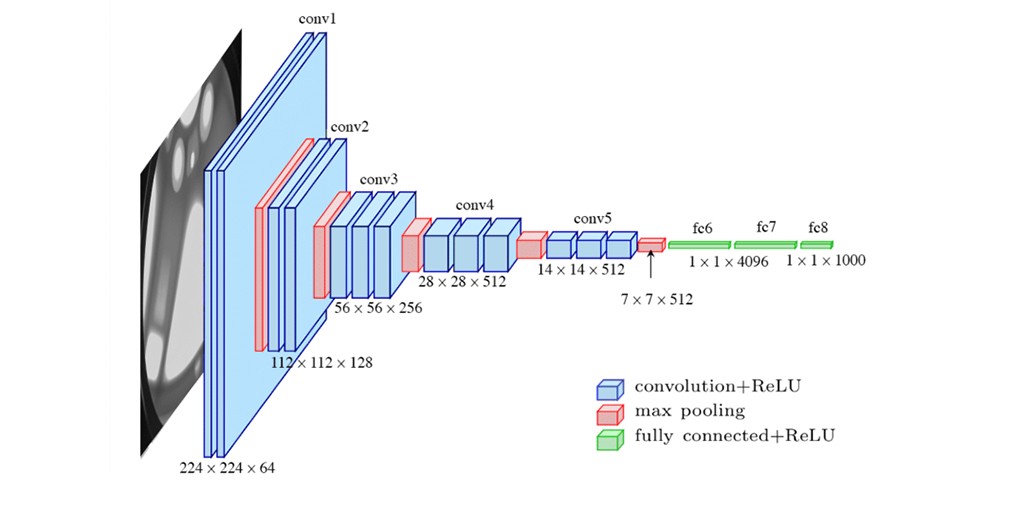
소개
컨볼루션 필터를 아주 작은 사이즈 (3x3) 로 고정해, 당시로서는 획기적으로 깊은 16~19 레이어 CNN 을 구축해 네트워크의 깊이가 신경망 모델의 성능에 끼치는 영향을 연구한 교과서적인 논문이다. 저자는 이러한 인사이트를 바탕으로 2014년 ImageNet Challenge 우승 모델을 구축했는데, 불과 2년전 우승 모델인 AlexNet 이 8 레이어로 구축됐던 것을 감안하면 네트워크의 깊이가 빠르게 상승한 것을 볼수있다 (2015년 대회에선 152 레이어의 ResNet이 등장). 해당 글에서는 네트워크의 하이퍼파라미터, 세부 구조에 대한 내용을 제외한 핵심 내용만을 전달하고자 하며, 본문은 여기에서 확인할 수 있다.
네트워크 구조
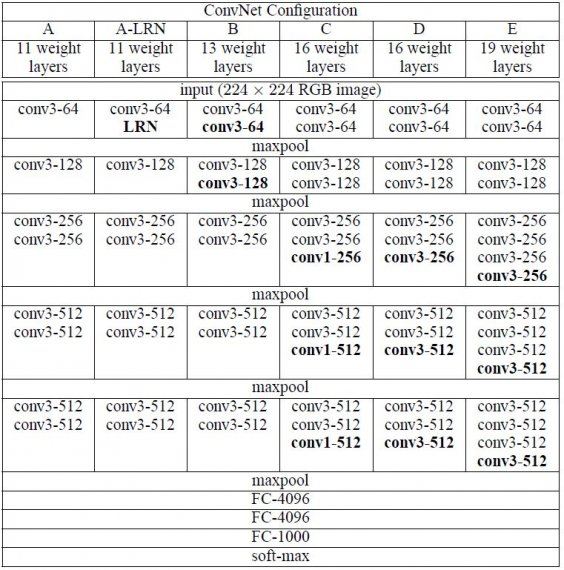 |
|---|
| Fig 1. 6개 VGGNet 모델 아키텍처 |
네트워크 깊이 변화에 따른 성능의 차이를 검증하기 위해 논문에 등장하는 6개 모델은 모두 동일한 세팅을 가지고있다. 언급했던 필터 (커널) 사이즈가 3x3 인 이유는 상하좌우 픽셀을 고려할 수 있는 최소 크기이기 때문이며, 필터가 작을수록 다음 레이어에서 정보유실이 적다는 점을 이용해 신경망의 깊이를 키우는 목적을 가지고 있다. 컨볼루션 레이어 이후에 FC 레이어가 뒤따르고, 마지막 softmax 레이어를 통해 분류 예측을 수행하는 전통적인 CNN 구조를 계승하고있다.
