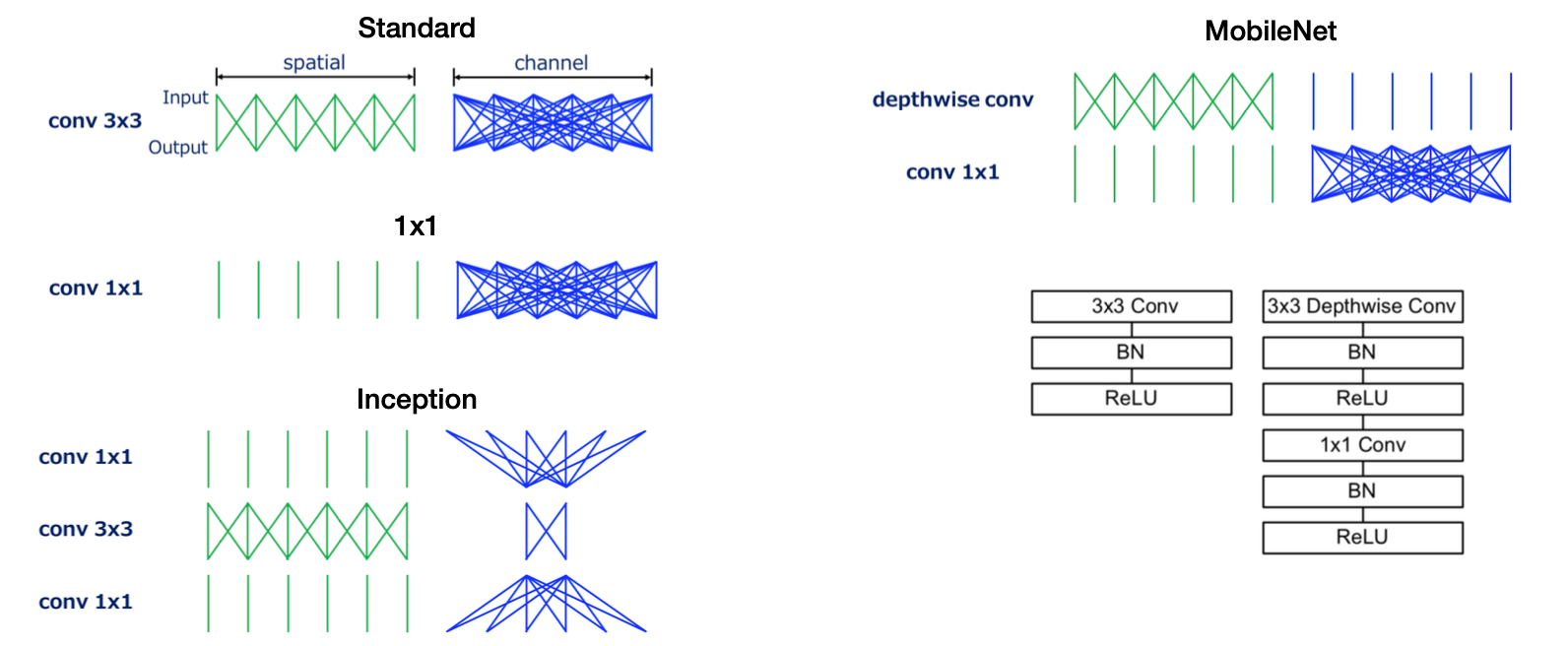
-
엣지 기기의 하드웨어 제약을 뛰어넘는 용량을 가진 모델의 경우, 프레임워크와 무관하게 배포는 불가능하다고 보아야한다. 때문에 가능한 적은 용량과 연산 자원을 사용하면서 최대의 성능을 이끌어내는 모델 구조가 중요.
-
Quantization, Distillation 등의 기법 또한 활용 가능하나, MobileNets 와 같이 엣지 기기를 사전에 염두한 모델 구조 또한 존재한다. 모델 성능이 감소하나 많은 경우 실사용에 지장이 없다. 이와 결이 유사한 모델로는 DistilBERT 가 있다.

Mindsets
엣지 배포를 검토할 시 다음과 같은 사항을 고려하는 편이 좋다.
-
모델 구조가 아닌 엣지 기기의 환경에 집중할 것. 성능이 좋은 모델 구조를 학습 후, 엣지 기기에서 구동이 어렵다면 모델링 과정을 처음부터 다시 시작해야 할 수 있다.
-
실행 가능한 모델이 구현되었다면, 계속적으로 엣지 기기를 활용할 것이 아니라 로컬 환경에서 모델을 고도화 할 것. 이 경우 모델 용량 등을 Experiment Tracking Metric 으로 추가하는 것이 좋다.
-
모델 튜닝 과정을 추가적인 리스크로 다룰 것. 관련 프레임워크는 아직 성숙하지 못했기 때문에, 작은 하이퍼파라미터 변동으로도 모델이 작동하지 않을 리스크가 존재한다.
-
버저닝을 통한 회귀점을 구비할 것. 엣지 배포의 경우 특히 모델을 작동하던 마지막 상태로 복구할 수 있는 시스템이 필요하다.