소개
2012년 토론토 대학의 Alex Krizhevsky 팀이 공개한 AlexNet 은 ILSVRC-2012 대회에서 2등 모델의 정확도 26.2%를 10% 이상 상회하는 15.3% 의 정확도를 기록해 많은 관심을 받았던 CNN 구조이다. 특히 GPU 를 활용한 연산가속이 컴퓨터 비전 커뮤니티에서 적극적으로 사용되는 것에 기여하였으며, 이외에도 ReLU 활성화 함수, Overlapping Pooling 등 ‘22년 현재 당연하게 받아들여지는 CNN 구조를 정립했다.
코드 예시
아래는 Paperspace 의 구현예시 이다. 논문에서 보이지 않는 디테일은 다음과 같다.
- Convolution 레이어와 FC 레이어가 분리되어 있다.
- Output 의 클래스 수를 설정할 수 있다. 기본값은 논문과 같은 1,000 으로 설정.
라이브러리 :
|
|
데이터 로딩 :
|
|
모델 본문 :
|
|
하이퍼파라미터 세팅 :
|
|
학습 과정 :
|
|
테스팅 과정 :
|
|
ImageNet (ILSVRC)
- 스탠포드 대학 교수인 Fei-Fei Li 가 주로 알고리즘 위주의 연구가 이루어지던 당시 AI 분야에 기여하기위해 2009년 공개한 이미지-레이블 데이터셋이다.
- 매년 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 라는 레이블 예측 대회를 개최하고 있으며, 2012년 기준 약 120만개의 이미지-레이블 셋으로 이루어져 있었다 (22년 현재 1,400만).
- Top-1 에러율, top-5 에러율 등으로 모델의 정확도를 평가하는데, 여기서 top-5 에러란 likelihood 가 가장 높은 5개 레이블에 실제 레이블이 포함되지 않은 경우를 가르킨다.
 |
|---|
| Fig 1. ImageNet 데이터 예시 |
CNN 구조
ReLU Nonlinearity
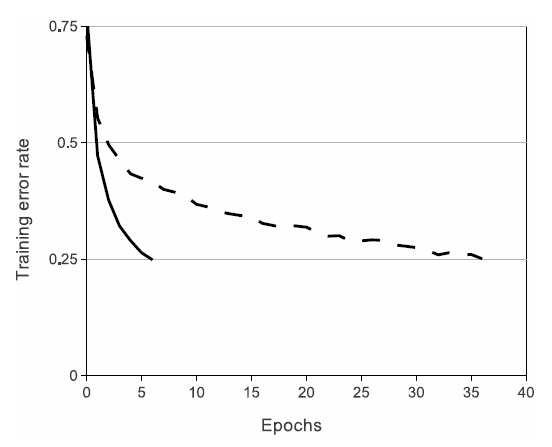
- 논문이 게재되던 시점 CNN 구조에서 주로 사용되던 tanh, sigmoid 활성화 함수는 학습 속도가 느리다는 문제점을 안고있다. 따라서 AlexNet은 Nair and Hinton 에서 처음 소개된 ReLU 활성화 함수를 사용해 학습속도를 단축시킨다 (fig 2. 참조).
- 논문은 ReLU activation function 을 다음과 같이 정의한다.
$$ f(x) = max(0,x) $$
- ReLU 활성화를 사용하게 된 배경에는 2012 당시 AlexNet 의 구조가 기타 CNN에 비해 복잡하고, 크다는 점이 있었다 (‘92년 공개된 LeNet-5 가 대략 6만개의 학습 가능한 파라미터를 가지고 있는 반면, AlexNet은 6천만개의 파라미터를 가지고있다).
 |
|---|
| Fig 2. CIFAR-10 데이터에 대한 ReLU (실선) vs. tanh (점선) 학습율 비교 |
Training on Multiple GPUs
- AlexNet 팀은 2012년 당시 최신 GPU 였던 NVIDIA GTX 580 2대를 활용해 모델을 학습시켰다. 각 GPU는 3GB 의 메모리를 가지고 있었으며, 적은 메모리 용량으로 인해 한대의 GPU를 사용해 전체 ImageNet 데이터를 학습하는 것이 불가능했다.
