Introduction
Background
- 최근 NLP 분야의 성장은 웹에서 확보할 수 있는 수많은 unlabeled 텍스트를 활용한 전이 학습의 효율성에 기인.
- 이러한 학습은 주로 self-supervised 형식으로 이루어지며, 빈칸 채우기 등의 태스크를 수행하는 것을 1차적인 과제로 삼음.
- 방대한 데이터를 기반으로 사전 학습을 마친 모델은 별도 데이터를 활용해 finetune 될 수 있으며, 이는 보유한 데이터만으로 모델을 학습하는 것 보다 월등히 나은 성능을 보임.
- 2018 년 부터 GPT, ULMFit, ELMo, BERT 등 다양한 전이학습의 성공 사례가 보고되었으며, 2019 년도에는 XLNet, RoBERTa, ALBERT, Reformer, MT-DNN 등 보다 개선된 방식이 개발.
- 발전 속도가 워낙 빠르기 때문에, 어떠한 개선점이 유효하고, 어떠한 모델의 조합이 효과적인지를 판단하기 어려운 면이 존재한다.
T5
- 본 논문에서는 가장 효과적인 전이 학습 방식을 평가하기 위한 비교 실험을 진행하였으며, 결과를 기반으로 T5 모델을 구축.
- 또한 새로운 사전 학습 데이터셋인 Colossal Clean Crawled Corpus (C4) 를 공개했다.
- C4 데이터를 기반으로 학습된 T5 모델은 공개 당시 state-of-the-art 성능을 기록했으며, 또한 다양한 태스크에 접목될 수 있는 유연성을 가지고 있다.
- 코드. 사전 학습 모델. Colab Notebook.
A Shared Text-To-Text Framework
- T5 를 정의하는 핵심적인 요소는 모든 NLP 태스크를 text-to-text 포맷으로 통일시켰다는 점. 이는 BERT 처럼 클래스 레이블 등으로 한정된 아웃풋을 출력하는 모델과 차별되는 포인트이다.
- text-to-text 프레임워크는 동일한 모델, 손실 함수, 하이퍼파라미터를 활용해 모든 NLP 태스크 수행이 가능하며, 이는 기계 번역, 문서 요약, 질답, 분류, 회귀 (출력값을 텍스트로 변환) 등의 태스크를 포함한다.
 |
|---|
| Fig 1. Diagram of text-to-text framework |
A Large Pre-training Dataset (C4)
- 전이 학습의 핵심적인 요소는 사전 학습에 사용되는 unlabeled 데이터셋이다.
- 사전 학습 수준에 따른 성능 편차를 정확하게 측정하기 위해서는 질이 높고, 다양성이 높으며, 규모가 큰 데이터를 필요로 하는데 연구진은 이러한 조건을 모두 충족하는 데이터셋이 존재하지 않는다고 판단.
- 위키피디아 데이터셋은 품질이 높지만, 규모가 크지 않으며 스타일이 획일적. Common Crawl 데이터셋은 규모는 크지만 데이터의 품질이 낮다.
- 이러한 조건을 모두 충족하는 데이터셋을 구축하기 위해 연구진은 기존 Common Crawl 데이터셋을 정제한 C4 데이터셋을 구축하였으며, 이는 위키피디아 데이터셋에 비해 약 100배의 규모를 가지고 있다.
- 적용된 정제 과정은 완성되지 않은 문장 제외, 중복 데이터 제외, offensive 혹은 noisy 한 데이터 제외 등.
A Systematic Study of Transfer Learning Methodology
- 연구진은 상기된 T5 프레임워크와 C4 데이터셋을 활용해 알려진 다양한 NLP 전이 학습 방법을 비교했다.
- Model Architectures : Encoder-Decoder 모델 구조는 대체로 Decoder-Only 구조에 비해 높은 성능을 보임.
- Pre-training Objectives : Fill-in-the-blank 스타일의 학습 목표가 가장 유연한 모델을 생성.
- Unlabeled Datasets : 최종 목적과 부합한 in-domain 데이터의 사전 학습은 도움이 되었으나, 사전 학습 데이터셋이 너무 작은 경우 over-fitting 문제 발생.
- Training Strategies : 멀티태스트 러닝은 사전 학습 후 전이 학습을 진행하는 방식과 유사한 성능을 낼 수 있지만, 각 태스크에 따른 학습 주기를 세밀하게 조정해야 함.
- Scale : 한정된 연산 자원 배분을 위해 적합한 모델 사이즈, 학습 시간, 앙상블 모델 수 등을 탐색.
Insights + Scale = State-of-the-Art
- 비교 분석을 통해 얻은 인사이트를 기반으로, TPU 를 활용한 모델 스케일링을 진행. 최종 모델은 약 11 billion (110 억) 개의 파라미터를 가지고 있다.
- GLUE, SuperGLUE, SQuAD, CNN/Daily Mail 벤치마크 등에서 당시 가장 높은 성능을 기록.
- 특히 주목할 점은 SuperGLUE 에서 인간과 유사한 점수를 기록했다는 것인데, 해당 데이터셋은 고의적으로 머신러닝으로 해결하기 어려운 데이터를 주로 포함.
Extensions
- T5 는 논문에 언급된 것 이외에도 많은 태스크에 쉽게 적용할 수 있다는 장점을 가지고 있다.
- 다음 섹션에서는 Closed-Book Question Answering 과 변측적인 blank-size 에 대한 fill-in-the-blank 과제 적용 사례를 설명.
Closed-Book Question Answering
- 지문과 질문을 인풋으로 받았을 때, 질문에 대한 적절한 답변을 생성하는 과제.
