Introduction
- ELMo 는 2018년 공개된 워드 임베딩 방법론이며, GloVe, Word2Vec 등 기존 여러 임베딩 방식이 문맥을 파악하지 못하는 단점을 보완하고자 설계되었다.
- 예시로 River Bank (강둑) 와 Bank Account (은행 계좌) 라는 단어에서 Bank 는 전혀 다른 의미를 가지지만, 문맥을 파악하지 못하는 임베딩 기법은 Bank 에 동일한 벡터를 부여함으로 NLP 성능이 떨어질 수 밖에 없음.
Word2Vec
- ELMo 의 등장 배경을 이해하기 위해선 2014년 공개 후 한동안 널리 사용되었던 Word2Vec 모델을 이해할 필요가 있다.
- 하단의 예시는 몇 가지의 Word2Vec 알고리즘 중 가장 널리 활용된 방식인 Skipgram 버전에 대한 소개.
 |
|---|
| Fig 1. Word2Vec 피처 설계 |
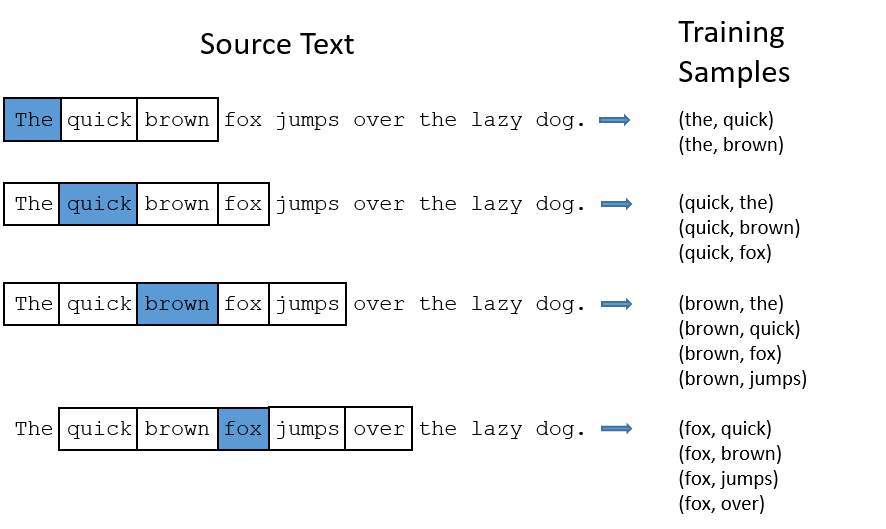
- 임의로 설정된 컨텍스트 사이즈 (상단 예시의 경우 5) 를 활용해, 특정 단어 $X$ 가 가운데에 위치해 있을때 함께 등장한 단어 $Y$ 를 피처로 설계한다.
- 문장 별로 한개의 $X$ 에 대해 복수의 $Y$ 가 추출되고, 문장이 여러개 활용되기 때문에 $X$ 와 $Y$ 의 관계에 대한 통계 정보를 얻을 수 있다. (예. $X$ 값 “the” 에 대한 $Y$ 값 “quick”, “brown”)