- 2대의 GPU는 서로의 메모리에 직접적으로 접근할 수 있으며, 학습 과정에서의 병렬처리는 뉴런, 또는 커널을 반으로 나눠 각 GPU 에 할당하는 방식을 취한다. 다만 모든 레이어에서 커뮤니케이션이 이루어지는 것은 아니고, 특정 레이어에서만 이러한 기능을 활용해 리소스를 관리한다.
- GPU 병렬처리는 학습 시간을 단축시킬뿐만 아니라, GPU 한대에서 처리가능한 사이즈의 네트워크에 비해 top-1 과 top-5 에러율을 각각 1.7% 와 1.2% 감소시킨다.
Local Response Normalization (LRN)
- ‘22년 기준 최신 CNN 구조에서는 잘 사용되지 않는 개념이다. AlexNet 이후 연구에 따르면 모델의 성능에 크게 기여하지 않는 것으로 밝혀졌다.
- ReLU 활성화 함수 사용으로 인풋 정규화를 반드시 사용해야할 이유는 없으나, AlexNet 의 경우 Local Response Normalization 이 모델의 일반화에 도움을 준다는 점을 발견했다.
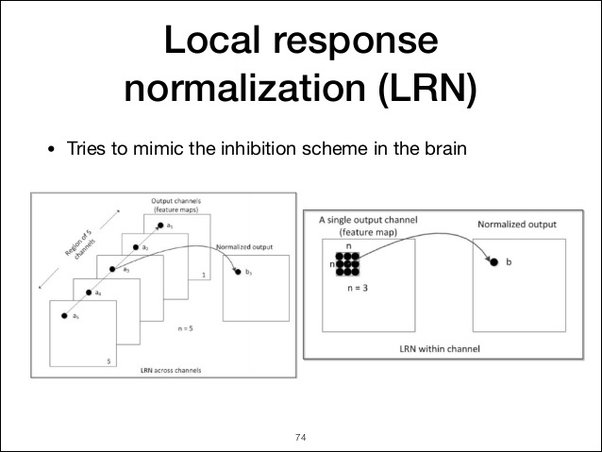
- 인접한 $n$ 개 채널에 대한 정규화라고 이해하면된다. 하단 슬라이드의 좌측 도표 참고.
 |
|---|
| Fig 3. Local Response Normalization 예시 |
- $a^i_{x,y}$ 가 채널 $i$ 에 대한 $x, y$ 좌표의 ReLU activation output 이라고 했을때, LRN 이 적용된 아웃풋 $b^i_{x,y}$ 는 다음과 같이 정의된다.
- $n$ 은 인접 채널 수를 특정하는 파라미터, $N$ 은 전체 채널 수
- 논문은 $k = 2$, $n = 5$, $\alpha = 10^{-4}$, $\beta = 0.75$ 로 설정
$$ b^i_{x,y} = a^i_{x,y}/(k + \alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a^j_{x,y})^2)^\beta $$
- 실제 인접 뉴런 간 정규화가 이루어지는 사람의 두뇌를 기반으로 하고있으며, top-1 과 top-5 에러율을 각각 1.4% 와 1.2% 감소시키는 효과를 보였다.
Overlapping Pooling
- ‘12년 당시 pooling layer 는 각각의 pool 이 겹치지 않도록 stride 를 설정하는 것이 일반적이었으나, 이를 서로 겹치도록 설정함으로 top-1 에러율과 top-5 에러율을 각각 0.4% 와 0.3% 씩 감소시켰다.
- 기본적인 룰은 $z$ x $z$ 의 pooling kernel 에서 $z$ 보다 작은 stride 사이즈, $s < z$ 를 적용시키는 것이다. 논문에서는 $s=2$, $z=3$ 를 사용하였다.