A 부터 E 까지의 알파벳 순으로 네트워크의 깊이와 복잡도가 증가하고, 이에 불구하고 작은 필터 사이즈로 인해 이전에 등장한 네트워크와 비교해 가중치 개수가 크게 차이나지 않는다. 네트워크 구조에 대해 언급할만한 부분은 다음과 같다.
- AlexNet 에 등장했던 LRN 레이어를 모델 A에 적용 후, 저자는 LRN 이 모델 성능에 크게 기여하지 않는다고 판단해 이후 모델에 LRN 을 적용하지 않는다.
- 모델 C 는 모델 B 에 1x1 필터를 추가한 것이다. 인/아웃 채널 수가 같기 때문에 channel reduction 역할은 수행하지 않고, 단순한 activation 레이어의 추가라고 보는 것이 타당하다.
3x3 컨볼루션 필터
본 논문 이전에 등장한 CNN 구조는 대부분 7x7, 5x5 등의 컨볼루션 필터 (커널) 를 사용하며, 초기 레이어에서 상대적으로 더 큰 필터 사이즈를 적용한다 (AlexNet 의 경우 11x11 w/ stride 4). 이에 반해 VGGNet 은 네트워크는 필터 사이즈를 3x3 으로 최소화하여 네트워크의 깊이를 19 레이어까지 끌어올렸다. 언급했듯 이는 작은 필터 사이즈가 레이어 간 정보유실을 최소화하기 때문인데, 논문의 저자는 이에 대한 부연 설명으로 7x7 필터가 적용된 한개 레이어가 3x3 필터가 적용된 세개 레이어와 사실상 같은 기능을 한다는 점을 언급한다.
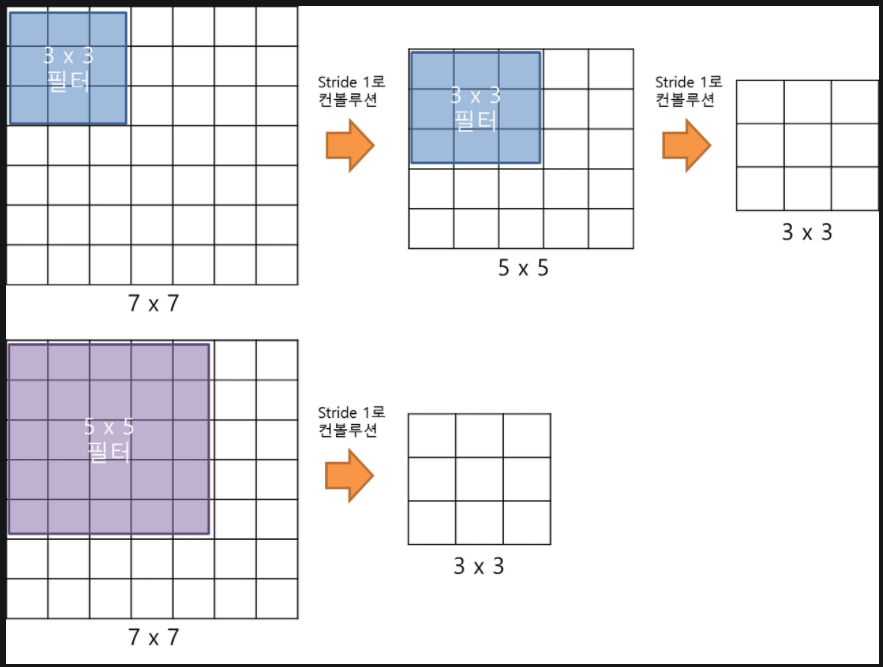 |
|---|
| Fig 2. 예시는 5x5 필터 레이어 1개와 3x3 필터 레이어 2개 비교 |
그렇다면 VGGNet 과 같이 필터 사이즈를 줄이고, 레이어 수를 늘린 경우엔 어떤 이점이 있을까? 첫째로 ReLU (혹은 다른 activation) 레이어가 여러번 적용되기 때문에 네트워크가 가장 핵심적인 정보만 추려내도록 유도하는 것이 가능하다. 둘째로 학습이 필요한 파라미터 수가 상당히 감소하게된다. 인풋/아웃풋의 채널수가 모두 C 로 동일하다 가정했을 때, 3x3 필터로 구성된 3 레이어 네트워크는 $3^2 C^2 = 27 C^2$ 파라미터를 가지게되는 반면, 7x7 필터로 구성된 1 레이어 네트워크는 $7^2 C^2 = 49 C^2$ 파라미터를 가지게 됨으로 전자 대비 약 181% 의 파라미터로 구성된다. 이에 따라 VGGNet 은 학습속도 개선, 과적합 방지 효과를 누리게 된다고 저자는 결론짓는다.