 |
|---|
| Fig 2. Word2Vec 신경망 모델 |
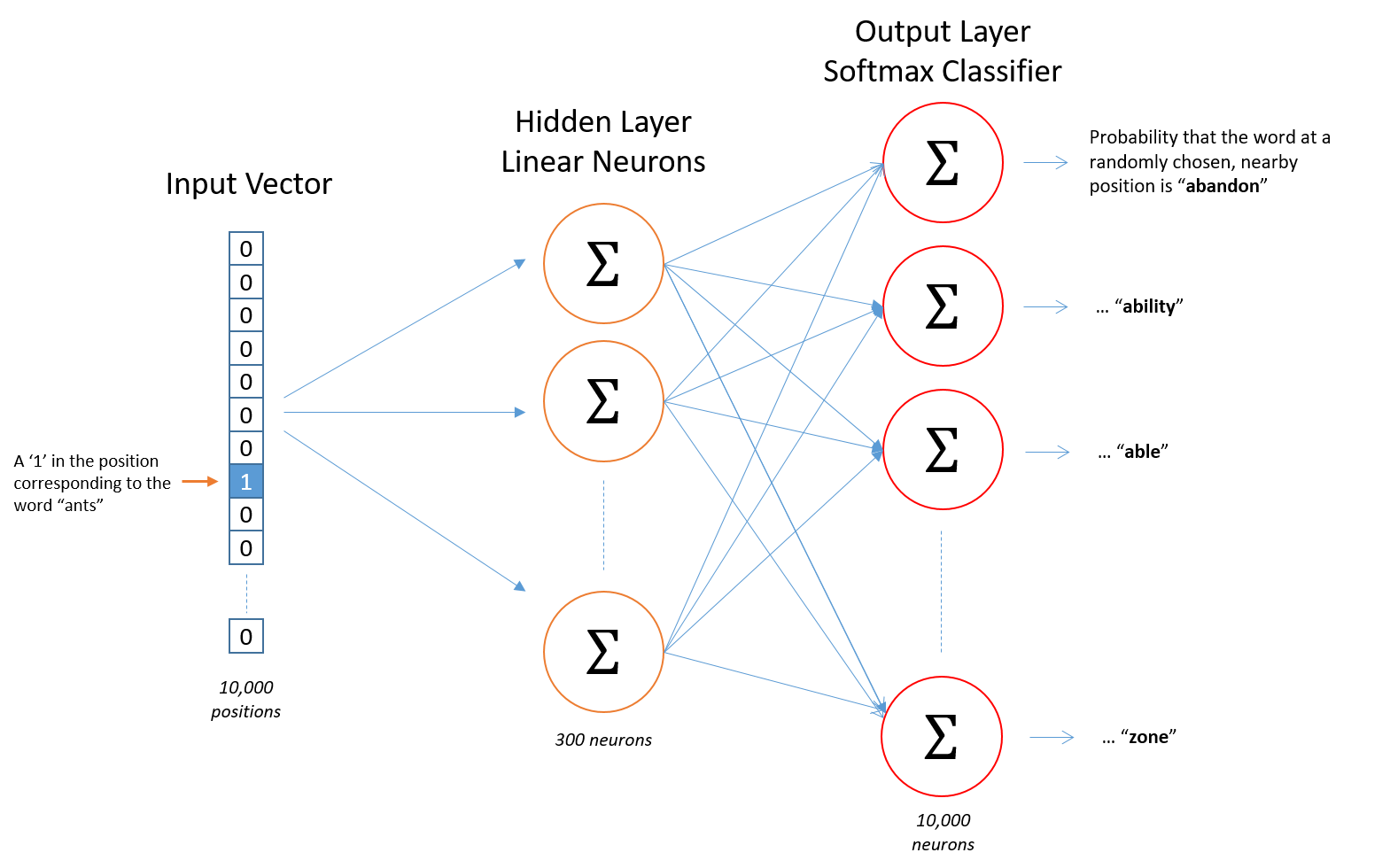
- 이렇게 추출된 데이터셋은 1개의 hidden layer 를 가진 작은 신경망 모델에 학습된다. 모델 구조는 10,000 사이즈의 벡터로 one-hot encode 된 인풋 $X$ 에 대해 동일한 사이즈로 one-hot encode 된 아웃풋 $Y$ 에 확률값을 부여하는 것.
- 모델의 hidden layer 는 300개의 뉴런으로 구성되어 있으며, 학습이 끝난 hidden layer 는 그대로 단어의 피처로 활용된다.
 |
|---|
| Fig 3. Word2Vec 임베딩의 의미론적 (semantic), 구문론적 (syntactic) 관계 |
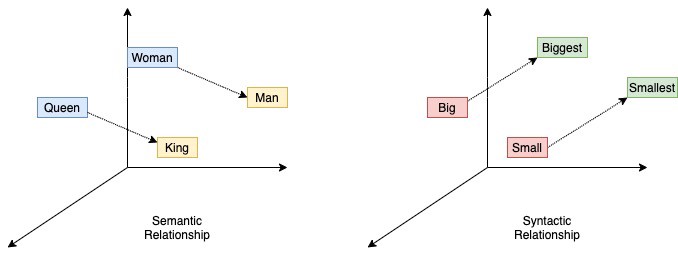
- 이렇게 추출된 임베딩이 실제 단어의 의미와 연관성을 가진다는 근거는 임베딩 벡터 간의 관계와 실제 단어 간의 관계가 유사성을 가진다는 점. 대표적인 예시로 “Queen” 과 “King” 이라는 단어 간 벡터의 차이값은 “Woman” 과 “Man” 이라는 단어 간 벡터의 차이값과 유사하다.