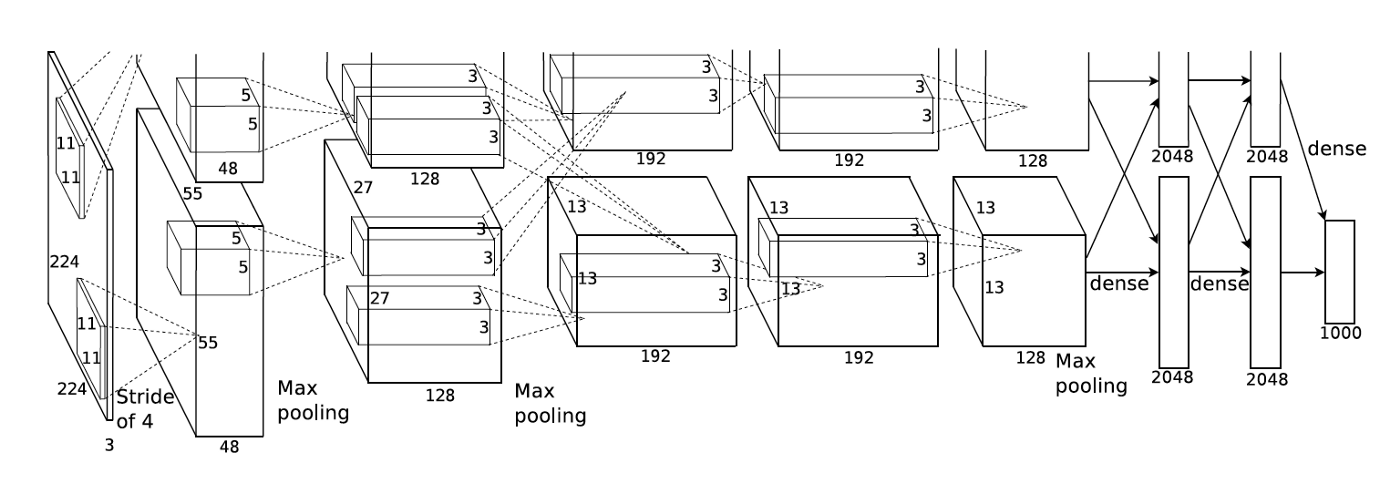
Overall Architecture
- 총 8개의 레이어를 가지고 있으며, 5개의 convolution 레이어 후 3개의 FC 레이어를 가지는 전형적인 CNN 구조이다. 마지막 FC 레이어는 1,000 개의 뉴런을 가지고 있는데 이에 softmax 함수를 적용해 클레스 레이블을 유추한다.
- 2번, 4번, 5번 convolution 레이어의 경우 GPU 간 소통이 이루어지지 않는다. 따라서 같은 GPU 의 메모리에 속한 뉴런과의 관계만을 통해 학습을 진행한다. FC 레이어의 경우 앞선 레이어의 모든 뉴런과 연결되어있다.
- 1번, 2번 convolution 레이어에만 LRN 이 적용된다. 해당 2개 레이어와 5번 convolution 레이어는 또한 Max Pooling 레이어를 가지고 있다.
- 모든 convolution 레이어와 FC 레이어에 ReLU 활성화가 적용된다.
- 최초 인풋 사이즈는 227 x 227 x 3 이다 (논문에는 224 x 224 x 3 으로 잘못 표기되어있는 것으로 보인다).
 |
|---|
| Fig 4. AlexNet 구조 (실제 논문 또한 이미지의 상단이 잘려있다) |
Overfitting
AlexNet 은 약 6천만개의 파라미터에 대한 과적합을 방지하기 위해 다음 두가지 방법 (Data Augmentation 과 Dropout)을 사용한다. Dropout 을 사용한 초기 아키텍쳐 중 하나이며, PCA Color Augmentation 개념이 조금 어렵게 다가온다.
Data Augmentation
아래 translation, reflection 및 PCA color augmentation 기법을 통한 데이터 증강은 학습 과정과 병행되며 (디스크에 저장하지 않는다), GPU 가 아닌 CPU 에서 별도로 처리되기 때문에 사실상 연산에 부담을 주지 않는다.
Translation & Reflection
- 256 x 256 이미지에서 랜덤하게 추출된 5개의 224 x 224 패치와 (4개의 코너 패치와 한개의 중앙 패치), 패치들에 적용된 좌우반전을 통해 10배 사이즈의 학습 데이터를 구축했다. 이후 이 10개 증강 이미지에 대한 평균값을 통해 레이블을 예측하게 된다.
- 이러한 데이터 증강 없이 학습된 네트워크는 심각한 과적합 문제를 가지고있다. 네트워크의 큰 사이즈 때문이며, 데이터 증강 기법을 사용하지 않는다면 네트워크 사이즈를 줄이는 방법 밖에는 없다고 저자는 기술한다.
