소개
CRNN 구조는 학계에서 CNN/RNN 구조에 대한 연구가 탄력을 받고있던 2015년, 중국의 화중과기대에서 공개한 Scene Text Recognition (일상 이미지 속 테스트 인식 과제) 모델이다. 이후 어텐션 구조가 추가된 MA-CRNN 등 다양한 변형 모델이 공개되었으나, 현재까지 널리 쓰이는 오픈소스 OCR 라이브러리인 EasyOCR 의 문자 인식 모듈은 논문에서 공개된 모델 구조를 그대로 따르고있다 (참고로 해당 라이브러리의 문자 감지 모듈은 네이버의 CRAFT 모델을 사용한다).
 |
|---|
| Fig 1. EasyOCR, 다양한 언어의 문자 인식 예시 |
CRNN 이란 이름에서 보이듯 전통적인 CNN 과 RNN 의 구조를 합성한 형태를 가지고 있다. 자칫 트렌디한 두 구조를 엮어 이목을 끄려는 목적으로 보여질 수 있지만, Scene Text Recognition 이라는 적절한 과제 선정으로 관련 분야 연구에 적지않은 영향을 끼쳤다. 또한 두 모델 구조의 결합 후에도 단일 학습이 가능하다는 점, CTC 손실 함수 사용으로 프레임 별 레이블링 작업을 필요로 하지 않는다는 점에서 실사용도가 높다는 장점을 가지고있다.
네트워크 구조
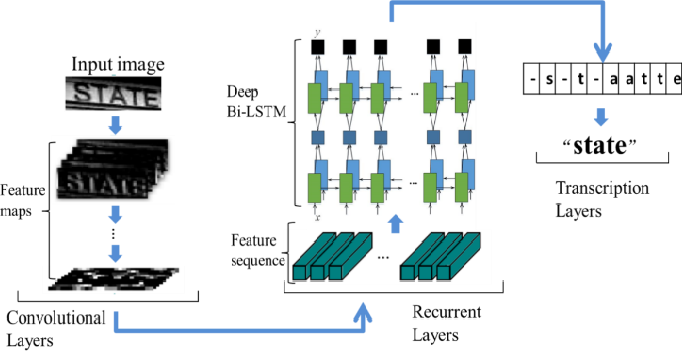
CRNN 네트워크는 크게 Convolution Layer (합성곱 레이어), Recurrent Layer (순환 레이어), Transcription Layer 3가지 모듈로 구성되어있다.
합성곱 레이어는 우선 이미지의 영역 별 feature 를 추출하며, 순환 레이어가 추출된 각 이미지 영역에 속한 텍스트를 순차적으로 예측하게 된다. 합성곱 연산은 단어 (word) 별 문자열 (character) 영역을 구분하지 못하기 때문에 추출된 feature 사이에 중첩 영역이 발생할 수 있는데 (예. -s-t-aatte) Transcription Layer 는 이를 실제 단어로 정리하는 역할을 수행한다 (예. state).
 |
|---|
| Fig 2. CRNN 기본 구조 |
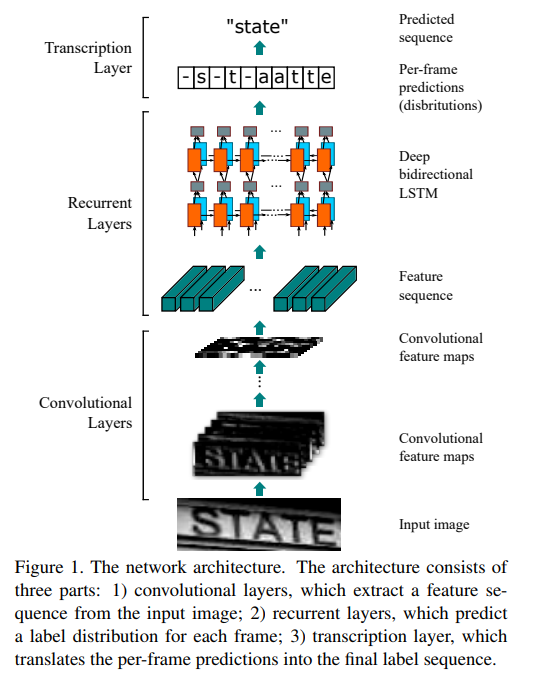
Convolution Layer
인풋된 이미지 데이터가 최초로 처리되는 영역이며 전통적인 CNN 구조에서 fully-connected layer 를 제외해 feature 아웃풋에 상응하는 원본 이미지의 영역 (receptive field) 이 특정되도록 설계되었다. 보다 디테일한 포인트들을 언급하자면 인풋 이미지는 항상 같은 높이값을 가지도록 조정되며, 아웃풋이 n 채널을 가진다면 동일한 영역에 대한 모든 채널의 합산 값을 feature 로 정의한다.