- Word2Vec 모델이 특히 널리 활용된 이유는 이와같이 추출된 단어 임베딩이 LSTM 과 같은 Sequence 모델의 인풋으로 활용될 수 있었다는 점. 이로 인해 Sequence 모델은 단어의 의미를 유추하기 보다, 문장 내 단어 간 관계를 파악하는 것으로 활용 목적을 좁힐 수 있었다.
Contextual Word Embedding
- 이렇듯 발전되어 온 워드 임베딩 기법에 ELMo 가 기여한 부분은 문맥에 기반한 단어 임베딩을 가능하게 했다는 점이다. 상기된 예시인 River Bank (강둑) 와 Bank Account (은행 계좌) 를 생각하면 됨.
- 문장에 기반한 단어의 임베딩은 Word2Vec 의 예시와 같이 사전에 생성될 수 없으며, 사전 학습된 모델을 통해 생성되어야 한다. 이러한 기법은 CoVe, ULMFit 등 ELMo 등장 이전에 시도되었지만, ELMo 가 중요한 이유는 State-of-the-Art 성능을 기록했기 때문.
ELMo
- ELMo 를 구성하는 주요 요소는 크게 (1) 캐릭터 단위의 단어 representation (2) 양방향 LSTM 네트워크 (3) 언어 모델 학습 과정을 들 수 있다.
Character-based word representations
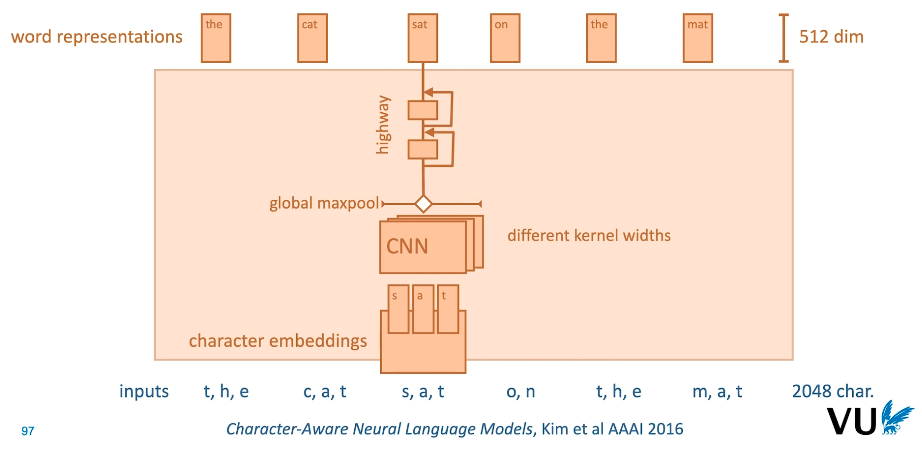 |
|---|
| Fig 4. Character CNN Architecture |
- 우선 문장의 개별적인 단어는 (sat) 더 작은 단위인 character 로 분할된다 (s, a, t). 이후 각 character 는 고유한 임베딩 벡터로 변환. 따라서 한 개의 단어는 character 레벨 임베딩 벡터로 구성된 매트릭스로 변형되며, 이는 다양한 kernel width 를 가진 CNN 레이어를 통해 처리된다.
- 각 CNN 레이어의 아웃을 하나의 채널로 합친 후 maxpooling 적용.
- Maxpooling 아웃풋은 두 개의 linear layer 에 연결되며, 각 linear layer 는 residual connection 과 유사한 highway connection 을 통해 연결되어 있다 (차이점은 highway connection 은 모수를 가진다는 점).
- 최종 linear layer 의 아웃풋은 1차적인 word representation 의 기능을 수행하며, 512 사이즈를 가짐.
- Character representation 의 장점은 오타와 같이 실제 상황에서 발생 가능한 단어를 유연하게 다룰 수 있다는 점.