PCA Color Augmentation
- 데이터 증강을 목적으로 RGB 채널의 강도를 조정하는 방식이며, PCA 를 통해 얻은 채널 별 분산에 비례하는 난수를 각 채널에 더하거나 빼주게된다.
- PCA 는 한개의 이미지가 아닌 모든 학습 데이터의 RGB 채널값을 대상으로 적용하게 된다. 따라서 자연스러운 채널 별 분산치를 얻을 수 있다.
- 모든 RGB 픽셀 값에 대한 3 x 3 공분산 행렬의 eigenvector 를 $p$, eigenvalue 를 $\lambda$ 라고 칭하고, $\alpha$ 는 평균이 0, 표준 편차가 0.1인 Gaussian 분포의 난수일때, RGB 이미지 픽셀 $[I^R_{xy}, I^G_{xy}, I^B_{xy}]$ 에 다음의 값을 더하는 방식이다.
$$ [p_1, p_2, p_3][\alpha_1 \lambda_1, \alpha_2 \lambda_2, \alpha_2 \lambda_2]^T $$
- 개인적으로 아직 관련 이해도와 설명이 아쉽다. 차후 별도의 글을 통해 PCA 개념을 다시 짚어볼 계획.
Dropout
- 모델의 성능을 높이기 위한 가장 좋은 방식은 여러 모델의 결과값을 구해 평균을 내는 것이나, 모델의 규모가 너무 크기때문에 이는 현실적으로 어려운 접근법이다.
- 그 대안으로 논문은 0.5 의 확률로 개별 뉴런을 활성화하거나 비활성화하는 Dropout 방식을 제안한다. 이러한 확률로 비활성화된 뉴런은 순전파, 역전파 과정에 기여하지 않으며, 활성/비활성화의 사이클을 통해 여러개의 네트워크를 학습시키는 것과 동일한 결과를 얻을 수 있다.
- Dropout 방식은 뉴런이 다른 특정 뉴런에 지나치게 의존하는 것을 사전에 방지한다. 개별 뉴런이 이전 레이어의 activation 정보를 적절히 조합하도록 유도하는 구조이다.
- 테스트시에는 이러한 학습과정으로 인해 뉴런의 아웃풋값에 0.5를 곱하게 된다.
- AlexNet은 처음 2개의 FC 레이어에서만 Dropout 을 사용하고 있다.
Details of Learning
- 모델은 SGD 방식으로 학습되었으며, batch size는 128, momentum은 0.9, weight decay는 0.0005로 설정되었다.
- 모든 weight 는 평균이 0, 표준편차가 0.01 인 Gaussian Distribution 의 난수로 설정되었으며, 2번, 3번, 5번 convolution 레이어와 모든 hidden FC 레이어의 bias 값은 1로 설정되었다 (ReLU activation 에 양수값을 input 함으로 훈련으로 가속시키는 효과를 가짐; 나머지 bias 값은 0 으로 설정).
- learning rate 는 모든 레이어에 동일하게 적용되었으며, 학습과정에서 manual 하게 조정되었다.
- 최초 learning rate는 0.01 로 설정
- validation error rate 감소가 멈췄을 경우, learning rate 를 10 으로 나눔
- 학습 종료까지 총 세번의 learning rate 조정 발생
- 총 학습은 120만개의 이미지를 대상으로 90 사이클 진행.
Results
- ILSVRC-2010 데이터셋을 대상으로 top-1 에러율, top-5 에러율 각각 37.5% 와 17.0% 를 기록함 (대회 진행 시 우승 모델의 성능은 각각 47.1%와 28.2%).
- ILSVRC-2012 데이터셋의 test set label 은 ‘12년 당시 공개되지 않았음으로 validation error rate를 기록, 18.2%의 top-5 에러율을 보였다.
- 5개 CNN 구조의 평균값을 구했을때 16.4% 에러율 기록
- 6번째 convolution 레이어를 추가한 후, ‘11년 대회 데이터셋을 기반으로 fine tuning 을 진행했을때 16.6% 에러율 기록, 5개 CNN 모델의 평균값과 다시 평균을 내었을때 15.3% 의 에러율을 보였다
- 해당 대회의 2번째 높은 에러율은 26.2% 였음