Lecture 내용 요약
- FSDL 2022 Course Overview
- Lecture 1 - When to Use ML and Course Vision
- Lecture 2 - Development Infrastureture & Tooling
- Lecture 3 - Troubleshooting & Testing
- Lecture 4 - Data Management
- Lecture 5 - Deployment
- Lecture 6 - Continual Learning
- Lecture 7 - Foundation Models
- Lecture 8 - ML Teams and Project Management
- Lecture 9 - Ethics
Why is this hard?
제품을 만드는 과정은 다음과 같은 이유로 어렵고 험난하다.
- 좋은 인력을 채용해야 한다.
- 채용된 인력을 관리하고, 성장시켜야 한다.
- 팀의 결과물들을 관리하고, 방향성을 맞춰야 한다.
- 장기간 제품에 영향을 끼칠 기술적인 요소들을 적절히 선택해야 한다.
- 리더십의 기대치를 관리해야 한다.
- 필요 조건을 정의하고, 관련 인력에게 커뮤니케이션 해야 한다.
머신러닝은 이와 같은 과정을 더욱 어렵게 만든다.
- ML 관련 인력은 아직 시장에 많지 않고, 채용 비용이 비싼 편이다.
- ML 팀에는 상대적으로 다양한 롤 (role) 이 존재한다.
- 대부분 프로젝트의 타임라인이 불명확하고, 실패 확률이 높다.
- 분야가 빠르게 발전하고 있으며, ML 제품 관리는 어렵고 아직 체계가 확립되지 않았다.
- 리더십은 대게 ML 기술을 깊게 이해하지 못한다.
- 비전문 인력이 ML 제품의 실패 원인을 파악하기 어렵다.
8주차 강의는 다음과 같은 내용을 담고있다.
- ML 분야의 롤 (role) 과 롤 별 필요 전문성
- ML 엔지니어 채용 방식 (그리고 취업 방식)
- ML 팀의 구성 방식과 전체 조직과 협업하는 법
- ML 팀과 ML 제품을 운영하는 법
- ML 제품 기획 시 고려 요소