모델 학습 과정
전이 학습
깊어진 네트워크의 복잡성으로 인해 적절한 초기 가중치 세팅 (weight initilization) 없이는 네트워크 학습이 어려운 문제가 발생한다. 이를 해결하기 위해 저자는 레이어 수가 가장 적은 A 모델을 pre-train 모델로 활용하여, 더 깊은 모델 학습 시 레이어를 이어 붙이고, 이후 fine-tuning 을 진행한다.
이미지 리사이징
네트워크는 기본적으로 인풋 이미지에서 랜덤하게 크롭된 224x224 이미지를 처리한다. 이러한 인풋 크롭이 진행되기 전, 이미지는 가로세로 비율이 유지되는 상태에서 리스케일되는데 (isotropical rescale - 1024x512 이미지가 512x256 사이즈로 리스케일 되어 2:1 비율을 유지하는 식), 리스케일 후 가로세로 중 더 작은 면의 이미지 크기를 학습 시 $S$, 테스팅 시 $Q$ 라 칭한다.
- 학습은 $S$ 를 256 또는 384로 고정하는 single-scale 방식, 혹은 이미지 별로 256 과 512 사이 랜덤한 숫자를 부여하는 multi-scale 방식으로 나뉘어진다.
- 테스팅은 $Q$ 를 256 또는 384로 고정하는 single-sclae 방식, 혹은 224, 256, 288, 416, 512 중 세가지 숫자에서 랜덤하게 부여하는 multi-scale 방식으로 나뉘어진다.
- 학습과 테스팅은 single/multi-sclae 방식의 조합 (single-multi, multi-single 도 가능) 으로 이루어진다.
 |
|---|
| Fig 3. Multi-Scale 리사이징 예시 |
FC layer -> Conv. layer