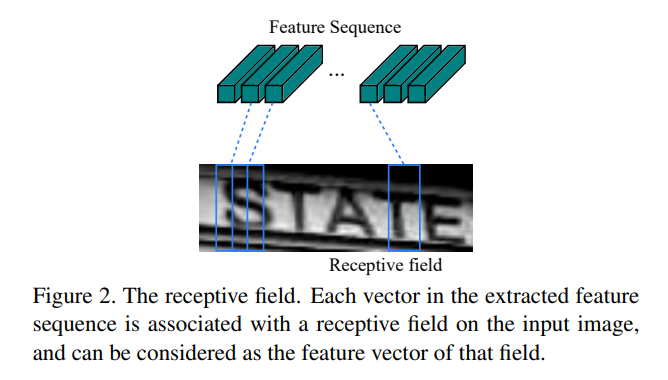
또한 이미지의 Text 영역이 이미 추출되었다고 가정하기 때문에 좌우 움직임을 가지는 영역 sequence 고려하게 된다 (인풋 이미지가 두 줄 이상이라면 처리가 어려울 것).
 |
|---|
| Fig 3. Feature Sequence 와 Receptive Field 간 1-to-1 매칭 예시 |
Recurrent Layer
합성곱 레이어에 의해 아웃풋된 feature sequence, $X = x_1, x_2, … , x_T$, 는 순서가 특정 가능하기 때문에 각 프레임 $x_t$ 에 대한 레이블 분포 $y_t$ 를 예측하는 순환 레이어의 인풋으로 활용된다.
논문의 저자는 RNN 구조 활용의 장점을 다음과 같이 정리한다.
- 이미지 context 에 대한 정보를 활용하기 때문에 이전 문자열 (character) 또는 단어 (word) 에 기반한 예측이 가능하며, 여러개 feature 영역 (receptive field) 이 한개 문자열에 걸쳐있는 경우, “il” 과 같이 상대적인 비교가 필요한 경우 또한 성능 향상을 기대할 수 있다.
- 역전파 수행이 가능하기에 CNN 레이어와 함께 학습할 수 있다.
- 인풋 sequence 의 길이가 중요하지 않다.
또한 저자는 sequence 간 거리에 비례해 발생하는 gradient vanishing problem, RNN 의 단방향성 문제 등을 해결하기 위해 당시 널리 사용된 Bidirectional LSTM 구조를 채택했다.
Transcription Layer
Transcription 이란 프레임 단위로 추출된 RNN 레이어의 예측값 (예. -s-t-aatte) 을 실제 단어로 (예. state) 변환하는 과정을 칭한다. 수학적으로는 RNN 레이어가 예측한 프레인 단위 시퀀스가 주어졌을때 가장 높은 확률을 가진 실제 단어 시퀀스를 연산하는 조건부 확률 모델이며, 저자는 예측 가능한 단어 시퀀스에 있어 실제 사전을 참조하는 lexicon 모드와 단순 확률값에 기반한 lexicon-free 모드를 모두 구현하였다. 또한 프레임 단위 시퀀스에 따른 조건부 확률은 Connectionist Temporal Classification (CTC) 에 기반하여 계산된다.
CTC