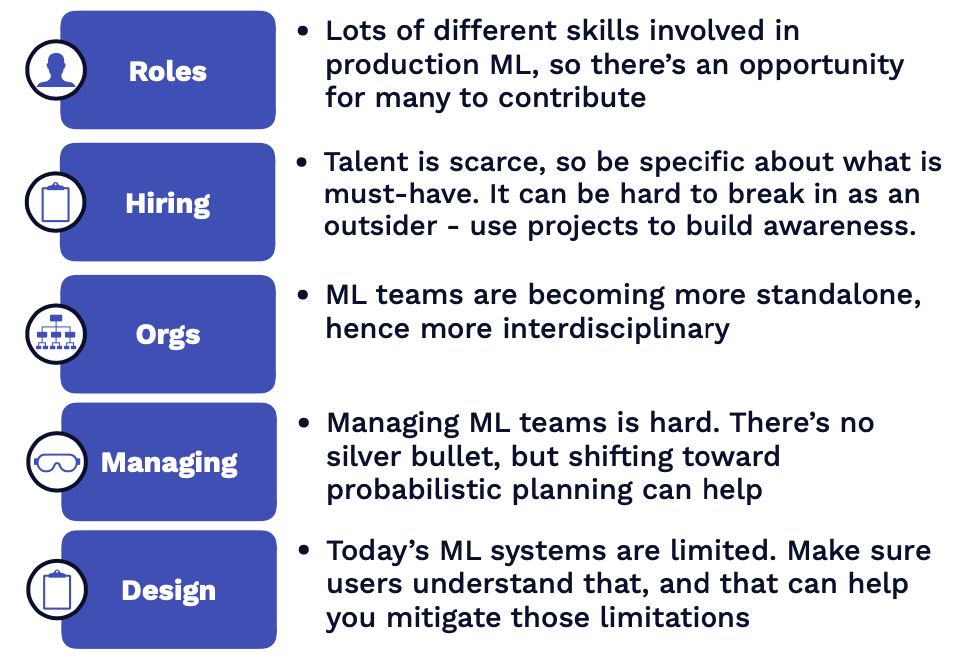
Roles
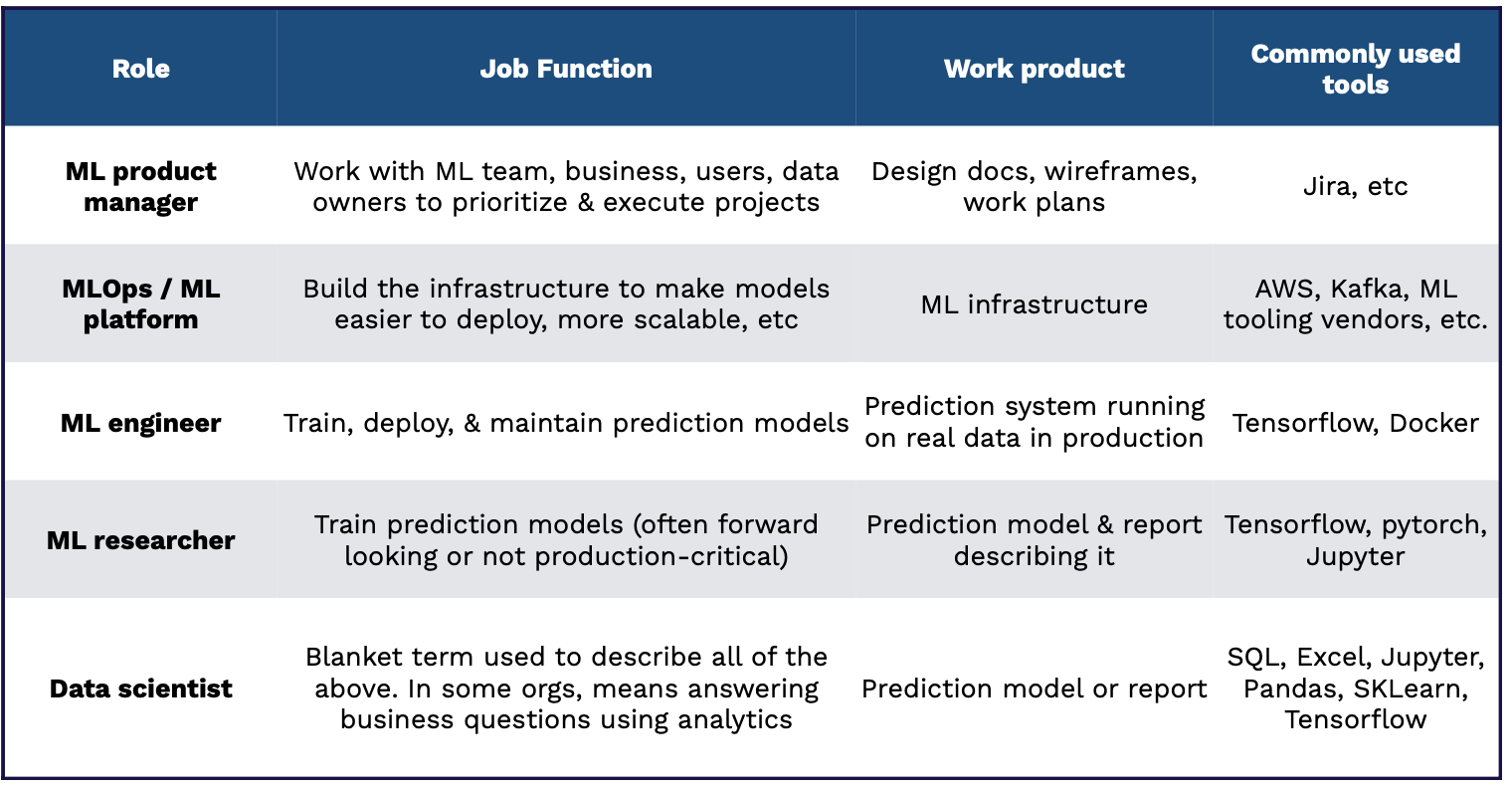
대표적인 롤
-
ML Product Manager : ML Product Manager 는 ML 팀, 비즈니스 영역, 제품 유저, 데이터 오너 간 협업하여 도큐먼트를 작성하고, 제품의 뼈대를 세우고, 계획을 수립하고, 그 중 작업의 우선순위를 정해 ML 프로젝트를 진행하는 역할을 맡는다.
-
MLOps/ML Platform Engineer : 모델 배포 과정을 보다 쉽고 스케일링이 가능하도록 인프라를 설계하는 역할을 맡는다. 이후 AWS, GCP, Kafka, 혹은 다른 ML 툴을 활용해 배포된 제품의 인프라를 관리하는 역할을 수행.
-
ML Engineer : 모델을 학습하고 배포하는 역할. TensorFlow, Docker 등의 툴을 활용해 예측 시스템을 실제 데이터에 적용한다.
-
ML Researcher : 예측 모델을 학습하는 역할을 맡지만, 주로 최신 모델을 실험적인 환경에서 사용해보거나 이외 제품 적용이 시급하지 않은 문제를 다룬다. TensorFlow, PyTorch 등의 라이브러리를 노트북 환경에서 다루며, 실험 결과를 공유하는 역할을 맡는다.
-
Data Scientist : 위에 설명된 모든 역할을 포괄하는 단어. 조직에 따라 비즈니스 문제에 대한 해결을 구하는 분석가 역할을 수행할 수도 있으며, SQL, Excel, Pandas, Sklearn 등의 다양한 툴을 다룬다.
필요한 스킬
이러한 롤들을 수행하기 위해선 어떤 스킬셋이 필요할까? 하단 차트는 이러한 롤들이 필요로 하는 스킬셋을 도식화 한다 - 수평축은 ML 전문성을, 동그라미 크기는 커뮤니케이션과 기술 문서 작성에 대한 스킬을 뜻함.
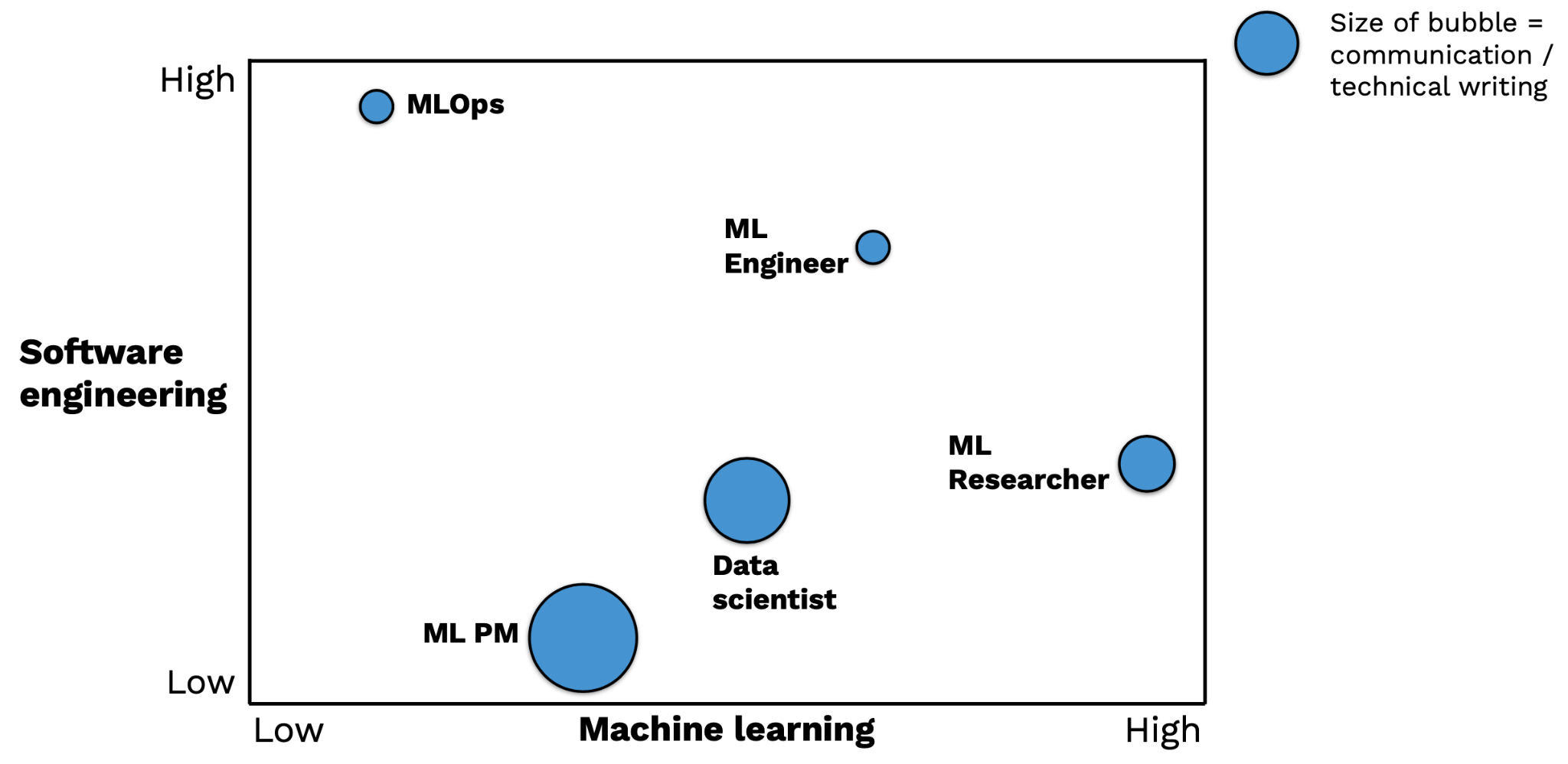
-
MLOps 란 기본적으로 소프트웨어 엔지리어링 롤이며, 기존의 소프트웨어 엔지니어링 파이프라인에 대한 이해가 필요하다.