모델 뒷단에 위치한 FC (Fully Connected) 레이어는 파라미터 수가 고정되어있기 때문에 학습에 활용된, 고정된 사이즈의 이미지만 처리할 수 있다. 때문에 저자는 학습에 활용된 FC 레이어를 컨볼루션 레이어로 변경하여, 각자 다른 크기의 최종 아웃풋에서 평균치를 구하는 방식으로 (Averaged Sum-Pooling) softmax 레이어를 연산한다. 구체적인 레이어 변경 방식과 Sum-Pooling 방식은 논문에 언급되어있지 않으나, 다음 이미지를 참고하면 대략적인 접근법이 이해될 것이다.
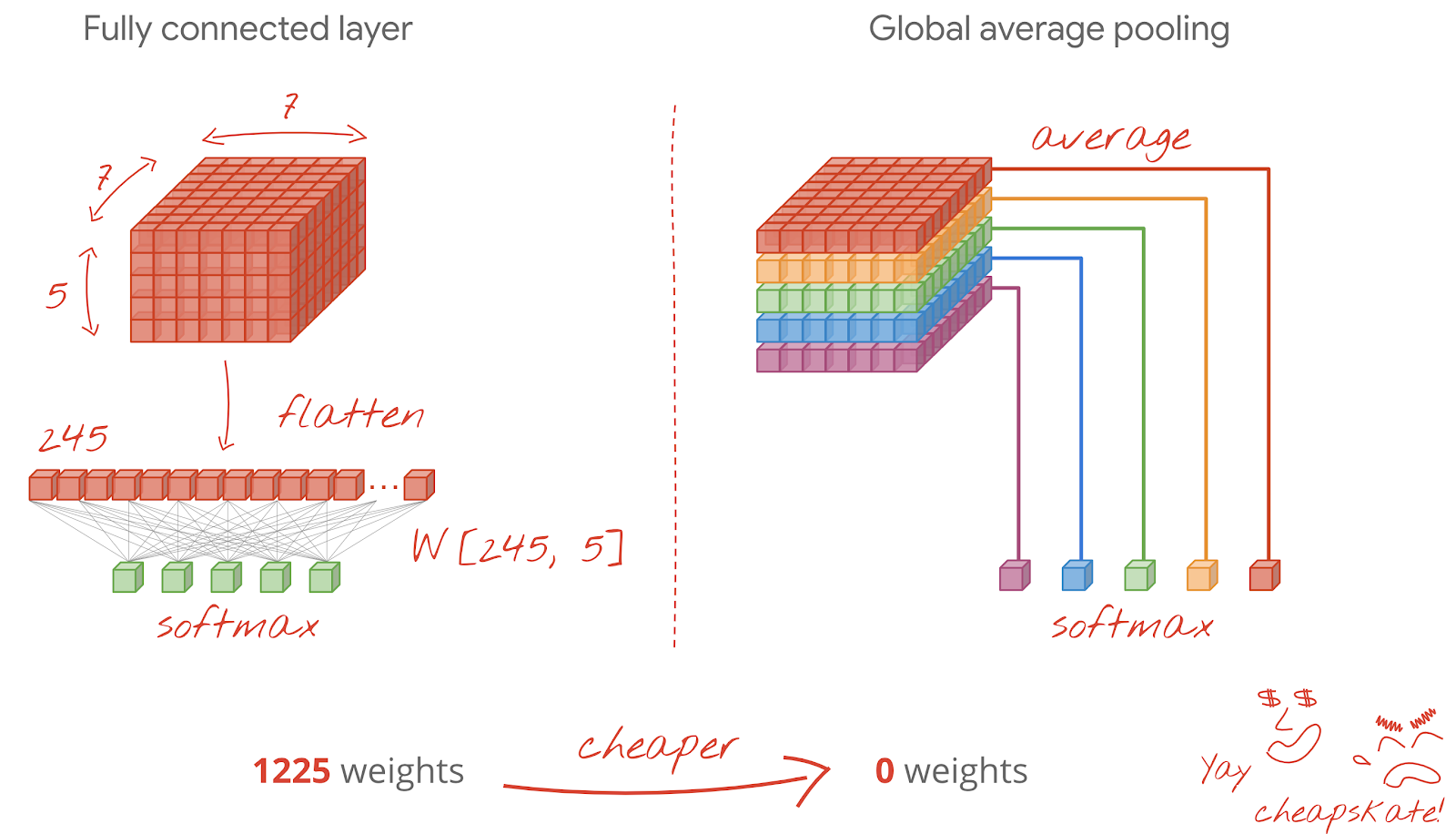 |
|---|
| Fig 4. Conv. layer 변환 예시 |
모델 성능
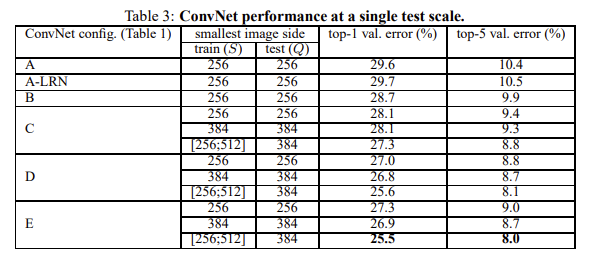 |
|---|
| Fig 5. Single Test Scale 성능 비교 |
여기서 top-1, top-5 error rate 란 AlexNet 과 동일하게 가장 높은 확률로 예측된 1개, 5개 레이블 중 실제 레이블이 포함되어 있는 비율이다. 모델의 깊이가 깊어질 수록 성능이 증가하며, LRN 레이어가 성능에 오히려 악영향을 끼치는 점을 확인할 수 있다.
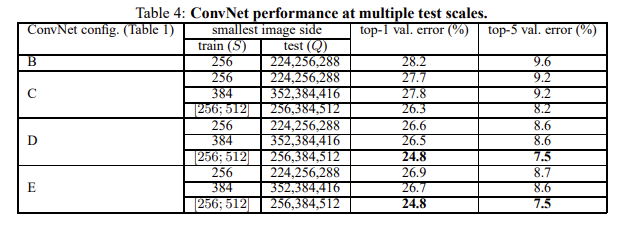 |
|---|
| Fig 5. Multiple Test Scale 성능 비교 |
저자는 모델의 성능은 깊이에 비례하며, 동일한 깊이라도 1x1 convolution 레이어보다 3x3 convolution 레이어를 구성하는 것이 성능에 도움이 된다는 점을 발견한다. 또한 test 이미지 사이즈가 고정된 경우, 랜덤하게 선택된 경우 모두 학습 시 랜덤한 이미지 사이즈를 사용한 경우에 모델 성능이 가장 좋았으며, 저자는 이러한 방식이 데이터 증강 역할을 수행해 이미지들에 대한 통계치를 얻는 것에 도움이 되었다고 결론짓는다.
VGGNet 은 2014년 ILSVRC 챌린지에서 GooGLeNet 다음으로 2등을 차지했다. 마지막으로 저자는 VGGNet 이 다양한 task 와 데이터셋에서 높은 범용성을 보인다는 점을 언급한다.