Bidirectional LSTM structure
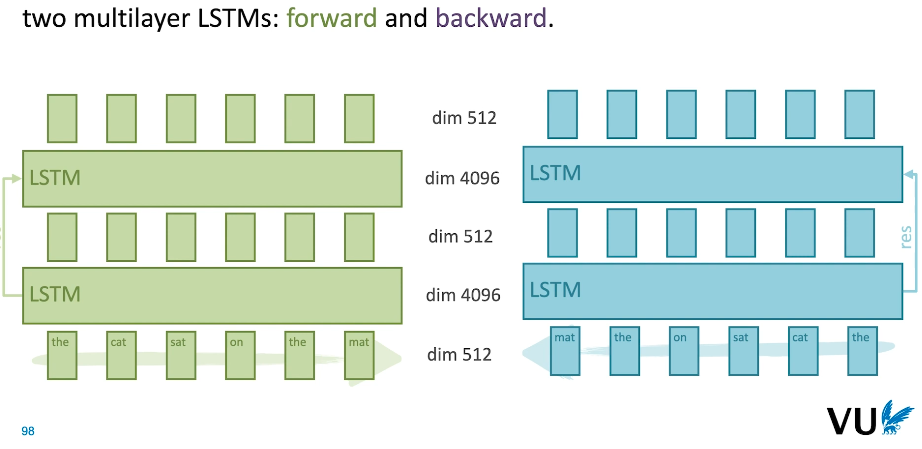 |
|---|
| Fig 5. Bidirectional LSTM Architecture |
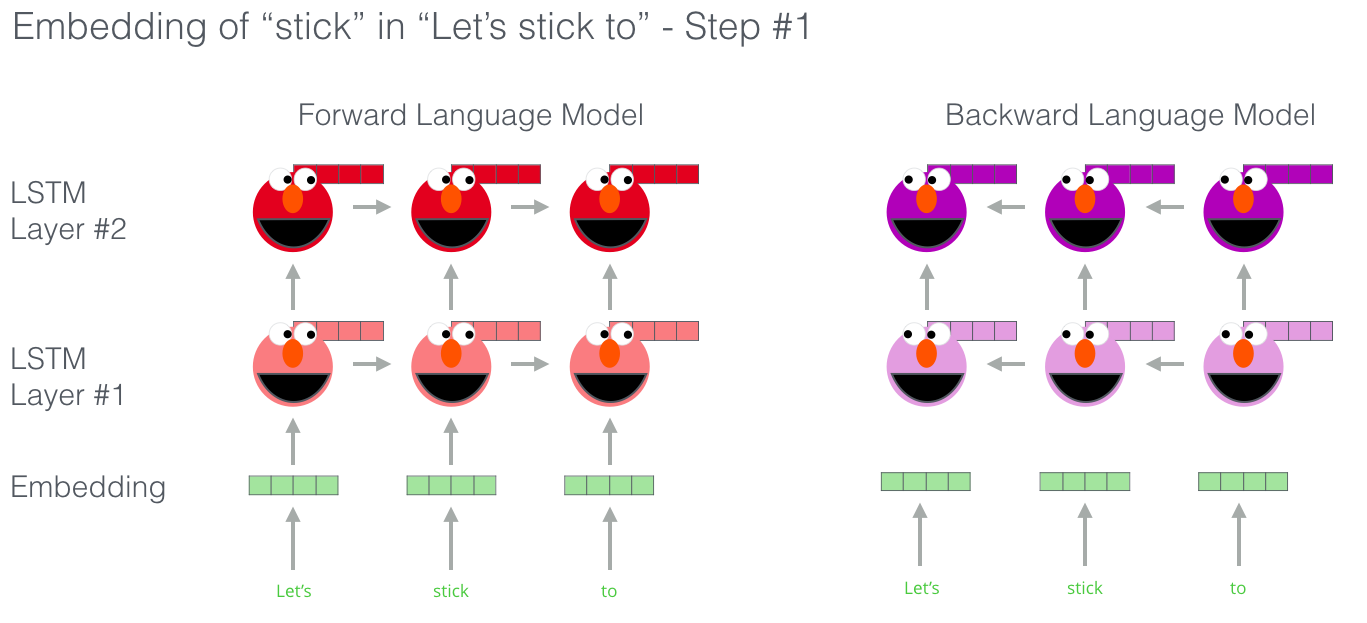
- 문맥을 파악하기 위해 ELMo 는 RNN 기법을 활용하며, 서로 다른 진행 방향을 가진 두개의 LSTM 모델을 적용.
- 진행 방향이 다르기 때문에 하나의 임베딩은 단어의 왼편에 속한 문맥을, 또 하나의 임베딩은 단어의 오른편에 속한 문맥을 파악하는 역할을 수행한다.