-
ML Engineer 는 ML 과 소프트웨어 개발 기술에 대한 지식을 모두 요구한다. 이러한 요구조건은 시장에 흔하지 않으며, 상당한 self-study 를 거친 엔지니어, 혹은 소프트웨어 엔지니어로 근무하는 과학/엔지니어링 분야 박사 학위자가 적합.
-
ML Researcher 는 컴퓨터 공학, 통계학 등의 석/박사 학위를 소지하고 있는 ML 전문가가 적합하다.
-
ML Product Manager 는 기존의 Product Manager 의 역할과 크게 다르지 않지만, ML 제품 개발 과정과 관련 지식에 능통해야 한다.
-
Data Scientist 란 학사 학위자 부터 박사 학위자 까지 다양한 배경을 가질 수 있다.
-
버클리 EECS 박사 과정을 밟고 있는 Shreya Shankar 가 게시한 글에 따르면, ML 엔지니어는 Task ML 엔지니어, Platform ML 엔지니어로 세분화해 구분할 수 있다.
- Task ML Engineer 는 구체적인 ML 파이프라인을 관리하는 역할을 맡는다. 이러한 ML 파이프라인이 정상적으로 작동하는지, 주기적인 업데이트가 이루어지는지 등을 확인하며, 대체로 업무량이 많은 편.
- Platform ML Engineer 는 다른 ML Engineer 들이 수행하는 반복적인 작업들을 자동화 하는 업무를 맡는다.
Hiring
AI 역량 갭
-
FSDL 이 처음 시작된 2018 년의 경우 채용시장에서 AI 기술을 이해하는 인력을 찾기는 어려운 일이었다. 따라서 기업 내 AI 활용의 가장 큰 걸림돌은 인력 확보 문제였다.
-
2022년 현재, 이러한 채용시장 내 AI 역량에 대한 수요/공급 간 불균형은 여전히 존재하지만, 4년간 이루어진 관련 인력들의 커리어 전환, 이미 ML 수업을 수강한 학부생들의 시장 유입으로 어느 정도 해소된 면이 있다.
-
하지만 아직 시장에는 ML 이 어떻게 실패하고, ML 제품을 성공적으로 배포하는 방법을 아는 인력이 부족하다. 특히 제품 배포 경험을 가진 인력에 대한 품귀 현상이 존재.
채용 소스
- 이렇듯 작은 인력 풀과 급성장하는 수요로 인해 ML 직군 채용은 어려운 편이다. MLOps, Data Engineer, Product Manager 와 같은 롤은 많은 ML 지식을 요구하지 않기 때문에, 본 섹션에서는 코어 ML 직군에 대한 채용 방법을 설명한다.

-
위와 같은 완벽한, 그리고 비현실적인 JD 를 통한 채용은 잘못된 방식이다.
- 이보다는 소프트 엔지니어링 스킬셋을 갖춘 후보 중 ML 분야에 대한 관심이 있고, 배우고자 하는 인력을 추리는 편이 낫다. 기본적인 개발 역량이 있다면 ML 은 충분히 학습 가능한 영역이다.
- 주니어 레벨의 채용 또한 고려해 볼 수 있다. 최근 졸업생등은 ML 지식을 상당 수준 가지고 있는 편.
- 필요한 시킬셋이 무엇인지 가능한 자세히 기술하는 편이 좋다. DevOps 부터 알고리즘 개발까지 모든 ML 개발 과정에 능통한 인력을 찾기란 불가능하다.
-
ML Researcher 를 채용하기 위해 강사진은 다음과 같은 팁을 제시한다.
- 논문의 양보다는 질을 검토할 것. 아이디어의 독창성, 수행 방식 또한 면밀히 검증.
- 트렌디한 문제보다 본질적인 문제에 집중하는 연구자를 우선 채용할 것.
- 학계 밖에서의 경험은 비즈니스 환경 적응에 도움이 되기 때문에 이 또한 중요하다.
- 박사 학위가 없거나, 유사 분야인 물리학, 통계학 등을 공부한 인력 또한 진중하게 검토할 것.
-
좋은 지원자를 찾기 위해서는 다음과 같은 경로를 시도할 것.
- LinkedIn, 리크루터, 캠퍼스 방문 등 기존 채용 경로 검토.
- ArXiv, 유명 컨퍼런스 등을 모니터링하고, 마음에 드는 논문의 1 저자 플래그.