- 예시적으로 Hurricane Connie 에 대한 위키피디아 지문과 Hurricane Connie 는 언제 발생했는가? 라는 질문을 받았을때 모델은 “August 3rd, 1955” 와 같이 적절한 답변을 아웃풋해야 한다.
- 이러한 과제를 위해 설계된 Stanford Question Answering Dataset (SQuAD) 에서 T5 는 당시 가장 높은 성능을 기록.
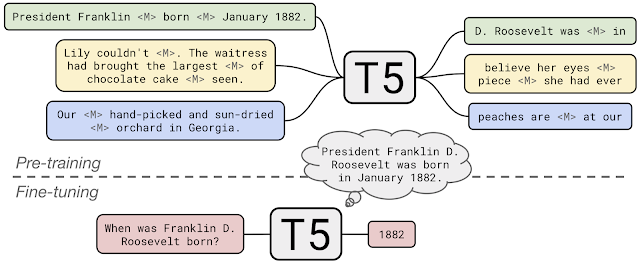 |
|---|
| Fig 2. T5 learns to fill in dropped-out spans of text |
- Colab 데모와 논문에서 연구진은 컨텍스트 없이 모델이 적절한 답변을 할 수 있는지를 테스트 하였으며, TriviaQA, WebQuestions, Natural Questions 데이터셋에서 원문 그대로의 답변을 제시한 비율이 각각 50.1%, 37.4%, 34.5% 를 기록했다.
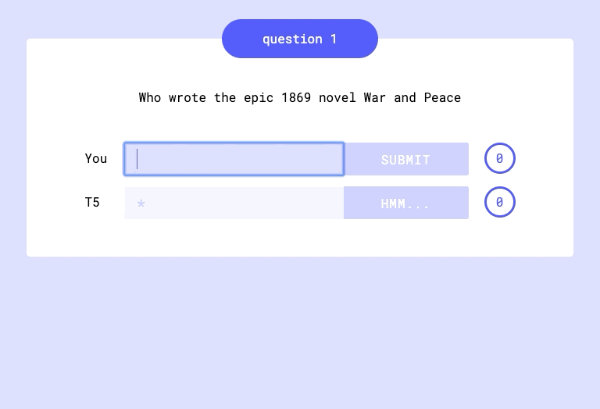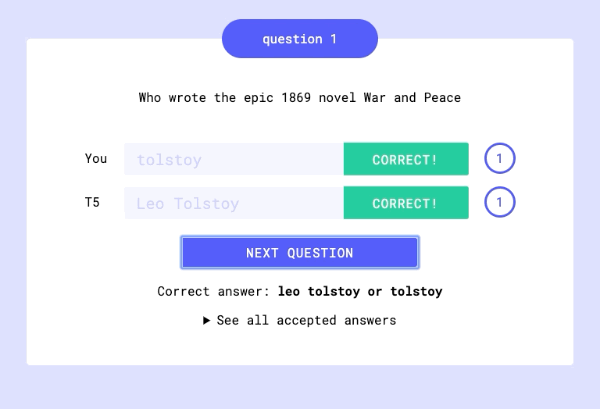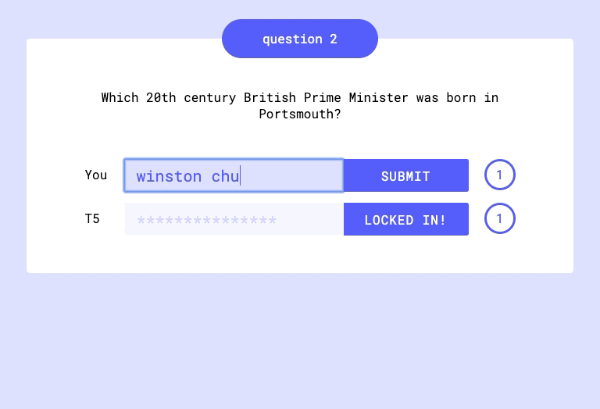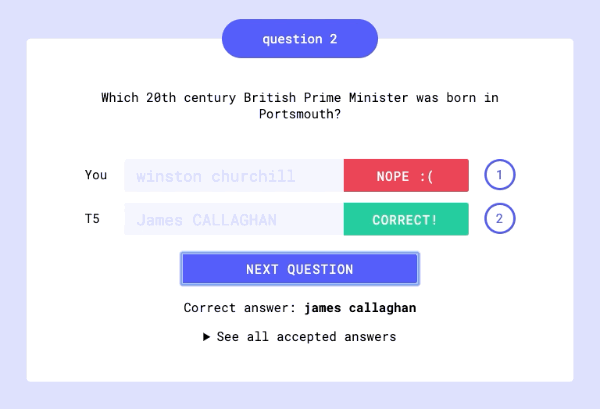 |
|---|
| Fig 3. Question answering UI |
Fill-in-the-Blank Text Generation
- GPT-2 와 같은 LLM 은 실제 사람이 작성한 것과 유사한 텍스트를 생성하는 작업에 매우 탁월한 성능을 보인다. 이는 Talk To Transformer 와 AI Dungeon 과 같은 적용 사례로 까지 이어짐.
- 이는 fill-in-the-blank 과제에서 빈칸이 가장 뒷편에 있는 경우라고 해석할 수 있으며, 해당 과제는 T5 의 사전 학습 과제와 일치함.
- 연구진은 빈칸에 들어갈 단어 수를 제시하고, 모델이 이를 채워넣는 과제를 실험하였으며 사실적으로 생성된 텍스트를 확인함.