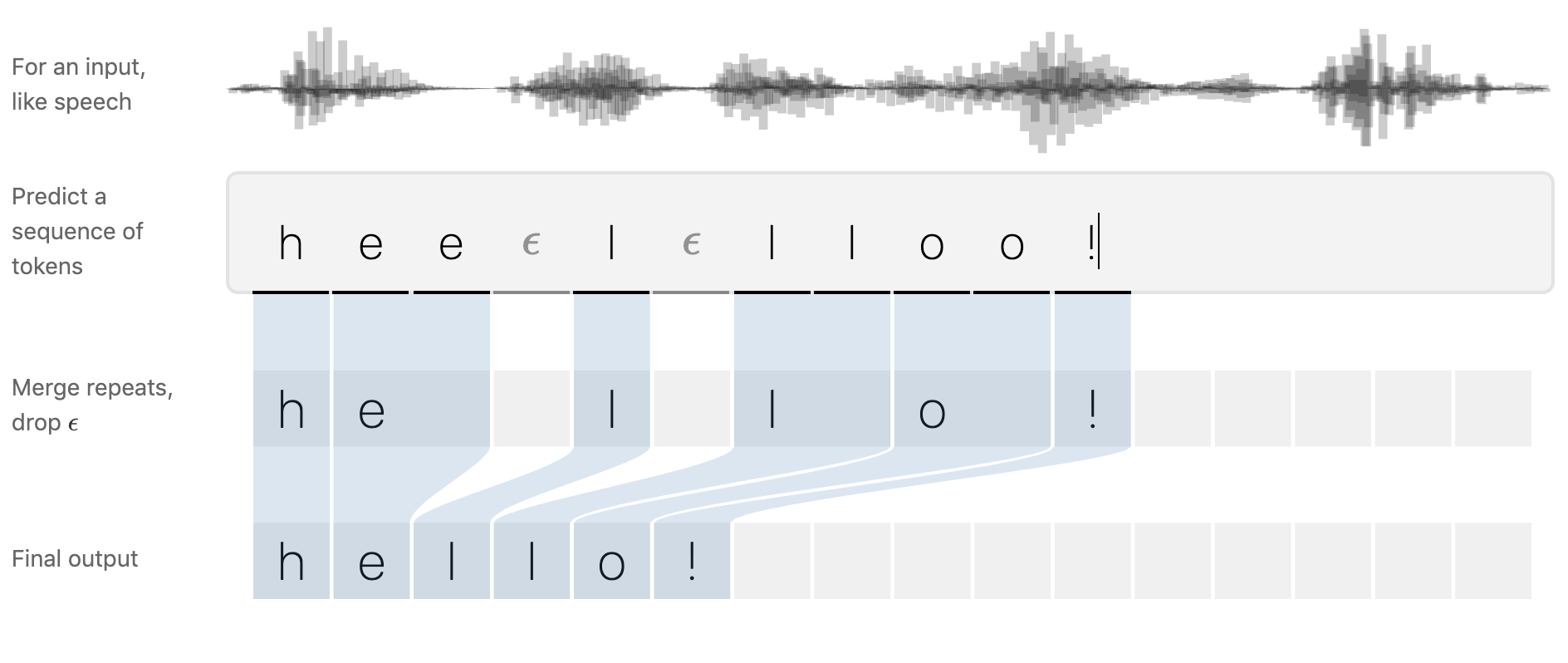
CTC 에 대한 개념은 사실 음성인식 문제를 해결하기 위해 등장했다. MFCC 와 같은 음성 피처는 대게 짧은 시간 단위로 쪼개서 생성하게 되는데, 전통적인 손실 함수를 이용하고자 한다면 이러한 프레임 각각에 레이블을 달아주어야 하기 때문에 공수가 크게 들고 정확도 또한 떨어진다는 문제가 발생한다. 때문에 CTC 는 음성 인풋의 프레임 시퀀스와 타깃 문자열 시퀀스간의 명시적인 alignment 없이 모델 학습이 가능하도록 고안되었다.
예측 파이프라인은 하단 도식화와 같이 구성된다. 우선 프레임 별 레이블을 예측한 후, 중첩되는 레이블을 하나로 묶어주는 작업과 (예. lll -> l) 공란을 뜻하는 epsilon 값에서 예측 값을 바꾸는 작업을 수행한다 (예. ee lll -> el). 보다 자세한 내용은 네이버 이기창님의 Ratsgo 블로그에 기술되어 있으니 참고하면 좋을듯 하다.
 |
|---|
| Fig 4. CTC Input 과 프레임 시퀀스 별 예측치, 최종 아웃풋 예시 |
Lexicon 활용
언어 예측 분야에서는 예측된 시퀀스의 품질을 보장하기위해 Hunspell Spell Checking Dictionary 와 같은 렉시콘 (Lexicon, 어휘 사전) 을 사용하고는 한다. 본 논문은 아웃풋이 이와 같은 렉시콘에 의해 처리된 lexicon-based mode, 그렇지 않은 lexicon-free mode 를 모두 구현하고 있다.
Lexicon-free Transcription
Lexicon-free mode 는 처리된 최종 레이블 시퀀스 아웃풋을 별도 검증 과정 없이 그대로 출력하게 된다. 상단 Fig 4. 의 “hello!” 예측값이 실제 사전에 존재하는지 여부는 고려되지 않으며, 인터넷 언어와 같이 어휘 검증이 어려운 경우 적합할 수 있다.
Lexicon-based Transcription
예측값을 어휘 사전과 비교해 아웃풋 가능한 레이블 시퀀스의 영역을 한정하게된다. 다만 어휘 사전이 클 경우 모든 레이블에 대한 비교에 지나치게 큰 연산 자원과 시간이 소모되기 때문에, 저자는 예측치와 어휘 사전에 포함된 단어들 간 거리를 계산한 후 가장 가까운 거리에 있는 어휘 사전 단어들로 탐색 영역을 한정하는 Nearest-Neighbor 방식을 사용한다.