- 좋아하는 논문을 누군가 수준있게 구현한 경우 플래그.
- NeurIPS, ICML, ICLR 등 ML 컨퍼런스 참석.

-
리크루팅을 진행하면서 지원자들이 회사에 바라는 바를 파악하고, 이에 맞춰 회사를 포지셔닝 하는 과정이 필요하다. ML 전문가들은 흥미로운 데이터를 기반으로 영향력있는 일을 하고 싶어하기 때문에 배움과 영향력을 지향하는 문화를 만들고, 이를 통해 좋은 인력이 지원할 동기를 만들어 주어야 한다.
-
좋은 지원자를 모으기 위해선 채용을 진행중인 팀이 어떻게 우수하고, 미션이 어떻게 의미있는지에 대한 적극적이고 구체적인 설명이 곁들여져야 한다.
인터뷰
-
지원자를 인터뷰 할 때는, 지원자의 강점은 재확인하고, 약점은 최소 기준점을 충족하는지 확인하자. ML Researcher 의 경우 새로운 ML 프로젝트에 대해 창의적으로 생각할 수 있는지 검증이 필요하지만, 코드 퀄리티의 경우 최소한의 요건만 충족하면 된다.
-
ML 인터뷰는 기존 소프트웨어 엔지니어링 인터뷰에 비해 덜 성숙한 분야이다. Chip Huyen 의 Introduction to ML Inteviews Book 과 같은 레퍼런스를 참조.
Organizations
- ML 팀의 구성이란 아직 정답이 존재하지 않는 영역이다. 하지만 조직 내 ML 활용 특성과 성숙도에 따라 존재하는 best practice 는 다음과 같이 정리할 수 있다.
타입 1 - 초기단계 혹은 Ad-Hoc 성 ML
- 사실상 조직 내 ML 활용이 없으며, 필요시 단발성 프로젝트가 진행되는 경우. 인하우스 ML 전문성은 매우 낮은 편이다.
- 중소규모의 비즈니스이거나, 교육, 물류 등 상대적으로 IT 중요도가 낮은 분야일 것.
- ML 적용으로 인한 단기적 이점이 상당히 적은 편.
- ML 프로젝트에 대한 지원이 적으며, 좋은 인력을 채용하고 유지하는 것에 상당한 어려움이 있다.
타입 2 - ML R&D
- 조직 내 대부분의 ML 관련 업무가 R&D 에 치중되어 있는 경우. 대부분의 채용이 논문 작성 경험이 있는 ML Researcher, 박사 학위자를 대상으로 한다.
- 에너지, 제조, 통신 등의 분야에서 규모가 큰 회사일 가능성이 높다.
- 경험이 많은 연구 인력 채용을 통해 long-term 비즈니스 문제를 해결할 역량을 가지고 있다.
- 하지만 질좋은 데이터 확보가 어려우며, 연구에서 실제 비즈니스 가치를 가진 제품 개발까지의 과정이 잘 이루어지지 않는다. 따라서 투자 규모 또한 작은 편.
타입 3 - 비즈니스 & 제품 팀 내 적극적인 활용
- 특정한 제품이나, 사업 영역에 속한 소프트웨어, 분석 인력이 이미 ML 전문성을 확보하고 있는 경우이다. 이러한 ML 인력은 소속된 팀의 엔지니어링/기술 담당자에게 보고하는 구조를 가진다.
- IT 회사이거나, 금융 회사일 가능성이 높다.
- 이러한 경우 ML 제품 개선은 직접적인 비즈니스 가치를 준다. 또한 아이디어 제시와 제품 개선 간 밀접한 피드백 사이클 또한 존재.
- 하지만 높은 수준의 인력을 채용하는 것은 여전히 어렵고, 연산 자원이나 데이터 등을 확보하는 것에 많이 시간이 소요될 수 있다.
타입 4 - 독립적인 ML 기능
- ML 부서가 별도 조직으로 구성되어, senior management 에게 직접 보고하는 경우. ML Product Manager 가 연구자, 엔지니어와 협업해 클라이언트가 사용하는 제품을 개발하며, 장기적인 연구 또한 진행한다.
- 규모가 큰 금융 회사일 가능성이 높음.
- 수준높은 인력을 보유하고 있기 때문에 추가적인 인력 소싱이 쉬운 편이다. 데이터와 연산 자원이 수월하게 배분되며, ML 개발과 관련된 여러 문화와 규율을 형성할 조건이 마련된다.
- 하지만 사업 영역에 따라 ML 활용에 대한 이점을 설득하거나, 모델에 대한 기초적인 내용을 교육하는 것에 많은 노력이 들 수 있다. 또 피드백 사이클 또한 빠르게 전개되지 못할 것.
타입 5 - ML 우선주의
- CEO 의 직접적인 투자가 이루어지며, 비즈니스 전반에서 관련 전문 인력이 빠른 성과를 내기위해 노력한다. 별도의 ML 조직은 난이도가 높고, 호흡이 긴 프로젝트를 주로 전담.
- 규모가 큰 IT 회사, 또는 ML 분야 스타트업이 이에 해당한다.
- 데이터 접근이 쉽고, ML 전문가가 선호할만한 문화/환경을 가지고 있다. 개발직군 또한 ML 에 대한 이해가 높기 때문에 개발 과정이 수월한 편.
- 하지만 ML 관점의 생각을 비즈니스 전반에서 가지기는 어려우며, 현실적으로 구성되기 어려운 조직 환경.