Pre-trained as a language model
- 언어 모델이란 특정 단어나, character 배열에 확률값을 부여하는 통계 모델이다. 예를 들자면 “Congratulations you have won a prize” 라는 영문장이 발생할 확률을 각 단어들의 조합이라는 관점에서 계산하는 것.
- 이를 수식으로는 다음과 같이 표현할 수 있다.
$$P(W_1 = Congratulations, W_2 = you, W_3 = have, W_4 = won, W_5 = a, W_6 = prize)$$
- 하지만 단어의 조합이란 무한의 영역이며, 실제 데이터를 기반으로 이와 같은 통계치를 직접적으로 얻는 것은 불가능한 작업이다. 때문에 다음과 같은 조건부 확률의 규칙를 활용하게 된다.
$$P(x, y) = P(x|y)P(y)$$
- 4개의 단어가 등장하는 문장에 대한 확률값 $P(W_1, W_2, W_3, W_4)$ 는 조건부 확률을 규칙을 적용해 다음과 같이 확장하는 것이 가능.
$$P(W_1, W_2, W_3, W_4)$$
$$= P(W_1, W_2, W_3 | W_4)P(W_4)$$
$$= P(W_1, W_2 | W_3, W_4)P(W_3 | W_4)P(W_4)$$
$$= P(W_1 | W_2, W_3, W_4)P(W_2 | W_3, W_4)P(W_3 | W_4)P(W_4)$$
- 위와 같은 문제의 재정의에 따라, 이제 우리가 계산하고자 하는 값은 이전에 등장한 모든 단어에 비추었을때 특정한 단어가 발생할 확률로 정의할 수 있다. 이러한 조건부 확률을 계산할 수 있다면, 각 단어의 조건부 확률을 곱해줌으로 전체 문장의 확률값을 계산하는 것이 가능해지는 것.
- 이를 로그로 치환할 시, 조건부 확률의 곱을 단순한 합계로 변형하는 것이 가능하다.
$$\text{log} P(\text{sentence}) = \Sigma_{\text{word}} log P(\text{word} | \text{all words that came before})$$
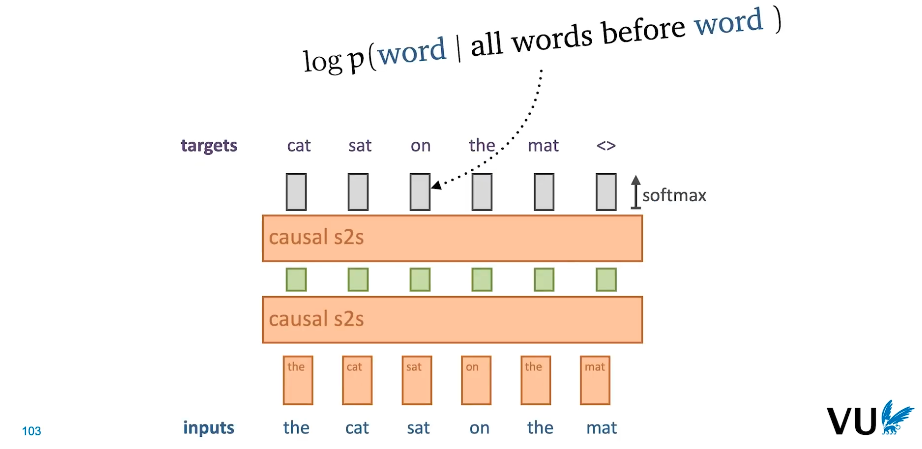 |
|---|
| Fig 6. Language Modeling in LSTM |
- 따라서 위와 같이 다음 단어를 예측하는 시퀀스 모델은 언어 모델의 조건부 확률을 구하는 작업을 수행한다고 볼 수 있으며, 최종 레이어 내 확률 부여를 위해서 softmax 함수가 적용된다.