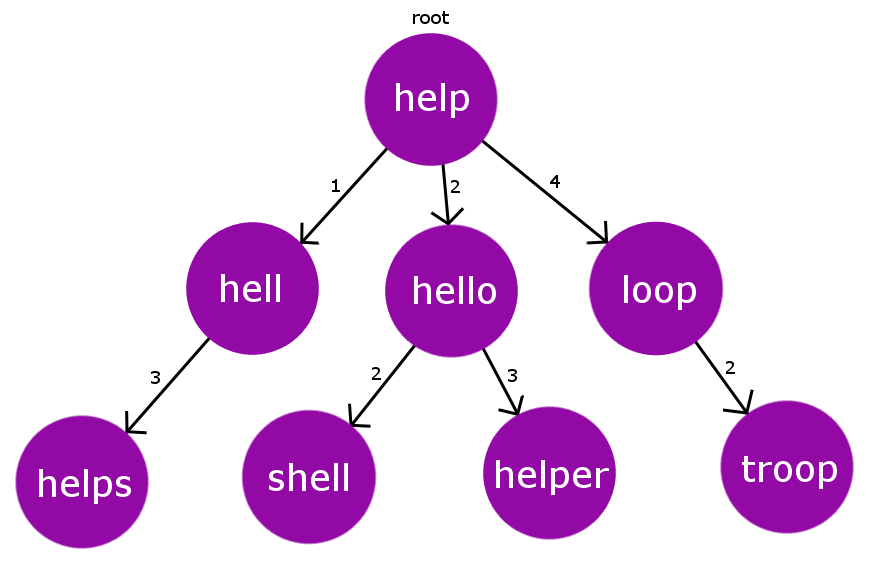
이때 거리란 단어 A 에서 단어 B 로 변형되기까지의 수정 횟수를 뜻하는 Levenshtein Distance 로 정의한다 (예. help 와 hello 간 거리는 help -> hell -> hello 두 번의 수정을 필요로 하기때문에 2가 된다).
Nearest-Neighbor 후보군을 탐색하는 과정은 Burkhard-Keller Tree (BK-tree) 데이터 구조를 활용해 효율적으로 수행이 가능하다. 이는 1973년도에 문자열에 대한 근사값을 빠르게 찾도록 설계된 트리 구조인데, 각 노드는 단어 정보를, 엣지는 단어 간 Levenshtein 거리값을 가지게 된다. 부모 노드에 연결된 자식 노드들은 모두 다른 Levenshtein 거리값을 가져야하며, 같은 거리값을 가진 단어가 추가된다면 중첩되는 단어의 자식 노드로 추가되는 식이다.
새로운 단어 (query) 에 가장 유사한 단어를 찾을때는 임곗값 (threshold) 을 특정해줘야 한다. 먼저 루트 단어 (root) 와 쿼리 단어 간 거리 $D = \text{Levenshtein}(\text{root}, \text{query})$ 를 측정한 후, 해당 거리가 임곗값보다 크다면 $D - \text{threshold}$, $D + \text{threshold}$ 사이의 엣지값을 가진 자식 노드들에서 동일한 작업을 재귀적으로 수행한다. 이 과정에서 임곗값 안에 들어오는 단어가 발견되면 리턴 하게된다. 논문 저자에 따르면 이러한 알고리즘은 렉시콘 크기 $|D|$ 에 대해 $O(log(|D|))$ 효율성을 가지게 된다.
 |
|---|
| Fig 5. Burknard-Keller Tree 구조 예시 |
모델 성능
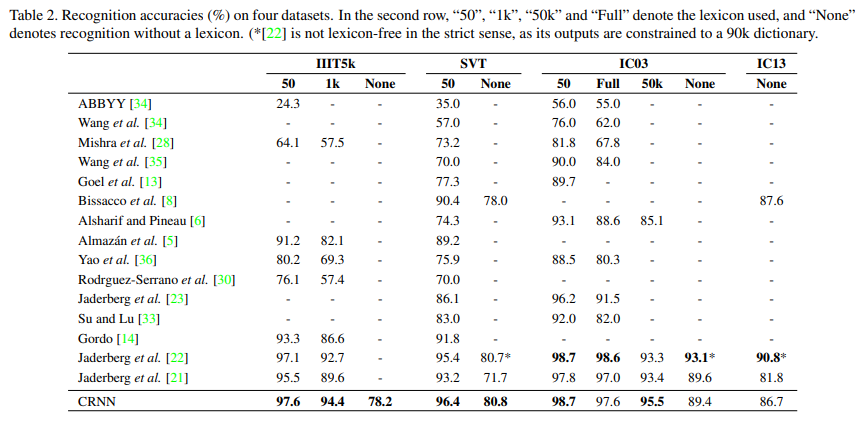
IIIT5k, SVT, IC03, IC13 4개 데이터셋에 비해 2015년 당시 최신 모델과 견줄만한 성능을 기록했다. 또한 비언어 문제인 악보 인식 또한 기존 모델보다 월등한 성능을 보여 모든 시퀀스 인식 분야에 적용될 수 있음을 시사했다.
 |
|---|
| Fig 6. CRNN 모델의 성능 비교 |