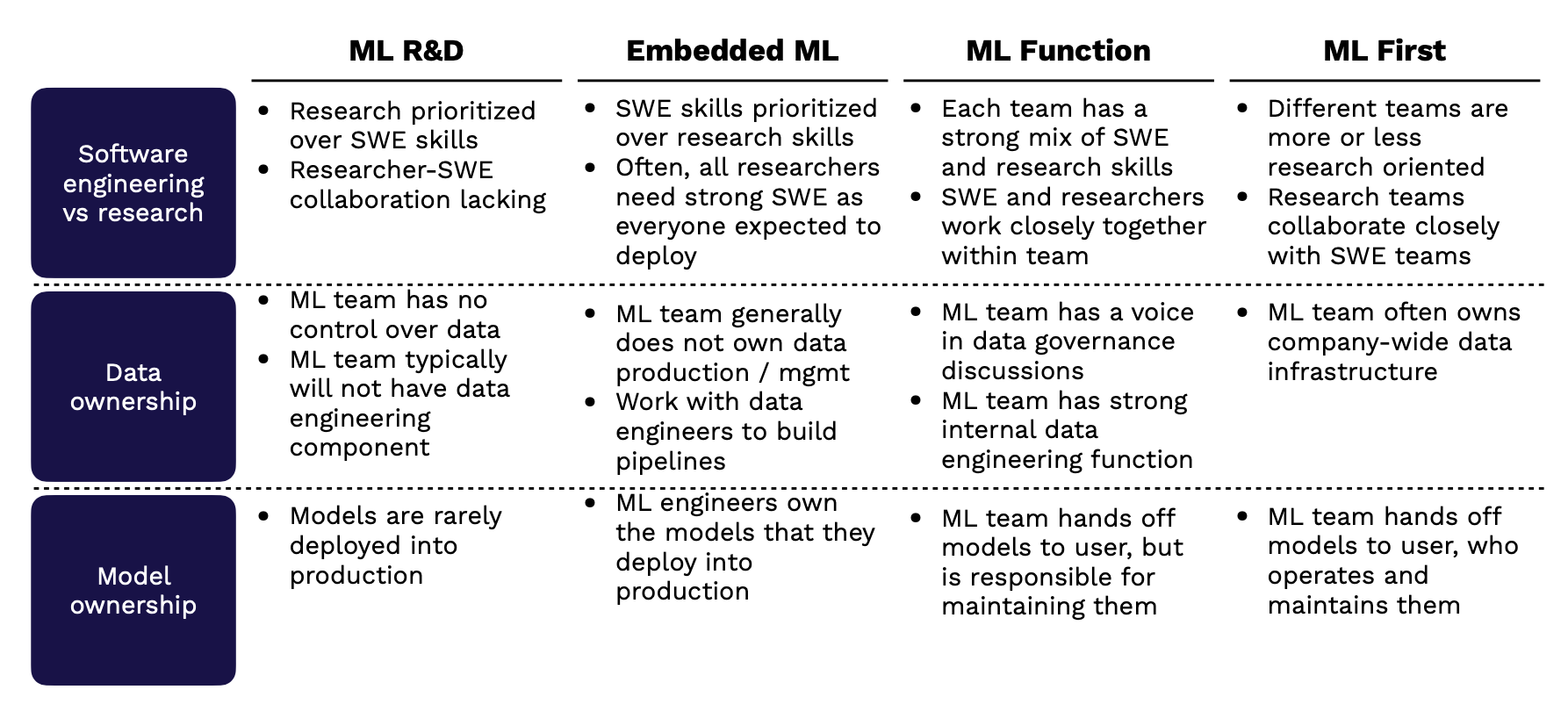
조직 구성 전략
-
자신의 조직의 상단의 5개 타입 중 어느 타입에 가장 가까운지에 따라 적절한 조직 구성 전략을 선택하는 과정이 필요하다. 강사진이 정리한 조직 구성 전략은 크게 다음과 같은 영역에서 정의된다.
- Software Engineer vs. Research : 소프트웨어와의 연동성을 위해 ML 팀이 어느 정도까지 관여하는가? 팀 내 소프트웨어 엔지니어링 역량은 어느 정도의 중요성을 가지는가?
- Data Ownership : 데이터 수집, 웨어하우징, 레이블링, 파이프라이닝 과정에서 ML 팀은 어느 정도의 권한을 가지는가?
- Model Ownership : ML 팀은 개발된 모델의 배포까지를 담당하는가? 이렇게 배포된 모델은 누가 관리하는가?
-
다음 섹션은 조직 특성에 따른 구성 전략을 간단히 설명한다.
-
조직이 ML R&D 에 집중하는 경우.
- 개발 보다는 연구 역량이 더욱 중요시되기 때문에, 두 담당 영역간 협업 능력이 다소 저하될 수 있다.
- ML 팀은 데이터에 대한 권한을 가지지 않으며 데이터 엔지니어의 지원을 받지 않는다.
- 사실상의 ML 제품화는 발생하지 않는다.
-
이미 제품 내 ML 활용이 이루어지는 경우.
- 연구 보다는 개발 역량이 중요시되며, 연구직 또한 적절한 엔지니어링 역량을 보유해 연구 단계 이후 제품화를 감안해야 한다.
- 데이터 관리와 생성에 대한 권한을 가지지 않는다. 데이터 엔지니어의 지원을 통해 데이터 파이프라인 구축.
- ML Engineer 들은 배포되는 모델에 대한 모든 권한을 가지게 된다.
-
별도의 ML 조직이 구성된 경우.
- 모든 팀은 연구 & 개발 인력을 보유할 수 있으며, 팀 내 협업이 긴밀하게 이루어진다.
- 데이터 거버넌스, 엔지니어링 관련 논의에서 보다 힘이 실린 의견표출이 가능하다.
- 모델은 유저에게 배포되지만, 이를 관리하는 책임은 유지된다.
-
ML 우선주의가 존재하는 경우.
- 연구 분야에 중점이 있지만, 연구자들 또한 개발 인력과 긴밀히 협업한다.
- 전사 데이터 인프라에 대한 권한을 소유하게 된다.
- 배포된 모델에 대한 관리/운영 책임은 유저에게 있다.