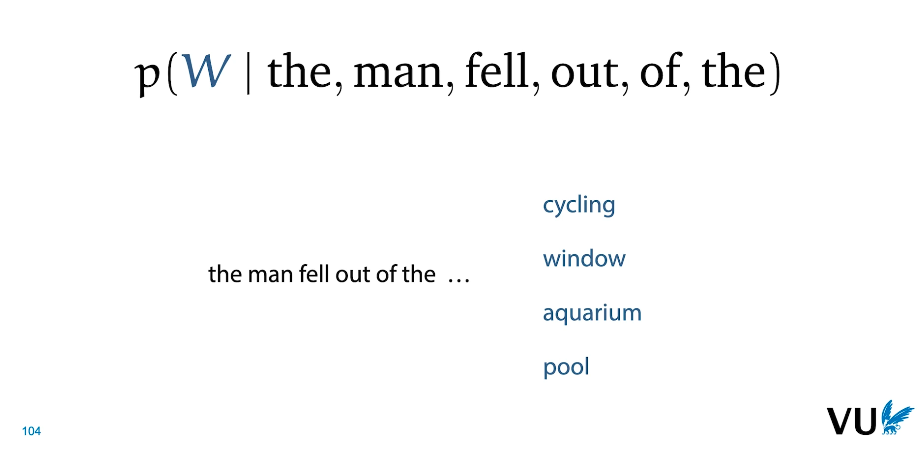 |
|---|
| Fig 7. Language Modeling As a Task |
- 이론적인 부분을 간단하게 짚고 넘어갔지만, 위와 같은 상황에서 단어 별로 알맞은 확률값을 부여하기 위해서는 상당한 수준의 사전 지식을 요구한다.
- 등장하는 4개 단어 중 cyclcing 을 제외한 단어는 모두 문법적으로 적법할 수 있지만, window > aquarium > pool 순서의 확률값을 부여한다는 것은 각각 단어에 대한 특성을 이해한다는 것을 의미.
- 이러한 상황에서 완벽히 확률값을 부여하는 모델을 AI Complete 라 지칭할 수 있으며, 이를 위해서는 common sense, context 에 대한 인간 수준의 이해를 필요로 한다.
ELMo Architecture
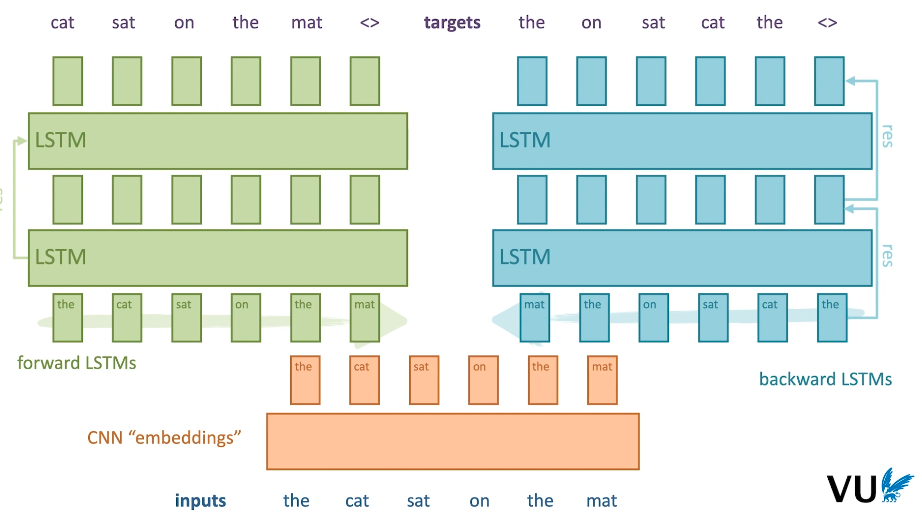 |
|---|
| Fig 8. ELMo Architecture |
- 상기된 컴포넌트를 바탕으로 구축된 ELMo 모델 구조의 다이어그램이다. Char-CNN 모델이 생성한 최초 단어 임베딩을 기준으로 2개의 LSTM 모델을 언어 모델로서 학습시키는 것.
- 최종 단어 임베딩은 다음과 같이 정의된다.
$$ e_k = \gamma i h_K^{init} + \gamma \sum_{j=0}^{L} f_j h_{k,j}^{forward} + \gamma \sum_{j=0}^{L} b_j h_{k,j}^{backward} $$
- 위 방정식에서 등장하는 $h^{init}$, $h^{forward}$, $h^{backward}$ 는 각각 Char-CNN, Forward LSTM, Backward LSTM 의 아웃풋이며, 이외 변수를 통해 finetuning 을 지원하는 것.
- 특히 $\gamma$ 는 Weight 파라미터로 부여된 태스크에 따라 서로 다른 가중치를 부여하게 된다.