Managing
Managing ML teams is challenging
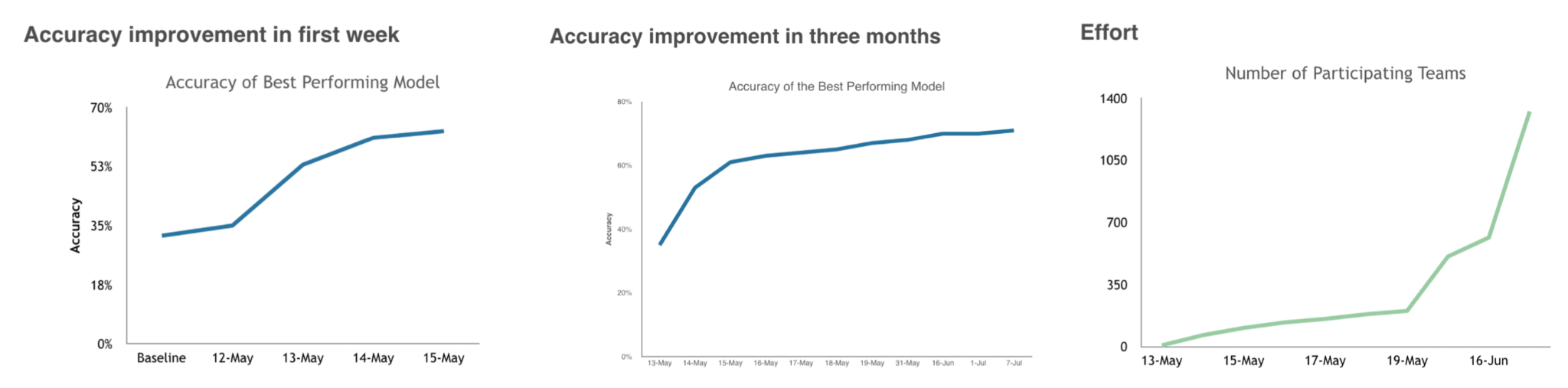
- ML 팀 운영이 어려운 이유로는 다음과 같은 4가지를 들 수 있다.
-
공수 예측 : ML 프로젝트란 착수 전 난이도를 측정하기 애매한 측면이 존재한다. 데이터를 조회하고, 여러 모델을 적용해보며 새로 습득해야 하는 정보가 무궁무진하며, 이는 프로젝트 타임라인 설정에 차질을 줄 여지가 많다. 또한 어떠한 모델이 잘 작동할지 사전에 파악하는 것은 불가능하다.
-
비선형적인 업무 진전도 : Weights and Biases 의 CEO 인 Lukas Biewald 가 쓴 이 블로그 포스트에 의하면, ML 프로젝트의 진전 상황과 무관하게 앞으로의 상황을 예측하기 어려운 경우가 많다 (상단 그래프 참조).
-
문화 차이 : 엔지니어링과 연구 분야는 서로 크게 다른 문화를 형성하고 있다. 연구 분야는 새롭고, 독창적인 생각을 선호하는 반면, 엔지니어링 분야는 검증된 방법을 선호하기 때문. 이로 인해 ML 조직은 빈번하게 문화 충돌로 인한 갈등을 경험하며, 이와 같은 갈등은 제대로 다뤄지지 않을 시 조직 운영에 치명적인 결과를 초래할 수 있다. 따라서 ML 조직 운영의 주요 과제 중 하나는 ML, 소프트웨어 엔지니어링 분야 간 협업을 이끌어 내는 부분이다.
-
리더십의 도메인 이해 결여 : 조직의 리더십이 ML 기술을 구체적으로 이해하고 있는 경우는 흔치않다. 따라서 기술을 한계를 명확하게 전달하고, 올바른 기대치를 심어주는 과정에 어려움이 따를 수 있다.
-
How to manage ML teams better
-
ML 조직의 관리는 아직 체계가 확립되지 않은 분야지만, 다음과 같은 노력을 통해 개선이 가능하다.
-
확률적 계획 수립
- 대부분의 ML 프로젝트는 단계적인 태스크를 명확하게 정의한 후 시작한다. 하지만 이와 같은 엔지니어링적 접근 보다는, 각 태스크에 대한 성공 확률을 부여해 ML 프로젝트는 근본적인 실험성을 동반한다는 점을 사전에 인지하는 편이 좋다.

-
다양한 접근 방법 구비
- 제품 개발 계획을 세우는 단계에서 한 개 방법의 성공에 의존하는 것은 위험하기 때문에, 가능한 많은 아이디어와 접근 방법을 포용해야 한다.
-
아웃풋 보다는 인풋을 기반으로한 업무 평가
- 여러 방법을 수행하면서, 성공 여부를 기반으로 팀원의 기여도를 측정하는 것은 적절치 않다. 이와 같은 방법의 평가는 안전하고, 검증된 접근법만을 독려해 전반적인 팀의 상상력, 독창성을 저해할 수 있기 때문. ML 제품의 성공을 위해서는 새로운 아이디어를 높은 수준으로 검증하는 과정이 필요하다.
-
연구자, 엔지니어 간 협업
- 엔지니어링과 연구 부서 간 협업은 수준있는 ML 제품 개발을 위해 필수적이다. 따라서 이들 그룹 간 협업을 독려하고, 이끌 필요가 있다.
-
빠른 성과 추구
- 이와 같은 방법은 리더십에게 프로젝트의 진전도를 보다 효과적이고, 명료하게 전달할 수 있도록 하며, 장기적으로 ML 프로젝트가 성공하는데 도움을 준다.
-
불확실성에 대한 리더십의 충분한 이해
-
조직의 리더는 타임라인 상 위험요소에 대해 명확하게 이해하고 (understanding timeline risk), 불확실성을 해소할 책임이 있기 때문에 (addressing blind spots) ML 개발의 본질적인 불확실성을 전달하는 과정에서 어려움이 따를 수 있다. 하지만 다음과 같은 접근을 통해 리더십의 ML 이해도를 높이는 것이 가능하다.
-
ML 영역에 한정된 KPI 를 지나치게 강조하는 것은 좋지 않은 방법이다 (예. F1 스코어를 0.2 개선해 모델 성능이 상당 부분 개선되었다 등의 코멘트).
-
대신, 조직 구성원 대부분이 이해할 수 있는 리스크/임팩트 설명을 곁들이는 편이 좋다 (예. 모델 개선으로 인해 약 10% 전환율 상승이 예상되나, 추가적인 demographic 요소를 참조해 지속적으로 성능을 평가하는 과정이 필요).
-
this a16z primer, this class from Prof. Pieter Abbeel, and this Google’s People + AI guidebook 등의 리소스 공유를 통해 리더십의 ML 관련 이해도 제고.
-
ML PMs are well-positioned to educate the organization
-
ML Product Manager 직군은 크게 두 개 타입으로 구분 가능하다.
-
Task PM : 보다 일반적인 ML PM 모습에 가깝다. 특정 분야에 전문성을 가지고 있고 (예. 안전 정책) 관련해 세부적인 유즈케이스에 많은 경험을 가지고 있다.
-
Platform PM : 최근 등장한 PM 직군 형태. Task PM 보다 넓은 영역에서 (우선순위 설정, 워크플로우 관리 등) ML 팀을 지원할 책임을 가지고 있다. ML 에 대한 보다 넓은 이해를 가지고 있고, 조직 전반에 걸쳐 ML 이해도를 높이고, 모델의 아웃풋을 신뢰할 수 있도록 돕는다.
-
-
ML 제품의 성공을 위해서는 두 개 타입의 PM 모두 중요한 역할을 수행하며, 특히 Platform PM 은 조직 전반에서 ML 제품 영향력을 키우는 역할을 수행한다.
What is “Agile” for ML?
- Agile, 소프트웨어 간 관계는 다음 두가지 옵션과 ML 간 관계와 유사하다.
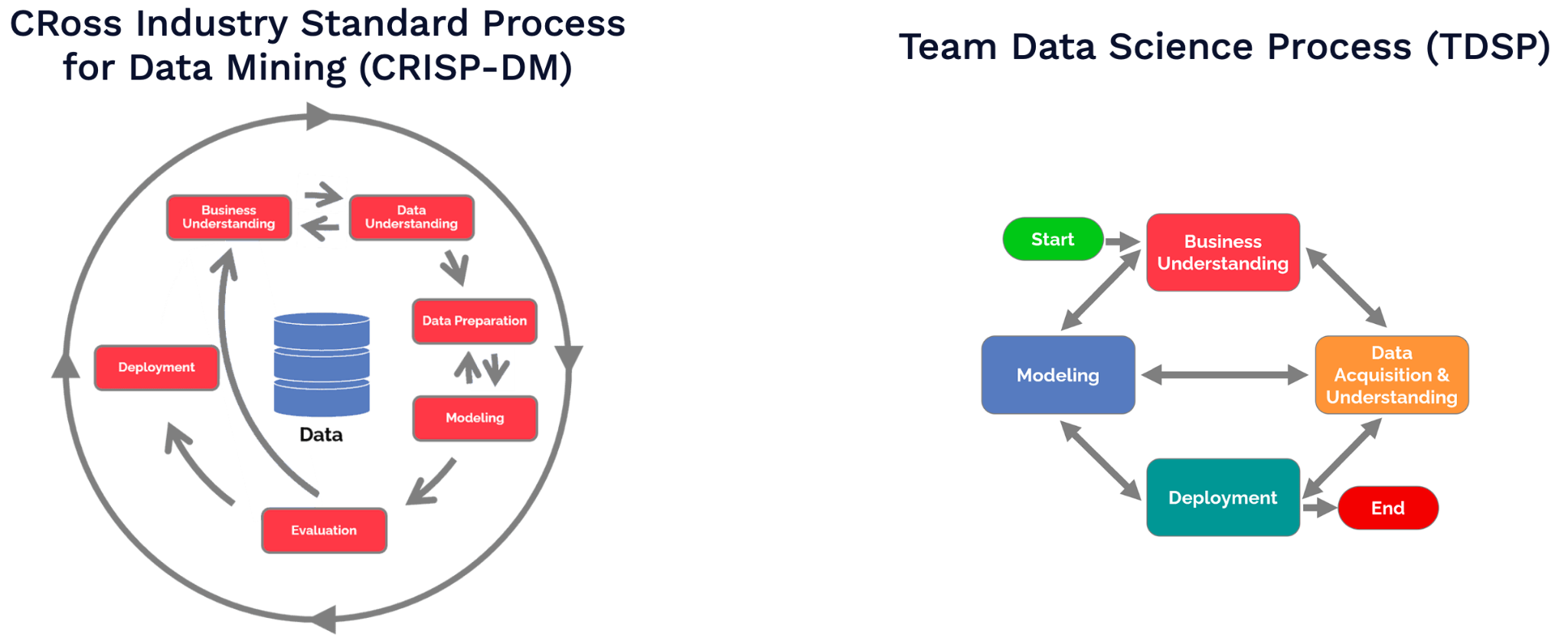
-
CRISP-DM, TDSP 모두 구조적이고, 데이터 사이언스 분야에 특화된 프로젝트 관리 방법론이다. 이들 모델을 활용해 프로젝트의 단계, 역할, 산출물 등을 통용/약속된 방식으로 정의할 수 있다.
-
TDSP 는 보다 구조적이며, Agile 방법론에 대한 직접적인 대체제이다.
-
CRISP-DM 은 보다 상위 레벨의 개념들을 다루며, 프로젝트 관리 체계의 정의가 약한 편이다.
-
-
스케일이 큰 프로젝트 진행 시 이러한 프레임워크 적용을 고려해 볼 수 있지만, 그렇지 않은 경우 이를 강제할 필요는 없다. 이들 프레임워크가 머신러닝 보다는 전통적인 데이터 사이언스 문제를 기반으로 하기 때문.
Design
-
대부분의 경우, ML 제품 기획에서 가장 어려운 부분은 제품 구현이 아닌 유저의 기대치와 실현 가능한 제품의 수준 간 격차를 좁히는 일이다.
-
ML 시스템을 접한 유저는 대게 고도로 개발된, 실제 가능한 것보다 더 많은 문제를 풀 수 있는 시스템을 기대하기 마련이다.

- 하지만 현실 세계의 ML 시스템이란 특정 작업을 위해 훈련된 강아지와 같다. 집중력에 한계가 존재하고, 학습 받지 않은 작업을 수행하기 어려워 하는 경우가 대부분이기 때문.

The Keys to Good ML Product Design
-
유저는 제품 사용으로 얻을 수 있는 장점과 한계를 명확히 이해했을때 더 높은 만족도를 보인다.
- “AI-powered” 라는 캐치 프레이스를 사용하기 보다는, 실제 모델이 해결하는 문제에 집중할 것.
- 시스템 설계를 사람과 같이 느껴지도록 구성하였다면, 유저가 이를 실제 사람과 같이 다룰 것으로 기대할 것.
- Amazon Alexa 와 같이 특정 상황에 ML 이 어떻게 대처할 것인지를 사전에 정의하는 것 또한 검토.
-
모델이 실행에 실패했을때를 대비한 백업 플랜을 준비할 것.
-
지나친 자동화는 오히려 유저 경험의 질을 떨어트릴 수 있다.
-
피드백 룹 구축을 통한 지속적인 모델 개선으로 유저 경험을 개선할 것.
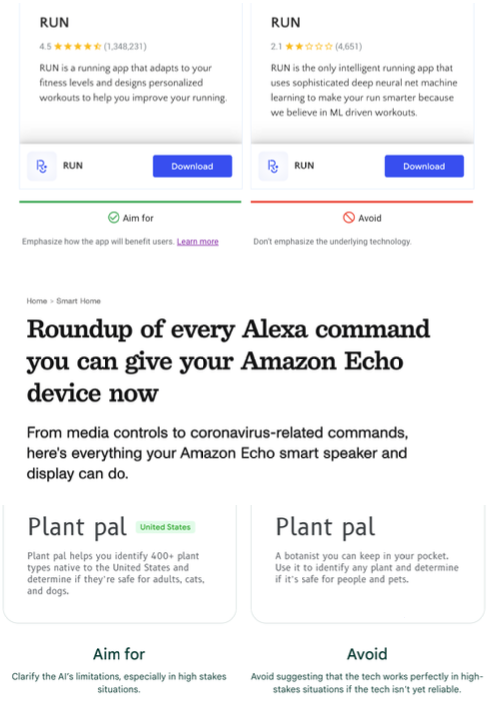
- 실패 관리는 ML 시스템 유저의 만족도 제고를 위한 핵심적인 요소이다. 유저가 직접 잘못된 아웃풋을 수정하는 기능을 추가하거나, 특정 임계점을 넘은 경우에만 결과값을 보여주는 등의 Quality Assurance 체계가 필요하다 (예. 페이스북이 사진에 포함된 얼굴을 기반으로 친구 태깅을 추천하지만, 직접적으로 수행하지는 않는 것과 같은 경우).
Types of User Feedback
- 이러한 문제 해결을 위해 유저의 피드백을 깊게 살필 필요가 있으며, 피드백은 다음과 같이 구분 가능하다 (x축이 모델 개선 과제 내 유용성, y축이 유저 난이도).
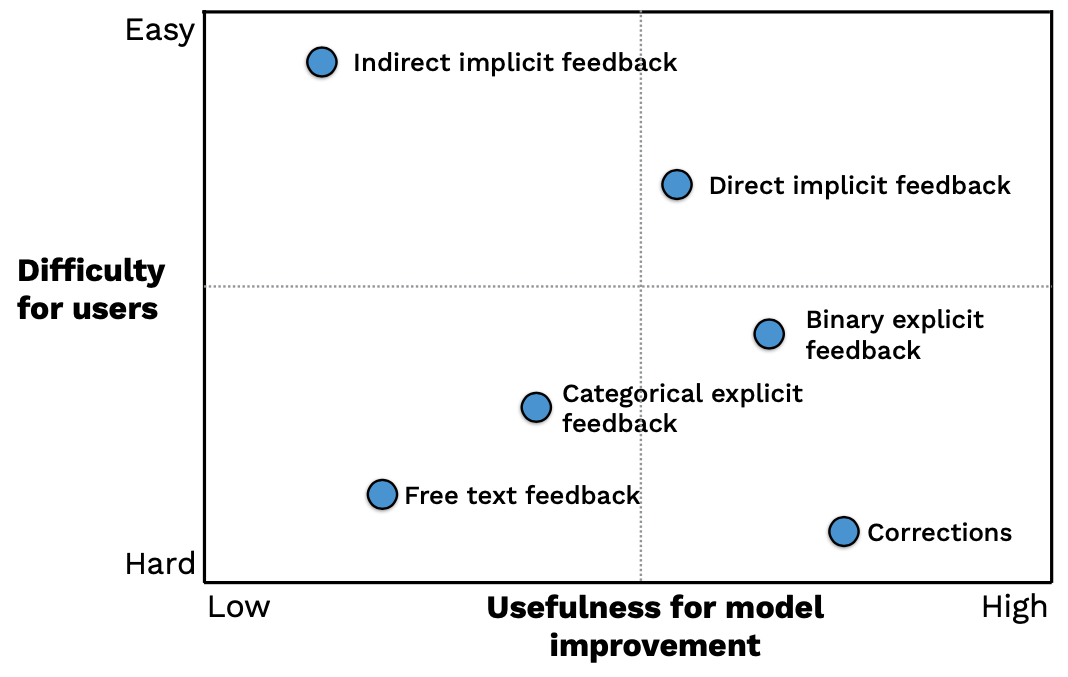
- 간접적, 암시적 피드백 (indirect implicit feedback) : 유저가 제품 구매 과정에서 이탈했는지 등의 정보.
- 직접적, 암시적 피드백 (direct implicit feedback) : 유저가 제품 구매 과정의 다음 단계로 이동했는지 등의 정보.
- 이항적, 명시적 피드백 (binary explicit feedback) : 좋아요/싫어요 등 제품 만족도를 두 개 옵션 중 하나로 특정하는 경우.
- 범주적, 명시적 피드백 (categorical explicit feedback) : 별점 등 제품 만족도를 여러개의 옵션 중 하나로 특정하는 경우.
- 자유적 피드백 (free text feedback) : 유저의 자유로운 텍스트 피드백.
- 모델 보정 (model corrections) : 유저의 직접적인 데이터 레이블링.
- 이러한 피드백 체계를 구축할 때에는 유저의 이타심에 기대는 것 보다는, 피드백을 제공하는 것이 유저에게 어떤 가치를 제공하는지 적극적으로 설명하는 편이 낫다. 또한, 유저 피드백에 따른 모델 개선이 실제로 빠르고 직접적으로 작동할 수 있도록 구성되어야 한다.